翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ベクター検索の機能と制限
ベクトル検索が利用可能なリージョン
ベクトル検索が有効な MemoryDB 設定は、R6g, R7g、T4g ノードタイプでサポートされており、MemoryDB が利用可能なすべての AWS リージョンで使用できます。
既存のクラスターは、検索を有効にするように変更することはできません。ただし、検索が無効なクラスターのスナップショットから検索対応クラスターを作成できます。
パラメトリック制限
次の表は、プレビューにおけるさまざまなベクトル検索項目の制限を示しています。
| Item | 最大値 |
|---|---|
| ベクトルの次元の数 | 32768 |
| 作成できるインデックスの数 | 10 |
| インデックス内のフィールドの数 | 50 |
| FT.SEARCH および FT.AGGREGATE TIMEOUT 句 (ミリ秒) | 10000 |
| FT.AGGREGATE コマンドのパイプラインステージの数 | 32 |
| FT.AGGREGATE LOAD 句のフィールドの数 | 1024 |
| FT.AGGREGATE GROUPBY 句のフィールドの数 | 16 |
| FT.AGGREGATE SORTBY 句のフィールドの数 | 16 |
| FT.AGGREGATE PARAM 句のパラメータの数 | 32 |
| HNSW M パラメータ | 512 |
| HNSW EF_CONSTRUCTION パラメータ | 4096 |
| HNSW EF_RUNTIME パラメータ | 4096 |
[Scaling limits](スケーリング履歴)
現在、MemoryDB のベクトル検索は単一のシャードに制限されており、水平方向のスケーリングはサポートされていません。ベクトル検索は、垂直スケーリングとレプリカスケーリングをサポートしています。
オペレーションの制限
インデックスの永続化とバックフィル
ベクトル検索機能は、インデックスの定義とインデックスの内容を保持します。つまり、ノードの起動または再起動を引き起こすオペレーションリクエストまたはイベント中に、インデックス定義とコンテンツは最新のスナップショットから復元され、保留中のトランザクションはマルチ AZ トランザクションログから読み取られます。これを開始するには、ユーザーアクションは必要ありません。再構築は、データが復元されるとすぐにバックフィルオペレーションとして実行されます。これは、定義されたインデックスごとに FT.CREATE コマンドを自動的に実行するシステムと機能的に同等です。データが復元されると、アプリケーションのオペレーションのためにすぐにノードを使用できるようになりますが、これはインデックスバックフィルが完了する前である可能性が高いことに留意してください。これは、アプリケーションが再びバックフィルを認識できるようになることを意味します。例えば、バックフィルインデックスを使用した検索コマンドは拒否される可能性があります。バックフィルの詳細については、「ベクトル検索の概要」を参照してください。
インデックスバックフィルの完了は、プライマリとレプリカの間で同期されません。この同期の欠如は予期せずアプリケーションにとって認識可能になる可能性があるため、検索オペレーションを開始する前に、アプリケーションでプライマリとすべてのレプリカでバックフィルが完了したことを検証することをお勧めします。
スナップショットのインポート/エクスポートとライブ移行
RDB ファイル内に検索インデックスが存在する場合、そのデータの互換性のある転送可能性が制限されます。MemoryDB ベクトル検索機能で定義されるベクトルインデックスの形式は、別の MemoryDB ベクトル対応クラスターでのみ理解されます。また、プレビュークラスターの RDB ファイルは、MemoryDB クラスターの GA バージョンによってインポートできます。これにより、RDB ファイルのロード時にインデックスコンテンツが再構築されます。
ただし、インデックスを含まない RDB ファイルについては、このような制限はありません。そのため、エクスポート前にインデックスを削除することで、プレビュークラスター内のデータを、非プレビュークラスターにエクスポートできます。
メモリ消費
メモリ消費量は、ベクトルの数、ディメンションの数、M 値、およびベクトルに関連付けられたメタデータやインスタンス内に保存された他のデータなどのベクトル以外のデータの量に基づいています。
必要な合計メモリは、実際のベクトルデータに必要なスペースとベクトルインデックスに必要なスペースの組み合わせです。ベクトルデータに必要なスペースは、最適なメモリ割り当てのために、HASH または JSON データ構造内にベクトルを保存するために必要な実際の容量と、最も近いメモリスラブへのオーバーヘッドを測定して計算されます。各ベクトルインデックスは、これらのデータ構造に保存されているベクトルデータへの参照を使用し、効率的なメモリ最適化を使用して、インデックス内のベクトルデータの重複コピーを削除します。
ベクトルの数は、データをベクトルとして表す方法によって異なります。例えば、1 つのドキュメントを複数のチャンクに表現することを選択できます。各チャンクはベクトルを表します。または、ドキュメント全体を単一のベクトルとして表現することもできます。
ベクトルのディメンションの数は、選択した埋め込みモデルによって異なります。例えば、AWS Titan
M パラメータは、インデックス構築中に新しい要素ごとに作成された双方向リンクの数を表します。MemoryDB のデフォルト値は 16 ですが、これを上書きできます。高い M パラメータは、高いディメンションおよび/または高いリコール要件に対してより適しており、低い M パラメータは、低いディメンションおよび/または低いリコール要件に対してより適しています。M 値は、インデックスが大きくなるにつれてメモリの消費を増加させ、メモリの消費量が増加します。
コンソールエクスペリエンス内で、MemoryDB は、[クラスター設定でベクトル検索を有効にする] をチェックした後、ベクトルワークロードの特性に基づいて適切なインスタンスタイプを簡単に選択する方法を提供します。
サンプルワークロード
あるお客様が、内部財務ドキュメントに基づいたセマンティック検索エンジンの構築を希望しています。現在、1536 ディメンションの Titan 埋め込みモデルを使用して、ドキュメントごとに 10 ベクトルに分割され、非ベクトルデータが含まれない 100 万件の財務ドキュメントが保管しています。お客様は、M パラメータとしてデフォルト 16 を使用することにしました。
ベクトル: 100 万 * 10 チャンク = 1,000 万ベクトル
ディメンション: 1536
非ベクトルデータ (GB): 0 GB
M パラメータ: 16
このデータを使用して、お客様はコンソール内のベクトル計算ツールの使用ボタンをクリックし、パラメータに基づいて推奨されるインスタンスタイプを取得できます。
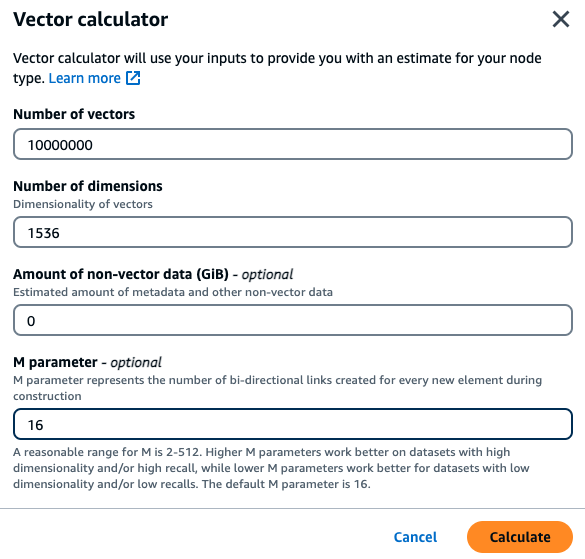

この例では、ベクトル計算ツールは、指定されたパラメータに基づいてベクトルを保存するために必要なメモリを保持できる最小の MemoryDB r7g ノードタイプ
上記の計算方法とサンプルワークロードのパラメータに基づくと、このベクトルデータの保存には 104.9 GB と単一のインデックスが必要です。この場合、使用可能なメモリが 105.81 GB であるため、db.r7g.4xlarge インスタンスタイプが推奨されます。次に小さいノードタイプは小さすぎて、ベクトルワークロードを保持できません。
各ベクトルインデックスは、保存されたベクトルデータへの参照を使用し、ベクトルインデックスにベクトルデータの追加のコピーを作成しないため、インデックスの消費スペースも比較的少なくなります。これは、複数のインデックスを作成する場合や、ベクトルデータの一部が削除され、HNSW グラフを再構築する場合にも非常に役立ちます。これにより、高品質のベクトル検索結果に最適なノード接続を作成できます。
バックフィル中のメモリ不足
Valkey および Redis OSS の書き込みオペレーションと同様に、インデックスバックフィルにはメモリ不足の制限があります。バックフィルの進行中にエンジンメモリがいっぱいになると、すべてのバックフィルが一時停止します。メモリが使用可能になると、バックフィルプロセスが再開されます。メモリ不足によりバックフィルが一時停止されたときに、削除してインデックスを作成することも可能です。
トランザクション
コマンド FT.CREATE、FT.DROPINDEX、FT.ALIASADD、FT.ALIASDEL、および FT.ALIASUPDATE は、トランザクションコンテキストでは実行できません。すなわち、MULTI/EXEC ブロック内、または LUA もしくは FUNCTION スクリプト内では実行できません。
