翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Gremlin ロードデータ形式
Apache TinkerPop Gremlin データを CSV 形式を使用してロードするには、頂点とエッジを別々のファイルで指定する必要があります。
ローダーは、単一のロードジョブで複数の頂点ファイルおよび複数のエッジファイルからロードできます。
各ロードコマンドは、ロードされる一連のファイルと同じ Amazon S3 バケットのフォルダにある必要があり、source パラメータにフォルダ名を指定します。このファイル名とファイル名拡張子は重要ではありません。
Amazon Neptune CSV 形式は RFC 4180 の CSV の仕様に従います。詳細については、Internet Engineering Task Force (IETF) ウェブサイトの、CSV ファイルの一般形式と MIME タイプ
注記
すべてのファイルは、UTF-8 形式でエンコードする必要があります。
各ファイルには、カンマ区切りのヘッダー行があります。ヘッダー行は、システム列ヘッダーとプロパティ列ヘッダーの両方で構成されます。
システム列ヘッダー
頂点ファイルとエッジファイルでは、必須および許可されたシステム列ヘッダーが異なります。
各システム列は、ヘッダーに 1 回のみ表示できます。
すべてのラベルで大文字と小文字が区別されます。
頂点ヘッダー
-
~id- 必須頂点の ID。
-
~label頂点のラベル。複数のラベル値を使用できます。セミコロン (
;) で区切ります。~labelが存在しない場合、TinkerPop は値vertexのラベルを提供します。これは、すべての頂点に少なくとも 1 つのラベルが必要なためです。
エッジヘッダー
-
~id- 必須エッジの ID。
-
~from- 必須from 頂点の頂点 ID。
-
~to- 必須to 頂点の頂点 ID。
-
~labelエッジのラベル。エッジには 1 つのラベルのみを含めることができます。
~labelが存在しない場合、TinkerPop は値edgeのラベルを提供します。これは、すべてのエッジにラベルが必要なためです。
プロパティ列ヘッダー
次の構文を使用して、プロパティ列 (:) を指定できます。タイプ名では大文字と小文字が区別されません。ただし、プロパティ名内にコロンがある場合は、次のように、その前にバックスラッシュを付けてエスケープする必要があります。\:。
propertyname:type
注記
列ヘッダーでは、スペース、カンマ、キャリッジリターン、改行文字は使用できません。そのため、プロパティ名にこれらの文字を含めることはできません。
タイプに [] を追加することで、配列型の列を指定できます。
propertyname:type[]
注記
エッジのプロパティに指定できるのは 1 つの値のみです。配列型が指定された場合や 2 つ目の値が指定された場合はエラーが発生します。
次の例は、Int 型の age という名前のプロパティの列ヘッダーを示しています。
age:Int
ファイルのすべての行は、その位置に整数があるか、空のままにする必要があります。
文字列の配列は許可されますが、バックスラッシュを使用してエスケープされないり限配列内の文字列にはセミコロン (;) 文字を含めることはできません (次のように:\;)。
列の濃度を指定する
リリース 1.0.1.0.200366.0 (2019-07-26) では、列ヘッダーを使用して、列で識別されたプロパティの濃度を指定できます。これにより、バルクローダーで Gremlin クエリと同様に濃度を重視できます。
列の濃度は、次のように指定します。
propertyname:type(cardinality)
濃度値は single または set となります。デフォルトは set であると想定されます。これは、列が複数の値を受け入れられることを意味します。エッジファイルの場合、濃度は常に単一であり、他の濃度を指定すると、ローダーは例外をスローします。
濃度が single のとき、値がロードされたときに前の値がすでに存在する場合、または複数の値がロードされた場合、ローダーによりエラーがスローされます。updateSingleCardinalityProperties フラグを使用して新しい値がロードされたとき、既存の値が置き換えられるように、 この動作をオーバーライドできます。「ローダーコマンド」を参照してください。
通常、その必要はありませんが、配列型で濃度設定を使用できます。可能な組み合わせは次のとおりです。
name:type- 濃度はsetで、コンテンツは単一の値です。name:type[]- 濃度はsetで、コンテンツは複数の値です。name:type(single)- 濃度はsingleで、コンテンツは単一の値です。name:type(set)- 濃度は、デフォルトと同じsetで、コンテンツは単一の値です。name:type(set)[]- 濃度はsetで、コンテンツは複数の値です。name:type(single)[]- これは矛盾しており、エラーがスローされます。
次のセクションでは、使用可能なすべての Gremlin データ型を示します。
Gremlin データ型
これは許可されたプロパティタイプの一覧で、各タイプの説明を含みます。
Bool (または Boolean)
ブールフィールドであることを示しています。許可された値: false、true
注記
true 以外の値は false として扱われます。
整数型
定義された範囲外の値の場合、エラーが発生します。
| タイプ | Range |
|---|---|
| Byte | -128 to 127 |
| Short | -32768 to 32767 |
| Int | -2^31 to 2^31-1 |
| Long | -2^63 to 2^63-1 |
10 進数型
指数表記または 10 進表記の両方をサポートしています。また、(+/-) INFINITY や NaN などの記号も使用できます。INF はサポートされていません。
| タイプ | Range |
|---|---|
| Float | 32-bit IEEE 754 floating point |
| Double | 64-bit IEEE 754 floating point |
長すぎる浮動小数点数や倍精度浮動小数点数の値は、24 ビット (浮動小数点数) および 53 ビット (倍精度浮動小数点数) の精度で最も近い値にロードされ、丸められます。中間の値は、ビットレベルの最後の残りの桁で 0 に丸められます。
文字列
引用符はオプションです。カンマ、改行、およびキャリッジリターン文字は、二重引用符 (") で囲まれた文字列に含まれると自動的にエスケープされます。例: "Hello,
World"
引用符で囲まれた文字列に引用符を含めるには、行内で 2 つ使用して引用符をエスケープします。例 : "Hello
""World"""
文字列の配列は許可されますが、バックスラッシュを使用してエスケープされないり限配列内の文字列にはセミコロン (;) 文字を含めることはできません (次のように:\;)。
配列内の文字列を引用符で囲む場合は、配列全体を 1 組の引用符で囲む必要があります。例: "String one; String 2; String 3"
日付
ISO-8601 形式の Java の日付。、yyyy-MM-dd、yyyy-MM-ddTHH:mm、 yyyy-MM-ddTHH:mm:ssの形式をサポートしますyyyy-MM-ddTHH:mm:ssZ。値はエポック時間に変換され、保存されます。
Datetime
ISO-8601 形式の Java の日付。、yyyy-MM-dd、yyyy-MM-ddTHH:mm、 yyyy-MM-ddTHH:mm:ssの形式をサポートしますyyyy-MM-ddTHH:mm:ssZ。値はエポック時間に変換され、保存されます。
Gremlin 行形式
区切り記号
行内のフィールドはカンマで区切られます。レコードは、改行またはキャリッジリターンとそれに続く改行で区切られます。
空のフィールド
空のフィールドは、必須ではない列 (ユーザー定義のプロパティなど) に許可されています。空のフィールドにもカンマ区切り記号が必要です。必須フィールドが空白の場合、解析エラーが発生します。空の文字列値は、フィールドの空の文字列値として解釈され、空白のフィールドとして解釈されません。次のセクションの例では、各頂点の例に空白のフィールドがあります。
頂点 ID
~id 値はすべての頂点ファイル内のすべての頂点に対して一意である必要があります。~id 値が同一の複数の頂点行はグラフの単一の頂点に適用されます。空の文字列 ("") は有効な ID であり、頂点は空の文字列を ID として作成します。
エッジ ID
また、~id 値はすべてのエッジファイル内のすべてのエッジに対して一意である必要があります。~id 値が同一の複数のエッジ行はグラフの単一のエッジに適用されます。空の文字列 ("") は有効な ID であり、エッジは空の文字列を ID として作成します。
ラベル
ラベルでは大文字と小文字が区別され、空にすることはできません。の値を指定すると、エラー""が発生します。
文字列値
引用符はオプションです。カンマ、改行、およびキャリッジリターン文字は、二重引用符 (") で囲まれた文字列に含まれると自動的にエスケープされます。空の文字列値は("")、フィールドの空の文字列値として解釈され、空白のフィールドとして解釈されません。
CSV 形式の仕様
Neptune CSV 形式は RFC 4180 の CSV の仕様に従い、次の要件を含みます。
Unix と Windows の両方のスタイルの行末処理がサポートされています (\n または \r\n)。
フィールドはすべて引用符で囲むことができます (二重引用符を使用)。
改行、二重引用符、またはカンマを含むフィールドは、引用符で囲む必要があります。(そうでない場合、ロードは即座に中止されます)。
フィールド内の二重引用符文字 (
") は、2 つの二重引用符文字で示す必要があります。たとえば、データ内で、文字列Hello "World"は、"Hello ""World"""であることが必要です。区切り記号間のスペースは無視されます。行が として存在する場合は
value1, value2、"value1"および として保存されます"value2"。その他のエスケープ文字はすべてそのまま保存されます。たとえば、
"data1\tdata2"であれば"data1\tdata2"として保存されます。これらの文字が引用符で囲まれている場合、これ以上エスケープする必要はありません。空のフィールドは許可されます。空白のフィールドは空の値と見なされます。
フィールドの複数の値は、値と値の間にセミコロン (
;) を使用して指定します。
詳細については、Internet Engineering Task Force (IETF) ウェブサイトの、CSV ファイルの一般形式と MIME タイプ
Gremlin の例
次の図の例では、TinkerPop 最新グラフから取得した 2 つの頂点と、エッジの例を示しています。
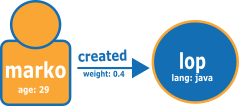
以下に示しているのは、Neptune CSV ロード形式のグラフです。
頂点ファイル:
~id,name:String,age:Int,lang:String,interests:String[],~label v1,"marko",29,,"sailing;graphs",person v2,"lop",,"java",,software
頂点ファイルの表形式のビュー:
| ~id | name:String | age:Int | lang:String | interests:String[] | ~label |
| v1 | "marko" | 29 | ["sailing", "graphs"] | person | |
| v2 | "lop" | "java" | software |
エッジファイル:
~id,~from,~to,~label,weight:Double e1,v1,v2,created,0.4
エッジファイルの表形式のビュー:
| ~id | ~from | ~to | ~label | weight:Double |
| e1 | v1 | v2 | created | 0.4 |
次のステップ
次に、ロード形式の詳細については、例: Neptune DB インスタンスにデータをロードする を参照してください。
