翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon OpenSearch Service での異常検出
Amazon OpenSearch Service の異常検出機能は、ランダムカットフォレスト (RCF) アルゴリズムを使用して、ほぼリアルタイムで OpenSearch データ内の異常を自動的に検出します。RCFは、受信データストリームのスケッチをモデル化する教師なしの機械学習アルゴリズムです。このアルゴリズムにより、受信データポイントごとに、anomaly grade および confidence score の値が計算されます。異常検出は、これらの値を使用して、データの通常の変動と異常を区別します。
異常検出プラグインとアラートプラグインを組み合わせると、異常が検出された場合にすぐに通知を受けることができます。
異常検出は、OpenSearch バージョンまたは Elasticsearch 7.4 以降を実行しているドメインで使用できます。t2.micro と t2.small を除くすべてのインスタンスタイプで、異常検出がサポートされています。
注記
このドキュメントでは、Amazon OpenSearch Service のコンテキストにおける異常検出の概要を説明します。詳細な手順、API リファレンス、使用可能なすべての設定のリファレンス、視覚化とダッシュボードを作成する手順を含む包括的なドキュメントについては、オープンソースの OpenSearch ドキュメントの「Anomaly detection
前提条件
異常検出には、次のような前提条件があります。
-
異常検出には OpenSearch または Elasticsearch 7.4 以降が必要です。
-
異常検出では、きめ細かなアクセスコントロールを Elasticsearch バージョン 7.9 以降とすべてのバージョンの OpenSearch で利用できます。Elasticsearch 7.9 より前のバージョンでは、ディテクターを作成、表示、管理できるのは管理者ユーザーのみです。
-
ドメインできめ細かなアクセスコントロールを使用する場合、管理者以外のユーザーは、ディテクターを表示するには OpenSearch Dashboards の
anomaly_read_accessロールに、またはディテクターを作成および管理するにはanomaly_full_accessにマッピングされている必要があります。
異常検出の開始方法
開始するには、OpenSearch Dashboards で [異常検出] を選択します。
ステップ 1: ディテクターを作成する
ディテクターは、個別の異常検出タスクです。複数のディテクターを作成し、すべてのディテクターを同時に実行すると、それぞれ別々のソースからのデータを分析できます。
ステップ 2: ディテクターに機能を追加する
機能とは、異常をチェックするインデックス内のフィールドを指します。ディテクターでは、1 つ以上の機能について異常を検出できます。機能ごとに、以下の集計の 1 つを選択する必要があります: average()、sum()、count()、min()、または max()。
注記
count() の集計方法は、OpenSearch および Elasticsearch 7.7 以降でのみ利用できます。Elasticsearch 7.4では、次のようなカスタム式を使用します。
{ "aggregation_name": { "value_count": { "field": "field_name" } } }
集計方法によって、検出される異常の性質も異なります。例えば、min() を選択した場合、ディテクターは機能の最小値に基づいて異常を検出します。average() を選択した場合、ディテクターは機能の平均値に基づいて異常を検出します。ディテクターごとに追加できる機能は、最大 5 つです。
以下のオプション設定を指定できます (Elasticsearch 7.7 以降で使用可能)。
-
Category field (カテゴリフィールド) - IPアドレス、製品 ID、国コードなどのディメンションでデータを分類またはスライスします。
-
Window size (ウィンドウサイズ) - 検出ウィンドウで考慮するデータストリームからの集計間隔の数を設定します。
機能を設定したならば、サンプルの異常をプレビューし、必要に応じて機能の設定を調整します。
ステップ 3: 結果を観察する
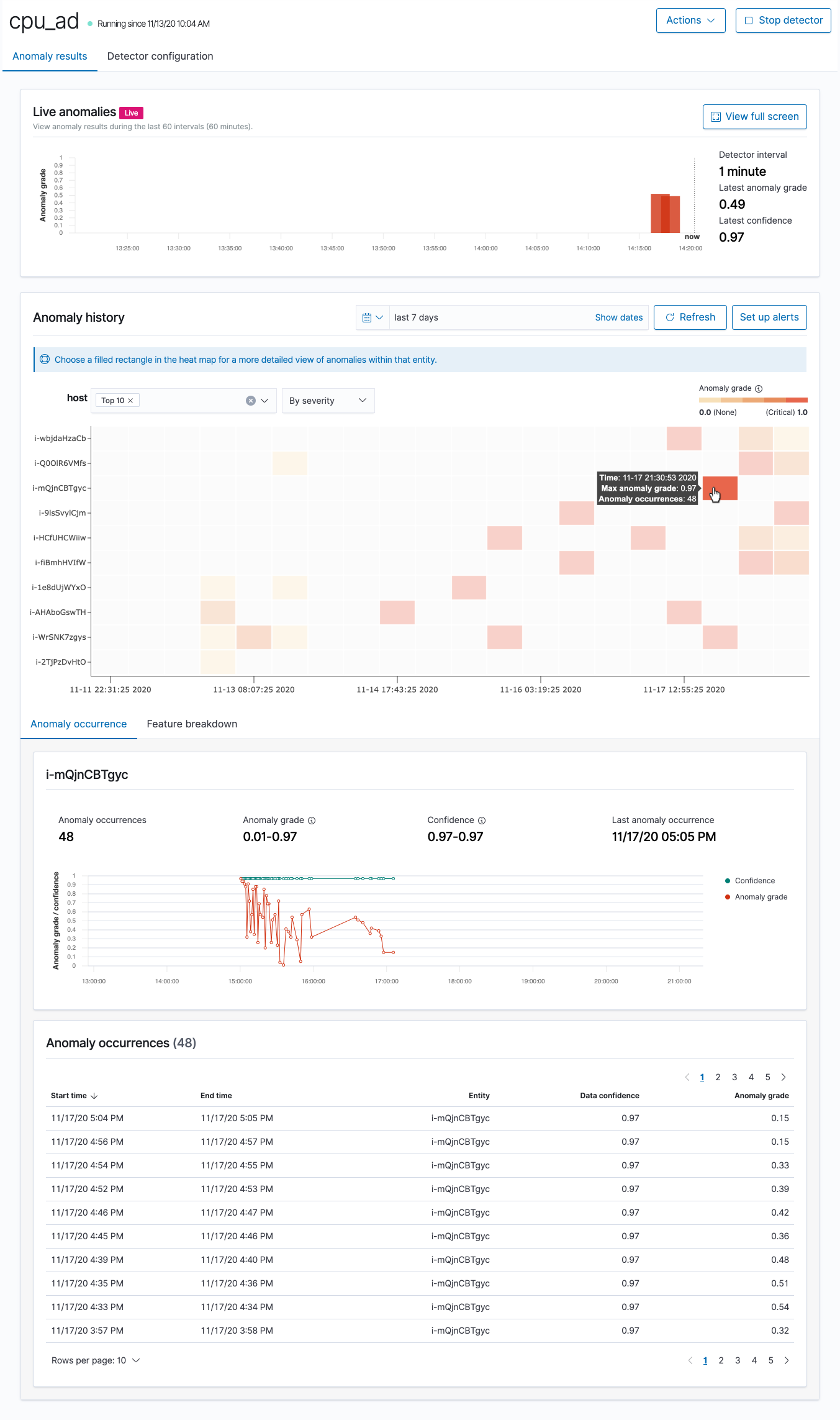
-
Live anomalies (ライブ異常) - 過去 60 間隔のライブ異常結果を表示します。たとえば、間隔を 10 に設定すると、過去 600 分間の結果が表示されます。このグラフは 30 秒ごとに更新されます。
-
Anomaly history (異常履歴) - 対応する測定指標とともに、異常の等級を示します。
-
Feature breakdown (機能分類) - 集計方法に基づいて機能を分類します。ディテクターの日時の範囲は変更できます。
-
Anomaly occurrence (異常出現) - 検出された各異常の
Start time、End time、Data confidence、およびAnomaly gradeを示します。カテゴリフィールドを設定すると、異常エンティティの結果を関連付ける、追加のヒートマップチャートが表示されます。塗りつぶされた長方形を選択すると、異常のより詳細なビューが表示されます。
ステップ 4: アラートのセットアップ
異常が検出されたときに通知を受け取るためのモニタを作成するには、[アラートのセットアップ] を選択します。プラグインにより、アラートを設定できる [モニタの追加]
