Workflow for evaluators and reflect-refine loops
This workflow provides a feedback loop where one LLM generates a result, and another evaluates or critiques the result. This promotes self-reflection, optimization, and iterative improvements.
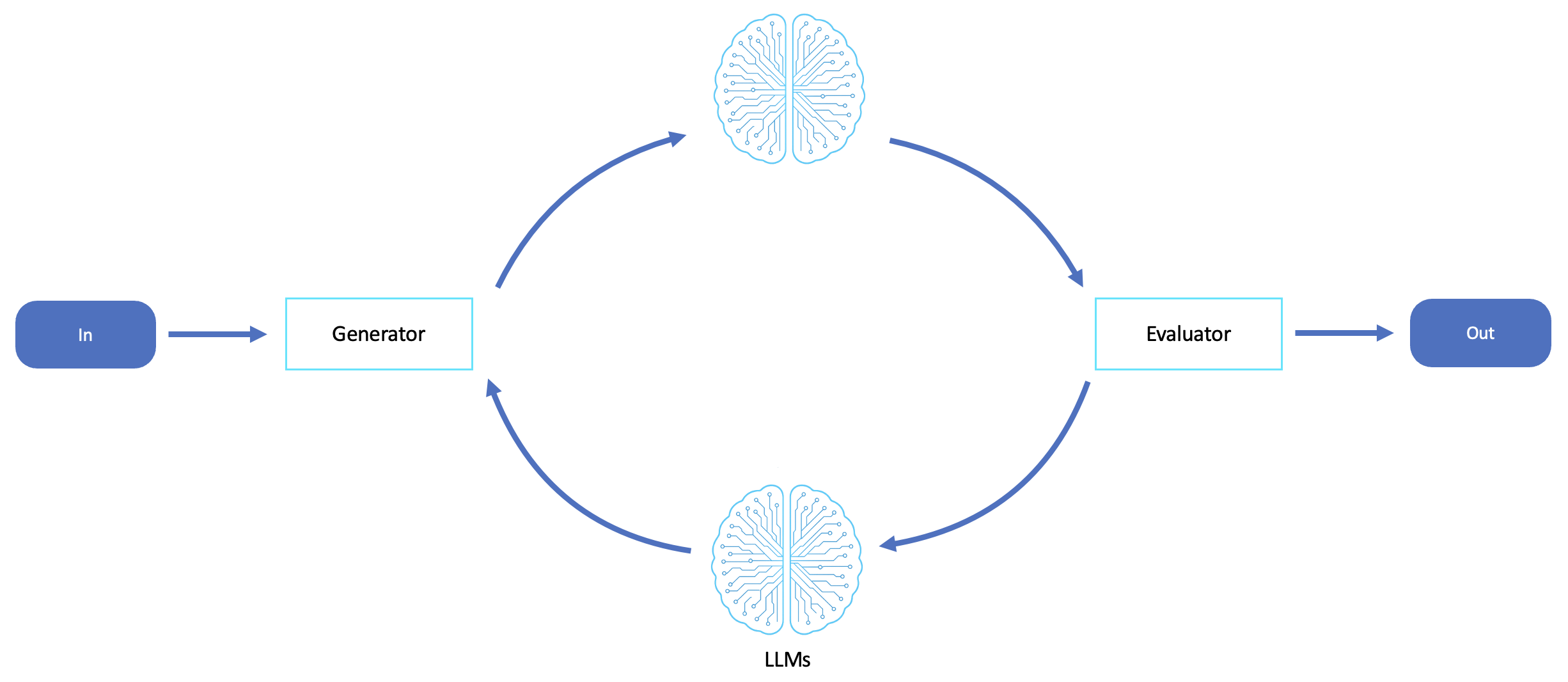
The evaluator workflow is ideal for scenarios where output quality, accuracy, and alignment are important and where single-pass generation is unreliable or insufficient. This workflow excels when agents must self-critique, iterate, and refine their outputs—either to meet a higher standard of correctness or to explore improved alternatives based on feedback.
This workflow is particularly effective when:
-
The output involves subjective quality metrics (for example, style, tone, and readability) or objective criteria (for example, correctness, safety, and performance).
-
The agent must reason through trade-offs, evaluate constraints, or optimize toward a goal.
-
You require built-in redundancy and quality assurance, especially in regulated, customer-facing, or creative domains.
-
Human-in-the-loop review is expensive or unavailable, and autonomous validation is desired.
This workflow is used for content generation, code synthesis and review, policy enforcement, alignment checking, instruction tuning, and RAG postprocessing. It is also useful for self-improving agents, where continuous feedback helps shape better responses over time to build trustworthy, autonomous decision loops.
Common use cases
-
Red-team agents compared to blue-team agents
-
Agents that generate, evaluate, and revise code or plans
-
Quality assurance, hallucination detection, and style enforcement
Capabilities
-
Supports decoupled generation and evaluation using different models (for example, Claude for generation and Mistral for evaluation)
-
Feedback is structured and used to prompt revised outputs
-
Supports multiple iterations or convergence thresholds
