翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
圧縮を使用したテーブルのメンテナンス
Iceberg には、テーブルにデータを書き込んだ後にテーブルのメンテナンス操作
Iceberg 圧縮
Iceberg では、圧縮を使用して 4 つのタスクを実行できます。
-
小さなファイルを、通常 100 MB を超えるサイズの大きなファイルに結合します。この手法はビンパッキングと呼ばれます。
-
削除ファイルをデータファイルとマージします。削除ファイルは、merge-on-readアプローチを使用する更新または削除によって生成されます。
-
(再) クエリパターンに従ってデータをソートします。データは、ソート順なしで、または書き込みと更新に適したソート順で書き込むことができます。
-
スペースフィル曲線を使用してデータをクラスター化し、個別のクエリパターン、特に z 順序ソートを最適化します。
では AWS、Amazon Athena を介して、または Amazon EMR または で Spark を使用して、Iceberg のテーブル圧縮およびメンテナンスオペレーションを実行できます AWS Glue。
rewrite_data_files
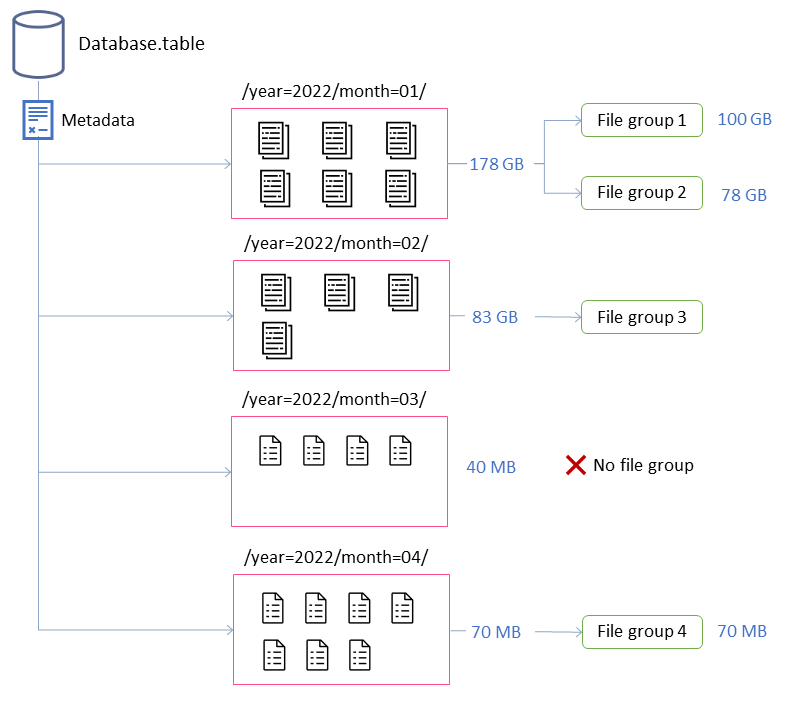
この例では、Iceberg テーブルは 4 つのパーティションで構成されています。各パーティションのサイズとファイルの数は異なります。Spark アプリケーションを起動して圧縮を実行すると、アプリケーションは合計 4 つのファイルグループを作成して処理します。ファイルグループは、単一の Spark ジョブによって処理されるファイルのコレクションを表す Iceberg 抽象化です。つまり、圧縮を実行する Spark アプリケーションは、データを処理するための 4 つの Spark ジョブを作成します。
圧縮動作の調整
次のキープロパティは、圧縮のためにデータファイルを選択する方法を制御します。
-
MAX_FILE_GROUP_SIZE_BYTES
は、デフォルトで単一のファイルグループ (Spark ジョブ) のデータ制限を 100 GB に設定します。このプロパティは、パーティションのないテーブルや数百ギガバイトにまたがるパーティションを持つテーブルにとって特に重要です。この制限を設定することで、クラスターでのリソースの枯渇を防ぎながら、オペレーションを分割して作業を計画し、進行させることができます。 注: 各ファイルグループは個別にソートされます。したがって、パーティションレベルのソートを実行する場合は、パーティションサイズに合わせてこの制限を調整する必要があります。
-
MIN_FILE_SIZE_BYTES
または MIN_FILE_SIZE_DEFAULT_RATIO は、デフォルトでテーブルレベルで設定されたターゲットファイルサイズの 75% に設定されます。たとえば、テーブルのターゲットサイズが 512 MB の場合、384 MB 未満のファイルは圧縮されるファイルのセットに含まれます。 -
MAX_FILE_SIZE_BYTES
または MAX_FILE_SIZE_DEFAULT_RATIO のデフォルトは、ターゲットファイルサイズの 180% です。最小ファイルサイズを設定する 2 つのプロパティと同様に、これらのプロパティは圧縮ジョブの候補ファイルを識別するために使用されます。 -
MIN_INPUT_FILES
は、テーブルパーティションサイズがターゲットファイルサイズより小さい場合に圧縮するファイルの最小数を指定します。このプロパティの値は、ファイル数 (デフォルトは 5) に基づいてファイルを圧縮する価値があるかどうかを判断するために使用されます。 -
DELETE_FILE_THRESHOLD
は、圧縮に含まれる前のファイルの削除オペレーションの最小数を指定します。特に指定しない限り、圧縮は削除ファイルをデータファイルと組み合わせません。この機能を有効にするには、このプロパティを使用してしきい値を設定する必要があります。このしきい値は個々のデータファイルに固有のため、3 に設定すると、それを参照する削除ファイルが 3 つ以上ある場合にのみ、データファイルが書き直されます。
これらのプロパティは、前の図のファイルグループの形成に関するインサイトを提供します。
たとえば、ラベルが付けられたパーティションには、最大サイズの制約である 100 GB を超えているため、2 つのファイルグループmonth=01が含まれています。対照的に、month=02パーティションには 100 GB 未満の単一のファイルグループが含まれています。month=03 パーティションは、5 つのファイルのデフォルトの最小入力ファイル要件を満たしていません。その結果、圧縮されません。最後に、month=04パーティションには目的のサイズの単一のファイルを形成するのに十分なデータが含まれていませんが、パーティションには 5 つ以上の小さなファイルが含まれているため、ファイルは圧縮されます。
Amazon EMR または で実行されている Spark に対してこれらのパラメータを設定できます AWS Glue。Amazon Athena では、プレフィックス で始まるテーブルプロパティを使用して、同様のプロパティを管理できますoptimize_)。
Amazon EMR または で Spark を使用して圧縮を実行する AWS Glue
このセクションでは、Spark クラスターのサイズを適切に設定して Iceberg の圧縮ユーティリティを実行する方法について説明します。次の例では Amazon EMR Serverless を使用していますが、EC2 または EKS 上の Amazon EMR、または で同じ方法を使用できます AWS Glue。
ファイルグループと Spark ジョブ間の相関関係を活用して、クラスターリソースを計画できます。ファイルグループを順番に処理するには、ファイルグループあたりの最大サイズ 100 GB を考慮して、次の Spark プロパティを設定できます。
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
圧縮を高速化する場合は、並列に圧縮されるファイルグループの数を増やすことで、水平方向にスケールできます。手動または動的スケーリングを使用して Amazon EMR をスケーリングすることもできます。
-
手動スケーリング (4 倍など)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(係数) -
spark.executor.instances=5(例で使用されている値) x4(係数) =20 -
spark.dynamicAllocation.enabled=FALSE
-
-
動的スケーリング
-
spark.dynamicAllocation.enabled=TRUE(デフォルト、アクション不要) -
MAX_CONCURRENT_FILE_GROUP_REWRITES
= N(この値をデフォルトで 100spark.dynamicAllocation.maxExecutorsの に揃えます。例のエグゼキュター設定に基づいて、 を 20Nに設定できます)
これらは、クラスターのサイズ設定に役立つガイドラインです。ただし、Spark ジョブのパフォーマンスをモニタリングして、ワークロードに最適な設定を見つける必要もあります。
-
Amazon Athena で圧縮を実行する
Athena は、OPTIMIZE ステートメントを通じて Iceberg の圧縮ユーティリティの実装をマネージド機能として提供します。このステートメントを使用して、インフラストラクチャを評価することなく圧縮を実行できます。
このステートメントは、ビンパッキングアルゴリズムを使用して小さなファイルを大きなファイルにグループ化し、削除ファイルを既存のデータファイルとマージします。階層ソートまたは z 順序ソートを使用してデータをクラスター化するには、Amazon EMR または で Spark を使用します AWS Glue。
テーブル作成時の OPTIMIZEステートメントのデフォルトの動作は、 ステートメントでテーブルプロパティを渡すか、 CREATE TABLEステートメントを使用してテーブル作成後に変更できますALTER TABLE。デフォルト値については、Athena のドキュメントを参照してください。
圧縮を実行するための推奨事項
ユースケース |
レコメンデーション |
|---|---|
スケジュールに基づいてビンパッキング圧縮を実行する |
|
イベントに基づいてビンパッキング圧縮を実行する |
|
圧縮を実行してデータをソートする |
|
圧縮を実行して z 順序ソートを使用してデータをクラスター化する |
|
遅延受信データが原因で他のアプリケーションによって更新される可能性のあるパーティションで圧縮を実行する |
|
コールドパーティション (アクティブな書き込みを受信しなくなったデータパーティション) で圧縮を実行する |
|
