翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
一般的なスケーリングの課題
データレイクは、最初のデプロイ後にデータが大きくなると、いくつかの段階を経ます。スケーラブルなアーキテクチャを使用してデータレイクを設計しなかった場合、組織が課題に遭遇し、データレイクの成長によって欠点が生じる可能性があります。
以下のセクションでは、一般的なデータレイクの増加がスケーリングの課題にどのように影響するかについて説明します。
初期データレイクデプロイ
次の図は、基幹業務 A による最初のデプロイ後のデータレイクのアーキテクチャを示しています。
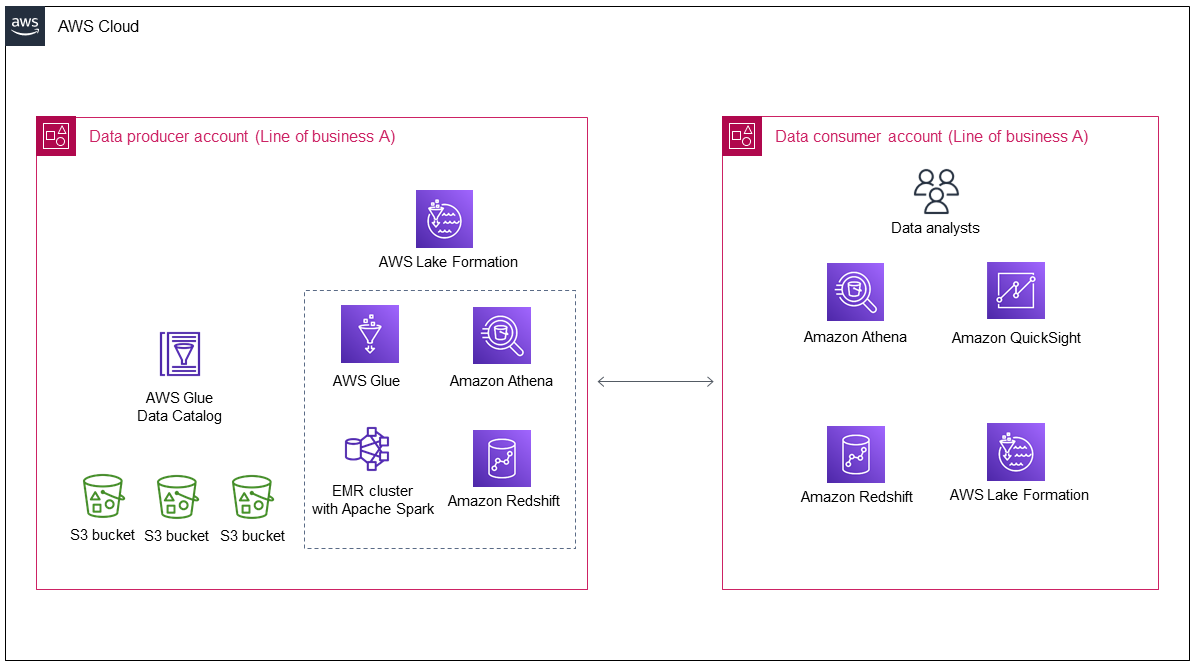
この図は、次のコンポーネントを示しています。
-
データプロデューサーアカウントは、データを収集して処理し、処理されたデータを保存して、消費用に準備します。
-
データプロデューサーアカウントのデータは Amazon Simple Storage Service (Amazon S3) バケットに保存され、複数のデータレイヤーを持つことができます。
-
データ処理に AWS サービス ( AWS Glueや Amazon EMR など) を使用できます。
-
データプロデューサーは、データレイクでデータを生成して保存するだけでなく、データコンシューマーと共有するデータとその共有方法も決定する必要があります。 は、データプロデューサーからデータコンシューマーへのクロスアカウントデータ共有を管理するだけでなく、データプロデューサーアカウントでデータレイク AWS Lake Formation を管理します。
-
データコンシューマーアカウントは、特定のビジネスユースケースのためにデータプロデューサーアカウントの共有データを消費します。
データコンシューマーの増加
次の図は、基幹業務 A のデータが増えると、より多くのデータがデータレイクに取り込まれることを示しています。その後、データレイクはより多くのデータコンシューマーを惹きつけ、データを活用してデータから価値を得ます。
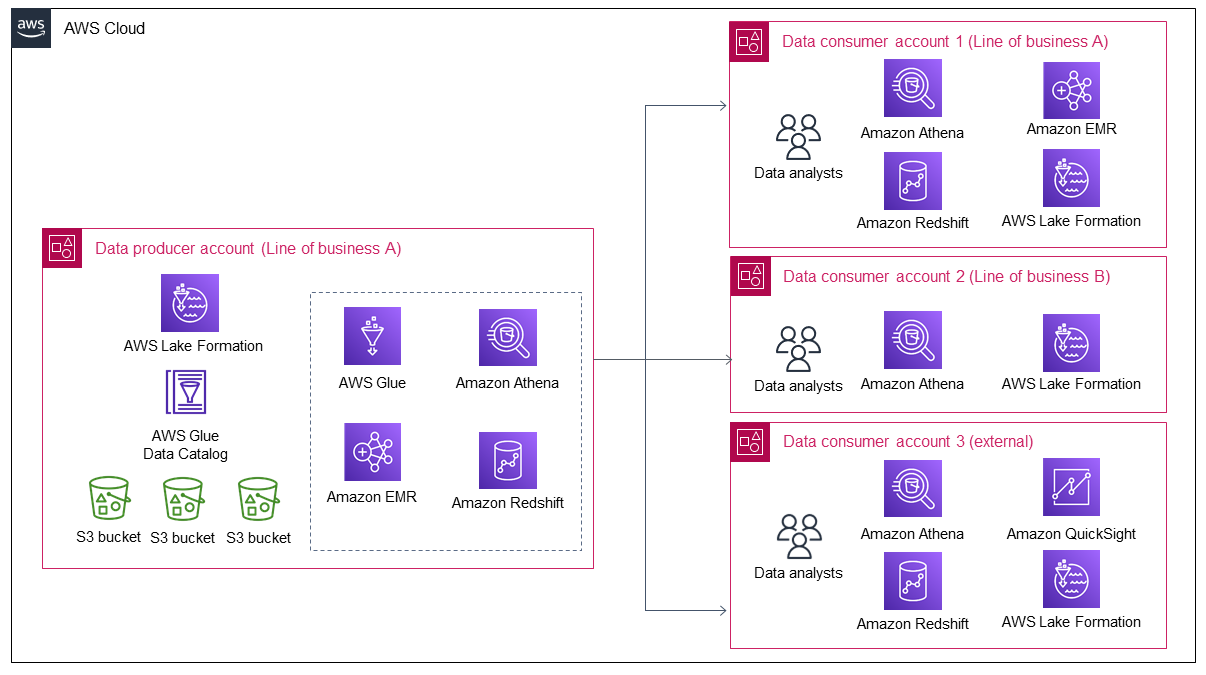
この図は、組織が既存のデータアセットからほぼ継続的な価値をどのように生成し、より多くのデータコンシューマーを引き付けるかを示しています。ただし、データコンシューマーが増加すると、データプロデューサーには、この増加に対応するための次の 2 つのオプションのみがあります。
-
個々のデータコンシューマーによるデータ共有とアクセスを手動で管理します。これはスケーラブルなアプローチではありません。
-
データ共有とデータアクセス管理のための自動または半自動プロセスを開発します。これはスケーラブルなオプションかもしれませんが、内部データコンシューマーと外部データコンシューマーのセキュリティコントロール要件が異なるため、設計と構築には多大な時間と労力が必要です。今後、ソリューションの改善には追加の時間と労力も必要になります。
データプロデューサーの増加
次の図は、複数の事業部門がデータプロデューサーとして参加する場合のデータレイクアーキテクチャを示しています。
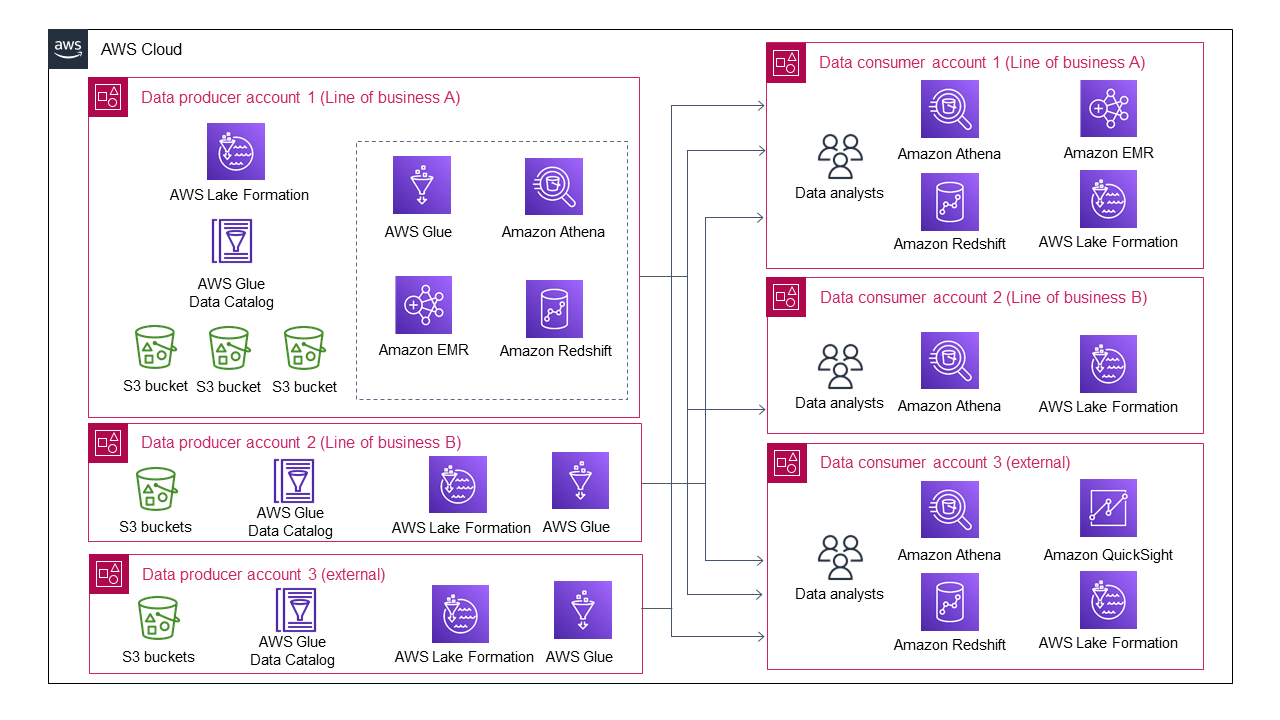
データレイクのアーキテクチャは、3 つのデータプロデューサーと 3 つのデータコンシューマーだけでも、ますます複雑になります。
各データプロデューサーは、複数のデータコンシューマーのデータ共有とデータアクセス管理を処理する必要があります。すべてのデータプロデューサーが、データ共有とデータアクセス管理のための自動または半自動プロセスを開発することは現実的ではありません。一部のデータプロデューサーは、データを共有しないことを選択するため、管理オーバーヘッドを回避できます。同様に、各データコンシューマーは複数のデータプロデューサーとやり取りして、さまざまなデータ消費プロセスを理解する必要があります。つまり、個々のデータコンシューマーは、さまざまなデータ共有パターンを処理するための管理オーバーヘッドが増加します。
多くの組織では、このデータレイクによってボトルネックが発生し、成長やスケールができません。これは、ボトルネックを取り除くために組織がデータレイクを再設計および再構築する必要があることを意味します。これにより、多大な時間、リソース、費用がかかる可能性があります。
