翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
イメージ分類モデルの構築
画像分類モデルの開発フェーズは次のとおりです。
-
要件を決定する – 必要な応答時間、ビルドレベルの労力、モデル要件、メンテナンス要件、予算など、モデルとデプロイの要件を決定します。
-
モデルの選択 – 各モデルに関連する利点とコストを含むモデルオプションのリストを作成します。モデルごとにデプロイオプションが異なります。費用対効果分析に基づいてモデルを選択します。
-
デプロイインフラストラクチャを決定する – 選択したモデルについて、デプロイインフラストラクチャプランを絞り込みます (必要な場合)。
-
モデルのモニタリングとメンテナンスのワークフローを決定する – これには、モデルアーキテクチャの更新、定期的な再トレーニング、バイアスとデータ品質のアラームをモニタリングすることでトリガーされる修正が含まれます。このワークフローの構造はアプリケーションによって異なります。例えば、需要予測モデルでは、市場傾向やその他の要因によるモデルのドリフトを考慮して、頻繁な再トレーニングとモニタリングが必要になる場合があります。セキュリティ映像内の人間を検出する分類モデルは、モデルアーキテクチャが改善された場合にのみ更新する必要がある場合があります。
次の図は、イメージ分類モデルを選択してデプロイする際に考慮する必要があるフェーズと考慮事項を示しています。
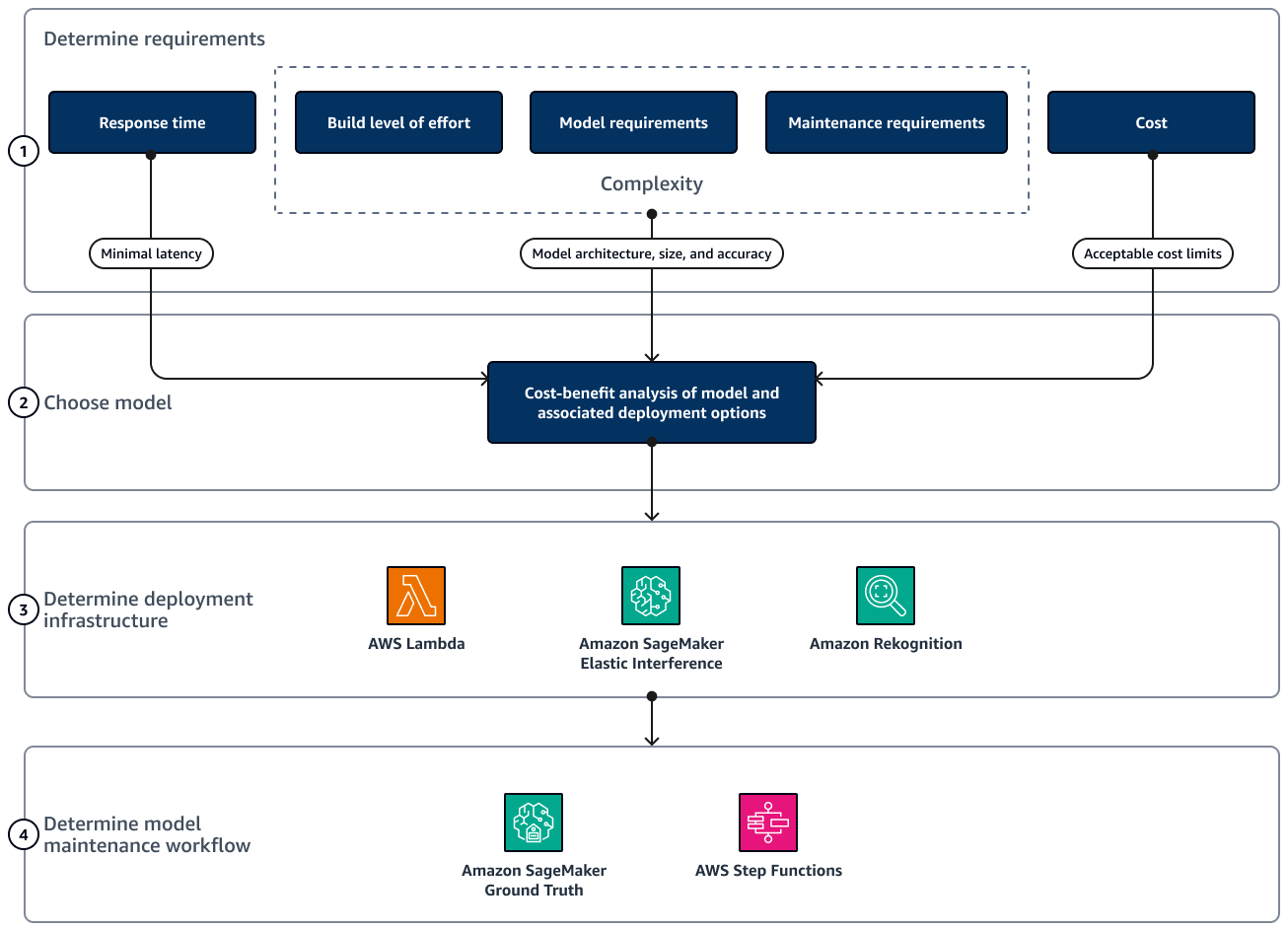
これらのフェーズは依存関係を示すように順序付けられていますが、決定の大部分はモデルを選択する第 2 フェーズで行われます。このフェーズでは、第 1 フェーズで定義した要件を満たすオプションの費用対効果分析を実行します。これは、各モデリングオプションが異なるデプロイとメンテナンスの可能性に関連付けられているためです。
このガイドでは、これらのフェーズを使用して要件を収集し、モデリングオプションを評価します。ここでは、 で AWS のサービス 利用できるモデリングオプションと、モデリングアプローチを選択した後に後続のインフラストラクチャ開発を整理する方法について説明します。
次のステップでは、コードの量と複雑さを最小限に抑えることを目標とし、モデリングアプローチを決定するための簡略化されたバージョンの概要を説明します。
-
クラスが Amazon Rekognition ラベルに既に含まれているかどうかを確認します。その場合は、ユースケースに合わせてこのサービスをベンチマークします。詳細については、このガイドのAmazon Rekognition」を参照してください。
-
デフォルトの事前トレーニング済みサービスがニーズに合わない場合は、Amazon Rekognition Custom Labels をご覧ください。詳細については、このガイドのAmazon Rekognition Custom Labels」を参照してください。
-
Amazon Rekognition も Amazon Rekognition Custom Labels もユースケースに適さない場合は、Amazon SageMaker AI Canvas によるイメージ分類を検討してください。詳細については、このガイドの「Amazon SageMaker AI Canvas」を参照してください。
-
ユースケースが SageMaker AI Canvas でカバーされていない場合は、 SageMaker AI エンドポイント (サーバーベースまたはサーバーレス) を検討してください。詳細については、このガイドの「Amazon SageMaker AI エンドポイント」を参照してください。
-
これらのサービスがユースケースに対応していない場合は、Amazon Elastic Container Service (Amazon ECS) または Amazon Elastic Kubernetes Service (Amazon ) でコンテナ化されたソリューションを使用してくださいEKS。詳細については、このガイドの「カスタムトレーニングジョブ」を参照してください。
ソリューションに特定の要件がある場合、場合によってはこれらのステップを非常に迅速にスキップできます。例えば、追加のイメージを作成することで簡単に達成できるものを超えて、関連する拡張ルーチンが必要な場合は、ステップ 1 と 2 をスキップできます。
