翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ドキュメントのカバレッジと正確性 – ドメイン内
以下のグラフに示すように、テスト時にドロップアウトを適用したディープアンサンブル、MCドロップアウト、ナイーブソフトマックス関数の予測性能を比較しました。推論の結果、不確実性が最も高い予測をさまざまなレベルで下げ、残りのデータカバレッジは 10% から 100% の範囲でした。ディープアンサンブルは、認識論的不確実性を定量化する能力、つまりモデルの経験が少ないデータ内の領域を特定する能力が高いため、不確実な予測をより効率的に特定できると期待していました。これは、データカバレッジレベルが異なれば精度が高くなることにも反映されるはずです。各ディープアンサンブルについて、5 つのモデルを使用し、20 回の推論を行いました。MC ドロップアウトでは、各モデルに 100 回推論を適用しました。各手法で同じハイパーパラメータとモデル・アーキテクチャを使用しました。
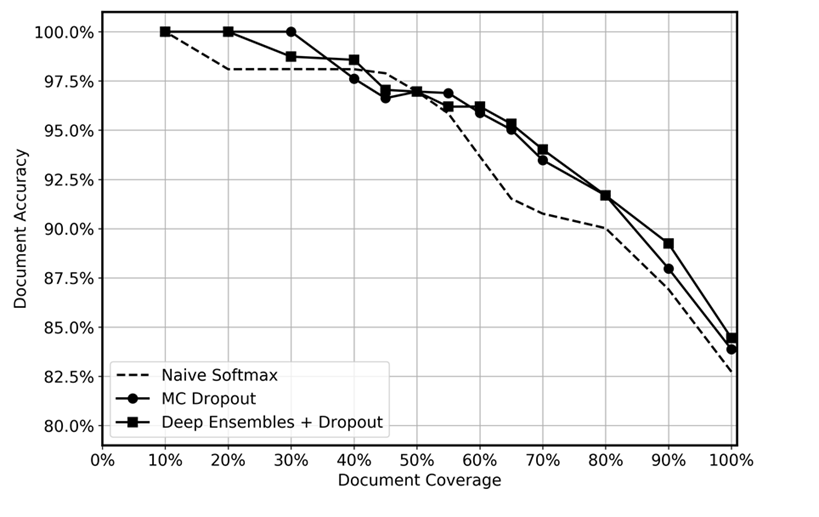
このグラフは、ナイーブソフトマックスと比較して、ディープアンサンブルと MC ドロップアウトを使用することのわずかな利点を示しているように見えます。これは 50 ~ 80% のデータカバレッジ範囲で最も顕著です。これ以上大きくならない理由 「ディープアンサンブル」のセクションで説明したように、ディープアンサンブルの強みは、さまざまな損失軌跡から得られます。この状況では、事前学習済みのモデルを使用しています。モデル全体を微調整しているが、重みの圧倒的多数は事前学習されたモデルから初期化され、ランダムに初期化される隠れ層はわずかです。したがって、大規模なモデルを事前にトレーニングすると、多様化がほとんど行われないため、自信過剰が生じる可能性があると推測されます。私たちの知る限り、ディープアンサンブルの有効性はこれまで転移学習のシナリオでテストされたことはなく、これは将来の研究にとってエキサイティングな分野であると考えています。
