翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
温度スケーリング
分類問題では、予測確率(ソフトマックス出力)が予測クラスの真の正しさ確率を表すと仮定されます。ただし、この仮定は 10 年前のモデルでは妥当だったかもしれませんが、今日の最新のニューラルネットワークモデルには当てはまりません(Guo et al.2017)。モデル予測確率とモデル予測の信頼性との間の関連性が失われると、意思決定システムのような実世界の問題に最新のニューラルネットワークモデルを適用することができなくなります。モデル予測の信頼スコアを正確に知ることは、堅牢で信頼できる機械学習アプリケーションを構築するために必要な、最も重要なリスク管理設定の 1 つです。
現代のニューラルネットワークモデルは、何百万もの学習パラメータを含む大規模なアーキテクチャを採用する傾向があります。このようなモデルの予測確率の分布は 1 か 0 のどちらかに大きく偏っていることが多く、これはモデルが自信過剰であり、これらの確率の絶対値が無意味になる可能性があることを意味します。(この問題は、データセットにクラスの不均衡が存在するかどうかとは無関係です。) 過去 10 年間に、モデルの単純確率を再調整するための後処理段階を経て、予測信頼度スコアを作成するためのさまざまなキャリブレーション方法が開発されてきました。このセクションでは、温度スケーリングと呼ばれるキャリブレーション方法の 1 つについて説明します。これは、予測確率を再調整するためのシンプルで効果的な手法です(Guo et al.2017)。温度スケーリングは、Platt Logistic Scaling (プラットロジスティックスケーリング)(Platt 1999) の単一パラメーター版です。
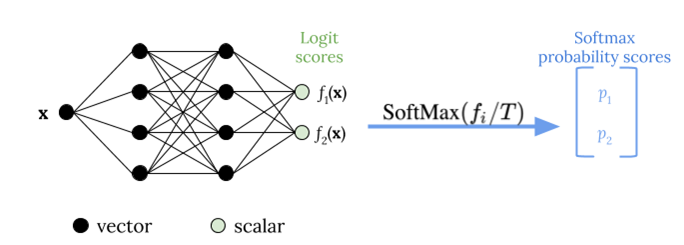
温度スケーリングは、次の図に示すように、ソフトマックス関数を適用する前にロジットスコアを再スケーリングするために、T を温度とする単一のスカラーパラメータ T > 0を使用します。すべてのクラスに同じ T が使用されるため、スケーリングありのソフトマックス出力は、スケーリングされていない出力と単調な関係になります。T = 1 の場合、デフォルトのソフトマックス関数で元の確率を回復します。T > 1の過信モデルでは、再較正された確率は元の確率よりも低い値を持ち、0 と 1 の間でより均等に分布します。
トレーニング済みのモデルに最適な温度 T を求める方法は、ホールドアウトされた検証データセットの負の対数確率を最小化することです。
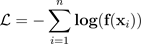
モデルトレーニングプロセスの一環として温度スケーリング法を組み込むことをお勧めします。モデルトレーニングが完了したら、検証データセットを使用して温度値 T を抽出し、ソフトマックス関数の T を使用してロジット値を再スケーリングします。BERT ベースのモデルを使用したテキスト分類タスクの実験に基づくと、温度 T は通常 1.5 ~ 3 の範囲で調整されます。
次の図は、ロジットスコアをソフトマックス関数に渡す前に温度値 T を適用する温度スケーリング法を示しています。
温度スケーリングによってキャリブレーションされた確率は、モデル予測の信頼スコアをほぼ表すことができます。これは、期待精度の分布と予測確率の分布との整合性を表す信頼性ダイアグラム(Guo et al. 2017)を作成することで定量的に評価できます。
温度スケーリングは、キャリブレーションされた確率における全体的な予測不確実性を定量化する効果的な方法としても評価されていますが、データドリフト(Ovadia et al.2019)などのシナリオにおける認識論的不確実性を捉えるには堅牢ではありません。実装の容易さを考慮すると、深層学習モデルの出力に温度スケーリングを適用して、予測の不確実性を定量化する堅牢なソリューションを構築することをお勧めします。
