翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データの準備とクリーニング
データの準備とクリーニングは、データライフサイクルの最も重要なものの、最も時間のかかる段階の 1 つです。次の図は、データ準備とクリーニングのステージがデータエンジニアリングの自動化とアクセスコントロールのライフサイクルにどのように適合するかを示しています。
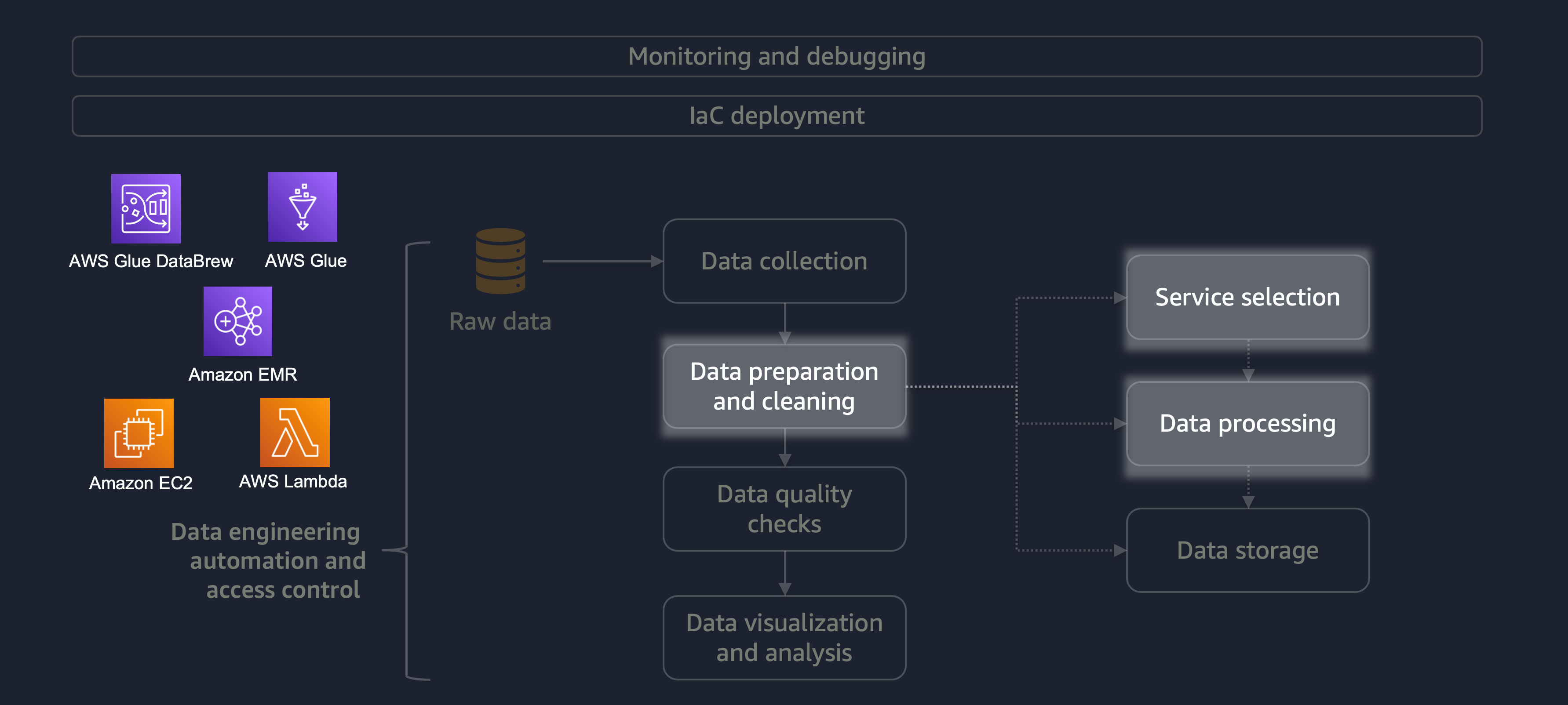
データの準備またはクリーニングの例を次に示します。
-
テキスト列をコードにマッピングする
-
空の列を無視する
-
空のデータフィールドを
0、None、または で埋める'' -
個人を特定できる情報 (PII) の匿名化またはマスキング
さまざまなデータを含む大規模なワークロードがある場合は、データの準備とクリーニングタスクに Amazon EMRDataFrameしたり、水平処理をDynamicFrame操作したりできます。さらに、AWS Glue DataBrew
分散処理を必要とせず、15 分以内に完了できる小規模なワークロードの場合は、データの準備とクリーニングに AWS Lambda
データの準備とクリーニングに適した AWS サービスを選択し、選択したトレードオフを理解することが重要です。たとえば、AWS Glue DataBrew 、Amazon EMR から選択するシナリオを考えてみましょう。AWS Glue は、ETL ジョブの頻度が低い場合に最適です。頻度の低いジョブは、1 日に 1 回、1 週間に 1 回、または 1 か月に 1 回行われます。さらに、データエンジニアが Spark コードの記述 (ビッグデータのユースケースの場合) または一般的なスクリプトに習熟していると仮定できます。ジョブの頻度が高い場合、AWS Glue を常に実行するとコストがかかる可能性があります。この場合、Amazon EMR は分散処理機能を提供し、サーバーレスバージョンとサーバーベースのバージョンの両方を提供します。データエンジニアに適切なスキルセットがない場合、または結果を高速に配信する必要がある場合は、DataBrew が適しています。DataBrew は、コード開発の労力を削減し、データの準備とクリーニングプロセスを高速化できます。
処理が完了すると、ETL プロセスのデータは AWS に保存されます。ストレージの選択は、処理するデータのタイプによって異なります。たとえば、グラフデータ、キーと値のペアデータ、画像、テキストファイル、リレーショナル構造化データなどの非リレーショナルデータを操作できます。
次の図に示すように、次の AWS サービスをデータストレージに使用できます。
-
Amazon S3
は、非構造化データまたは半構造化データ (Apache Parquet ファイル、画像、ビデオなど) を保存します。 -
Amazon Neptune
は、SPARQL または GREMLIN を使用してクエリできるグラフデータセットを保存します。 -
Amazon Keyspaces (Apache Cassandra 用)
は、Apache Cassandra と互換性のあるデータセットを保存します。 -
Amazon Aurora
はリレーショナルデータセットを保存します。 -
Amazon DynamoDB
は、キー値またはドキュメントデータを NoSQL データベースに保存します。 -
Amazon Redshift
は、構造化データのワークロードをデータウェアハウスに保存します。
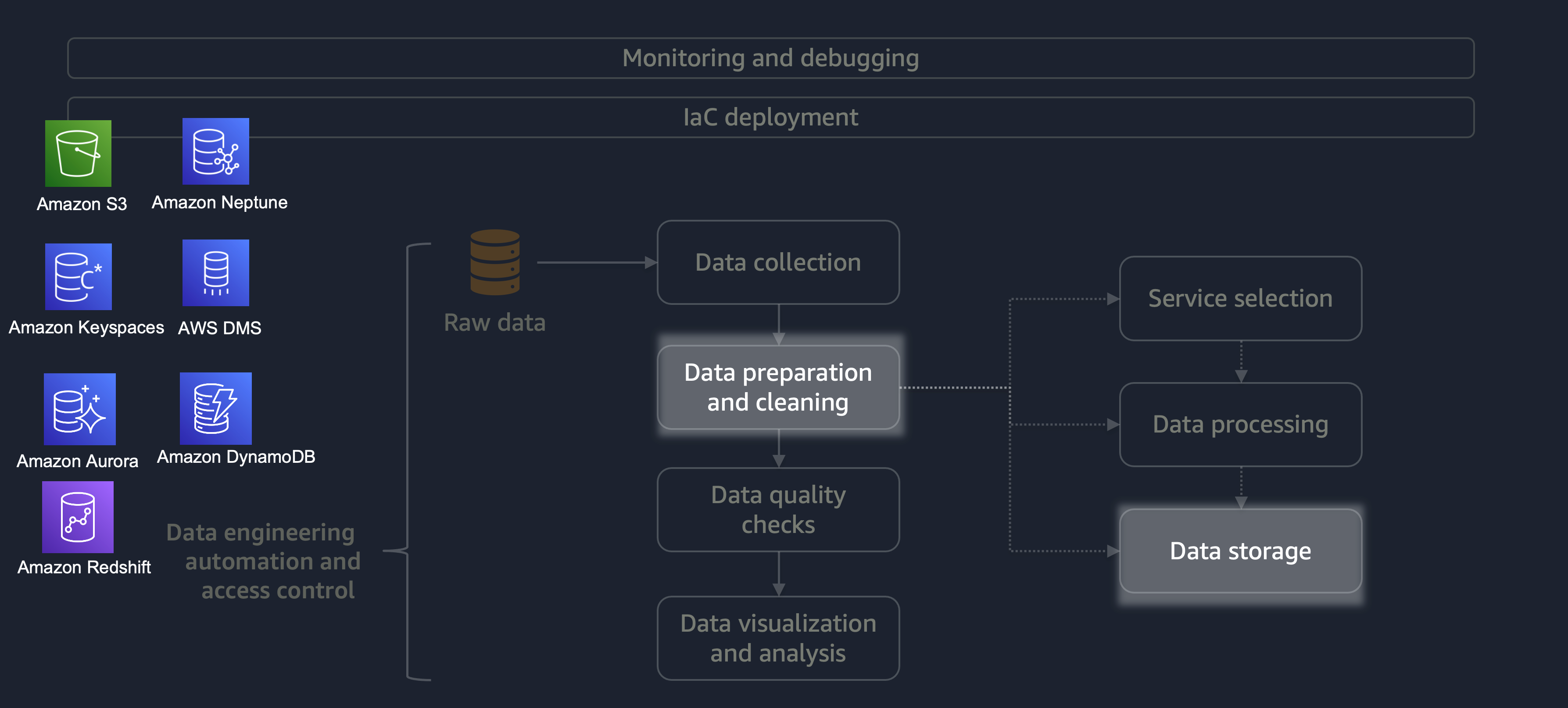
正しい設定で適切なサービスを使用することで、データを最も効率的かつ効果的な方法で保存できます。これにより、データの取得に伴う労力が最小限に抑えられます。
