翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
パフォーマンス効率の柱
AWS Well-Architected フレームワークのパフォーマンス効率の柱は、データの取り込みまたはクエリ中にパフォーマンスを最適化する方法に焦点を当てています。パフォーマンスの最適化は、以下の段階的かつ継続的なプロセスです。
-
ビジネス要件の確認
-
ワークロードのパフォーマンスの測定
-
パフォーマンスの低いコンポーネントを特定する
-
ビジネスニーズに合わせてコンポーネントを調整する
パフォーマンス効率の柱は、使用する適切なグラフデータモデルとクエリ言語を特定するのに役立つユースケース固有のガイドラインを提供します。また、Neptune Analytics にデータを取り込み、Neptune Analytics からデータを使用する際に従うべきベストプラクティスも含まれています。
パフォーマンス効率の柱は、次の主要分野に焦点を当てています。
-
グラフモデリング
-
クエリの最適化
-
グラフの正しいサイズ設定
-
書き込みの最適化
分析のグラフモデリングを理解する
Amazon Neptune 用の AWS Well-Architected フレームワークの適用」ガイドでは、パフォーマンス効率のためのグラフモデリングについて説明します。パフォーマンスに影響するモデリングの決定には、必要なノードとエッジ、IDs、ラベルとプロパティ、エッジの方向、ラベルが汎用的か固有か、一般的にクエリエンジンがグラフをナビゲートして一般的なクエリを処理できる効率の選択が含まれます。
これらの考慮事項は Neptune Analytics にも適用されますが、トランザクション使用パターンと分析使用パターンを区別することが重要です。Neptune データベースなどのトランザクションデータベース内のクエリに効率的なグラフモデルは、分析のために再構築する必要がある場合があります。
たとえば、Neptune データベースの不正グラフで、クレジットカード支払いの不正パターンをチェックする目的があるとします。このグラフには、アカウントと支払いの両方のアカウント、支払い、機能 (E メールアドレス、IP アドレス、電話番号など) を表すノードがある場合があります。この接続されたグラフは、特定の支払いから始まり、関連する機能やアカウントを見つけるためにいくつかのホップを取る可変長パスをトラバースするなどのクエリをサポートします。次の図は、このようなグラフを示しています。
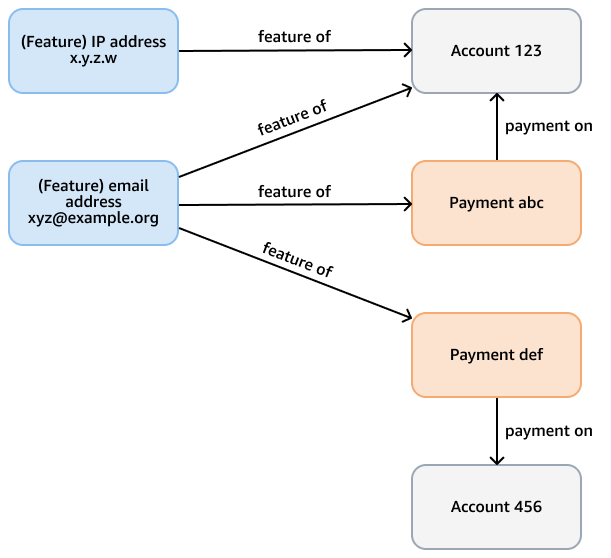
分析要件は、特徴によってリンクされたアカウントのコミュニティを検索するなど、より具体的な場合があります。この目的には、弱に接続されたコンポーネント (WCC) アルゴリズムを使用できます。前の例のモデルに対して実行するには、いくつかの異なるタイプのノードとエッジを通過する必要があるため、非効率的です。次の図のモデルはより効率的です。アカウント自体、またはアカウントからの支払いが機能を共有する場合、accountノードをshares featureエッジにリンクします。たとえば、 Account 123には E メール機能 がありxyz@example.org、支払い () に同じ E メールAccount 456を使用しますPayment def。

WCC の計算の複雑さは です。ここでO(|E|logD)、 |E|はグラフ内のエッジ数、 Dはノードを接続する直径 (最長パスの長さ) です。トランザクションモデルはイネスシャルノードとエッジを省略するため、エッジの数と直径の両方を最適化し、WCC アルゴリズムの複雑さを軽減します。
Neptune Analytics を使用する場合は、必要なアルゴリズムと分析クエリから戻してください。必要に応じて、モデルを再構築してこれらのクエリを最適化します。グラフにデータをロードしたり、グラフ内の既存のデータを変更するクエリを記述する前に、モデルを再構築できます。
クエリを最適化する
Neptune Analytics クエリを最適化するには、次の推奨事項に従ってください。
-
パラメータ化されたクエリと、デフォルトで有効になっているクエリプランキャッシュを使用します。プランキャッシュを使用すると、クエリが 100 ミリ秒以内に完了すれば、エンジンは後で使用できるようにクエリを準備します。これにより、後続の呼び出しにかかる時間を節約できます。
-
スロークエリの場合は、説明プランを実行してボトルネックを特定し、それに応じて改善を行います。
-
ベクトル類似度検索を使用する場合は、小さな埋め込みで正確な類似度の結果が得られるかどうかを決定します。小さな埋め込みをより効率的に作成、保存、検索できます。
-
Neptune Analytics で openCypher を使用するための文書化されたベストプラクティスに従います。たとえば、UNWIND 句でフラット化されたマップを使用し、可能な場合はエッジラベルを指定します。
-
グラフアルゴリズムを使用する場合は、アルゴリズムの入力と出力、計算の複雑さ、およびそれがどのように機能するかを広く理解します。
-
グラフアルゴリズムを呼び出す前に、
MATCH句を使用して入力ノードセットを最小化します。例えば、幅優先検索 (BFS) を実行するノードを制限するには、Neptune Analytics ドキュメントに記載されている例に従います。 -
可能であれば、ノードラベルとエッジラベルでフィルタリングします。たとえば、BFS には、特定のノードラベル (
vertexLabel) または特定のエッジラベル () へのトラバーサルをフィルタリングする入力パラメータがありますedgeLabels。 -
結果を制限する
maxDepthには、 などの境界パラメータを使用します。 -
concurrencyパラメータを試します。値 0 で試し、使用可能なすべてのアルゴリズムスレッドを使用して処理を並列化します。パラメータを 1 に設定して、シングルスレッド実行と比較します。アルゴリズムは 1 つのスレッドでより速く完了できます。特に、並列処理で実行時間が測定可能なほど短縮されず、オーバーヘッドが発生する可能性がある、幅が浅い最初の検索など、入力が小さい場合はなおさらです。 -
同様のタイプのアルゴリズムから選択します。たとえば、Bellman-Ford とデルタステッピングはどちらも単一ソースの最短パスアルゴリズムです。独自のデータセットでテストする場合は、両方のアルゴリズムを試し、結果を比較します。デルタステッピングは、計算の複雑さが低いため、通常、Bellman-Ford よりも高速です。ただし、パフォーマンスはデータセットと入力パラメータ、特に
deltaパラメータによって異なります。
-
書き込みの最適化
Neptune Analytics で書き込みオペレーションを最適化するには、次のプラクティスに従います。
-
グラフにデータをロードする最も効率的な方法を探します。Amazon S3 のデータからロードする場合は、データが 50 GB を超える場合は一括インポートを使用します。小さいデータの場合は、バッチロードを使用します。バッチロードの実行時にout-of-memoryエラーが発生した場合は、m-NCU 値を増やすか、ロードを複数のリクエストに分割することを検討してください。これを実現する 1 つの方法は、S3 バケット内の複数のプレフィックスにファイルを分割することです。その場合は、プレフィックスごとにバッチロードを個別に呼び出します。
-
一括インポートまたはバッチローダーを使用して、グラフデータの初期セットを入力します。トランザクション openCypher の作成、更新、削除オペレーションは、小さな変更に対してのみ使用します。
-
一括インポートまたは同時実行数が 1 (シングルスレッド) のバッチローダーを使用して、グラフに埋め込みを取り込みます。これらの方法のいずれかを使用して、埋め込みを事前にロードしてみてください。
-
ベクトル類似度検索アルゴリズムの正確な類似度検索に必要なベクトル埋め込みのディメンションを評価します。可能であれば、より小さなディメンションを使用します。これにより、埋め込みのロード速度が向上します。
-
必要に応じて、ミューテーションアルゴリズムを使用してアルゴリズムの結果を記憶します。たとえば、度可変中心性アルゴリズムは、各入力ノードの度合いを検出し、その値をノードのプロパティとして書き込みます。これらのノードを囲む接続がその後変更されない場合、 プロパティは正しい結果を保持します。アルゴリズムを再度実行する必要はありません。
-
グラフリセット管理アクションを使用して、やり直す必要がある場合は、すべてのノード、エッジ、埋め込みをクリアします。openCypher クエリを使用してすべてのノード、エッジ、埋め込みを削除することは、グラフが大きい場合は実行できません。大規模なデータセットに対する 1 回のドロップクエリはタイムアウトする可能性があります。サイズが大きくなると、データセットの削除に時間がかかり、トランザクションサイズが大きくなります。対照的に、グラフのリセットを完了する時間はほぼ一定であり、 アクションには、スナップショットを実行する前にスナップショットを作成するオプションがあります。
適切なサイズのグラフ
全体的なパフォーマンスは、Neptune Analytics グラフのプロビジョニングされた容量によって異なります。容量は、メモリ最適化 Neptune 容量単位 (m-NCUs。グラフのサイズとクエリをサポートするのに十分なサイズがグラフにあることを確認してください。容量を増やしても、個々のクエリのパフォーマンスは必ずしも向上しないことに注意してください。
可能であれば、Amazon S3 や既存の Neptune クラスターまたはスナップショットなどの既存のソースからデータをインポートしてグラフを作成します。制限は、最小容量と最大容量に設定できます。既存のグラフでプロビジョニングされた容量を変更することもできます。
NumQueuedRequestsPerSec、、NumOpenCypherRequestsPerSec、GraphStorageUsagePercent、 などの CloudWatch メトリクスをモニタリングCPUUtilizationしてGraphSizeBytes、グラフのサイズが適切かどうかを評価します。グラフのサイズと負荷をサポートするために、より多くの容量が必要かどうかを判断します。これらのメトリクスの一部を解釈する方法の詳細については、「オペレーショナルエクセレンスの柱」セクションを参照してください。
