翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Starburst AWS クラウド を使用してデータを に移行する
Antony Prasad Thevaraj と Suresh Veeragoni、Amazon Web Services
Shaun Van Staden、なし
概要
Starburst は、既存のデータソースを 1 つのアクセスポイントにまとめるエンタープライズクエリエンジンを提供することで、Amazon Web Services (AWS) へのデータ移行ジャーニーを加速します。移行計画を最終決定する前に、複数のデータ ソースにわたって分析を実行して、貴重なインサイトを得ることができます。通常どおりの分析を中断することなく、Starburst エンジンまたは専用の抽出、変換、ロード (ETL) アプリケーションを使用してデータを移行できます。
前提条件と制限
前提条件
アクティブな AWS アカウント
仮想プライベートクラウド (VPC)
Amazon Elastic Kubernetes Service (Amazon EKS) クラスター
Amazon Elastic Compute Cloud (Amazon EC2) Auto Scaling グループ
移行する必要のある現行システムワークロードのリスト
からオンプレミス環境 AWS へのネットワーク接続
アーキテクチャ
リファレンスアーキテクチャ
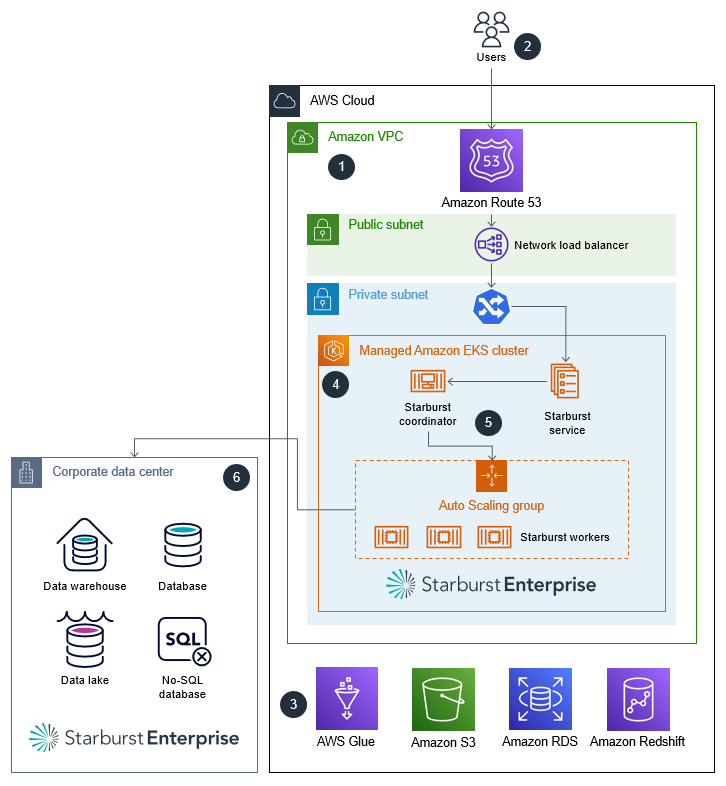
次の大まかなアーキテクチャ図は、 での Starburst Enterprise の一般的なデプロイを示しています AWS クラウド。
Starburst Enterprise クラスターは 内で実行されます AWS アカウント。
ユーザーは Lightweight Directory Access Protocol (LDAP) または Open Authorization (OAuth) を使用して認証し、Starburst クラスターと直接やり取りします。
Starburst は、Amazon Simple Storage Service (Amazon S3)、Amazon Relational Database Service (Amazon RDS) AWS Glue、Amazon Redshift など、複数の AWS データソースに接続できます。Starburst は、、オンプレミス AWS クラウド、またはその他のクラウド環境のデータソース間でフェデレーティッドクエリ機能を提供します。
Starburst Enterprise は、Helm チャートを使用して Amazon EKS クラスターで起動します。
Starburst Enterprise は、Amazon EC2 Auto Scaling グループと Amazon EC2 スポットインスタンスを使用してインフラストラクチャを最適化します。
Starburst Enterprise は既存のオンプレミスデータソースに直接接続し、データをリアルタイムで読み取ります。さらに、この環境に既存の Starburst Enterprise デプロイがある場合は、 の新しい Starburst クラスター AWS クラウド をこの既存のクラスターに直接接続できます。
以下の点に注意してください。
Starburst は、データ仮想化プラットフォームではありません。分析用のデータメッシュ戦略の基盤となる SQL ベースの超並列処理 (MPP) クエリエンジンです。
Starburst を移行の一環としてデプロイすると、既存のオンプレミスインフラストラクチャに直接接続できます。
Starburst には、さまざまなレガシーシステムへの接続を容易にするエンタープライズコネクタやオープンソースコネクタがいくつか組み込まれています。コネクターとその機能の一覧については、Starburst Enterprise ユーザーガイドの「コネクター
」を参照してください。 Starburst は、オンプレミスのデータソースからデータをリアルタイムでクエリできます。 これにより、データの移行中に通常の業務が中断することを防止できます。
既存のオンプレミス Starburst Enterprise デプロイから移行する場合は、特殊なコネクタである Starburst Stargate を使用して、 の Starburst Enterprise クラスターをオンプレミスクラスター AWS に直接接続できます。これにより、ビジネスユーザーとデータアナリストがクエリを からオンプレミス環境にフェデレーションする場合 AWS クラウド に、さらにパフォーマンス上の利点が得られます。
大まかなプロセスの概要
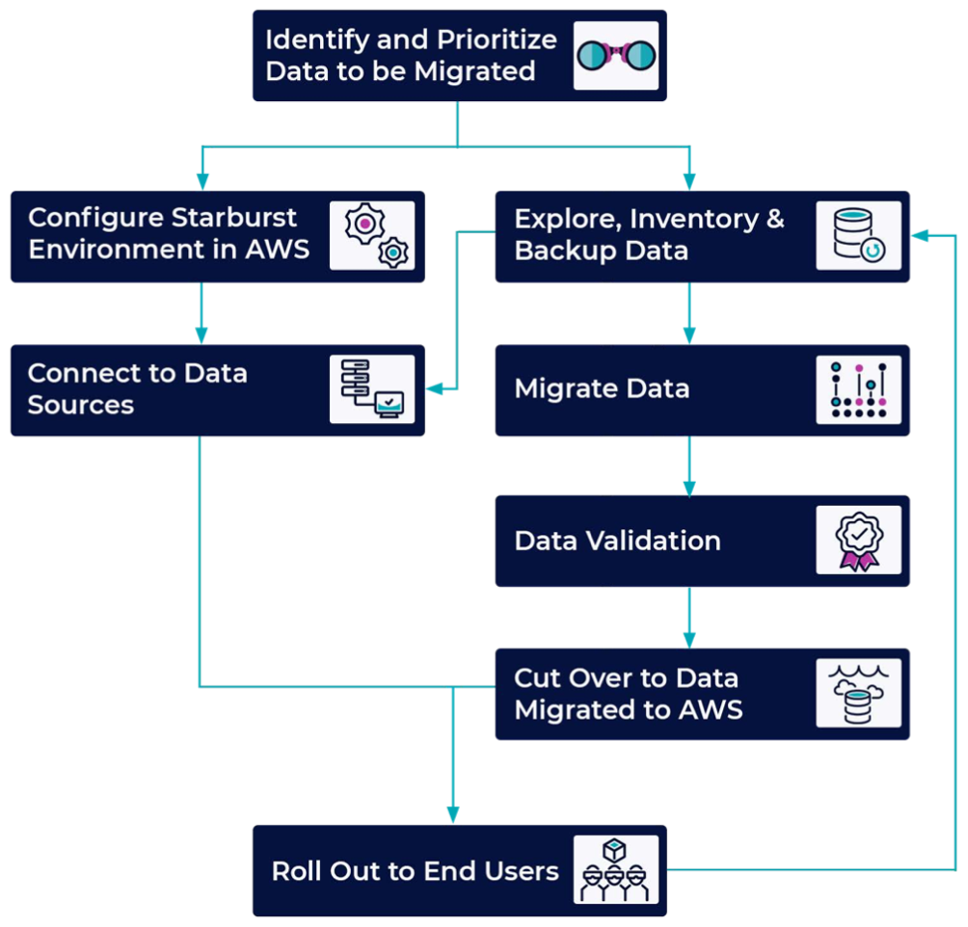
Starburst では、移行前にすべてのデータに関するインサイトを得ることができるため、データ移行プロジェクトを加速できます。次の図は、Starburst を使用してデータを移行する一般的なプロセスを示しています。
ロール
通常、Starburst を使用して移行を完了するには、以下のロールが必要です。
クラウド管理者 — Starburst Enterprise アプリケーションを実行するためにクラウドリソースを利用できるようにする責任があります。
Starburst 管理者 — Starburst アプリケーションのインストール、設定、管理、サポートを担当します。
データエンジニア — 以下の責任を負います。
クラウドにレガシーデータを移行する
分析をサポートするセマンティックビューの構築
ソリューションオーナーまたはシステムオーナー — ソリューション全体の実装を担当
ツール
AWS のサービス
Amazon Elastic Compute Cloud (Amazon EC2) は、 AWS クラウドでスケーラブルなコンピューティング容量を提供します。必要な数の仮想サーバーを起動することができ、迅速にスケールアップまたはスケールダウンができます。
Amazon Elastic Kubernetes Service (Amazon EKS) を使用すると、独自の Kubernetes コントロールプレーンやノードをインストールまたは維持 AWS することなく、 で Kubernetes を実行できます。
その他のツール
Helm
– Helm は、Kubernetes クラスター上でアプリケーションをインストールおよび管理するのに役立つ Kubernetes のパッケージマネージャです。 Starburst Enterprise
– 分析用のデータメッシュ戦略の基盤となる SQL ベースの超parallel 処理 (MPP) クエリエンジンです。 Starburst Stargate
– Starburst Stargate は、オンプレミスデータセンターのクラスターなど、ある Starburst Enterprise 環境のカタログとデータソースを、 のクラスターなど、別の Starburst Enterprise 環境のカタログとデータソースにリンクします AWS クラウド。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
データを特定して優先順位を付けます。 | 移動するデータを特定します。大規模なオンプレミスのレガシーシステムには、移行したくないデータやコンプライアンス上の理由で移動できないデータに加え、移行したいコアデータが含まれる場合があります。データインベントリで、どのデータを最初にターゲットにするか決めるのに役立ちます。詳細については、「自動ポートフォリオ検出の開始方法」 を参照してください。 | データエンジニア、DBA |
データの探索、インベントリ、バックアップを行います。 | ユースケースに応じたデータの質、量、関連性を検証します。必要に応じて、データのバックアップまたはスナップショットを作成し、データのターゲット環境を確定します。 | データエンジニア、DBA |
| タスク | 説明 | 必要なスキル |
|---|---|---|
で Starburst Enterprise を設定します AWS クラウド。 | データをカタログ化している間に、マネージド型の Amazon EKS クラスターに Starburst Enterprise を設定します。詳細については、Starburst Enterprise リファレンスドキュメントの「Kubernetes によるデプロイ | AWS 管理者、アプリ開発者 |
Starburst をデータソースに接続します。 | データを特定し、Starburst Enterprise を設定した後、Starburst をデータソースに接続します。Starburst は SQL クエリとしてデータソースから直接データを読み取ります。 詳細については、Starburst Enterprise リファレンスドキュメント | AWS 管理者、アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
ETL パイプラインを構築して実行します。 | データ移行プロセスを開始します。このアクティビティは、通常どおりの分析と同時に実施できます。移行には、サードパーティ製の製品または Starburst を使用できます。Starburst には、さまざまなソースのデータを読み書きする機能があります。詳細については、Starburst Enterprise リファレンスドキュメント | データエンジニア |
データを検証します。 | データを移行したら、データを検証して、必要なデータがすべて移動され、変更がないことを確認します。 | データエンジニア、DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
データをカットオーバーします。 | データの移行と検証が完了した後、データをカットオーバーできます。これには、Starburst のデータ接続リンクの変更が含まれます。オンプレミスのソースを指定する代わりに、新しいクラウドソースを指定してセマンティックビューを更新します。 詳細については、Starburst Enterprise リファレンスドキュメントの「コネクタ | データエンジニア、カットオーバーのリーダー |
ユーザーにロールアウトします。 | データコンシューマーは、移行したデータソースから作業を開始します。このプロセスは、分析のエンドユーザーには表示されません。 | カットオーバーのリーダー、データエンジニア |
関連リソース
AWS Marketplace
Starburst ドキュメント
その他の AWS ドキュメント
自動ポートフォリオ検出の使用を開始する (AWS 規範ガイダンス)
Starburst を使用したクラウドインフラストラクチャのコストとパフォーマンスの最適化 AWS
(AWS ブログ記事)
