翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Redshift での SQL クエリ処理
Amazon Redshift は、パーサーおよびオプティマイザを通じて送信された SQL クエリをルーティングし、クエリプランを作成します。その後、実行エンジンは、クエリプランをコードに変換し、そのコードを実行するためにコンピューティングノードに送信します。クエリプランを設計する前に、クエリ処理の仕組みを理解することが重要です。
クエリプランと実行ワークフロー
次の図は、クエリの計画と実行ワークフローの概要を示しています。
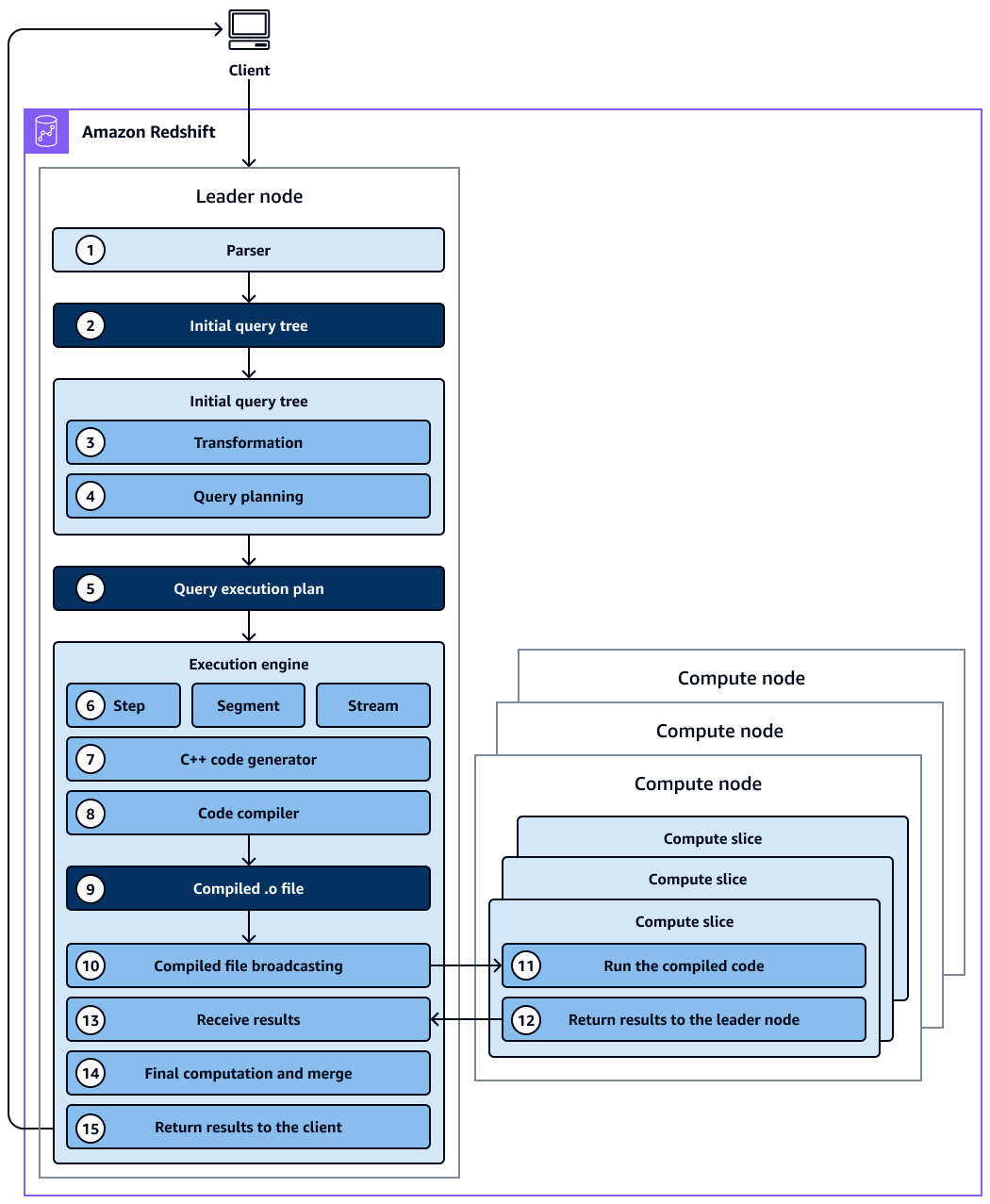
この図表は、次のワークフローを示しています:
-
Amazon Redshift クラスターのリーダーノードはクエリを受け取り、SQL ステートメントを解析します。
-
パーサーは、元のクエリの論理表現である初期クエリツリーを生成します。
-
クエリオプティマイザは、最初のクエリツリーを取得して評価し、テーブル統計を分析して結合順序と述語の選択性を判断し、必要に応じてクエリを書き換えて効率を最大化します。1 つのクエリをバックグラウンドで複数の依存ステートメントとして書き込むことができる場合があります。
-
オプティマイザは、最高のパフォーマンスで実行されるように 1 つのクエリプラン (または、前のステップで複数のクエリが生成された場合は複数のクエリプラン) を生成します。クエリプランは、実行順序、ネットワークオペレーション、結合タイプ、結合順序、集約オプション、データディストリビューションなどの実行オプションを指定します。
-
クエリプランには、クエリの実行に必要な個々のオペレーションに関する情報が含まれています。クエリプランを表示するには、
EXPLAINコマンドを使用できます。クエリプランは、複雑なクエリを分析およびチューニングするための基本ツールです。 -
クエリオプティマイザは、クエリプランを実行エンジンに送信します。実行エンジンは、コンパイルされたプランキャッシュでクエリプランの一致をチェックし、コンパイルされたキャッシュ (見つかった場合) を使用します。それ以外の場合、実行エンジンはクエリプランをステップ、セグメント、ストリームに変換します。
-
ステップは、クエリの実行中に実行される個々のオペレーションです。ステップはラベル (、、
hjoin、 などmerge)scandistで識別されます。ステップは最小の単位です。コンピューティングノードがクエリ、結合、または別のデータベースオペレーションを実行できるように、ステップを組み合わせることができます。 -
セグメントはクエリのセグメントを参照し、1 つのプロセスで実行できるいくつかのステップを組み合わせます。セグメントは、コンピューティングノードスライスによって実行可能な最小のコンパイル単位です。スライスは、Amazon Redshift の並列処理単位です。
-
ストリームは、使用可能なコンピューティングノードスライスにパッケージ化されるセグメントのコレクションです。ストリーム内のセグメントは、ノードスライス間で並列に実行されます。したがって、同じセグメントからの同じステップも複数のスライスで並行して実行されます。
-
-
コードジェネレーターは変換されたプランを受け取り、セグメントごとに C++ 関数を生成します。
-
生成された C++ 関数は GNU コンパイラコレクションによってコンパイルされ、O (
.o) ファイルに変換されます。 -
コンパイルされたコード (O ファイル) が実行されます。コンパイルされたコードの実行は解釈されたコードよりも速く、使用するコンピューティングキャパシティも少なくなります。
-
その後、コンパイルされた O ファイルがコンピューティングノードにブロードキャストされます。
-
各コンピューティングノードは、複数のコンピューティングスライスで構成されます。コンピューティングスライスはクエリセグメントを並列で実行します。Amazon Redshift は、最適化されたネットワーク通信、メモリ、ディスク管理を活用して、あるクエリプランステップから次のクエリプランステップに中間結果を渡します。これにより、クエリの実行を高速化することもできます。以下の点を考慮してください。
-
ステップ 6、7、8、9、10、11 はストリームごとに 1 回行われます。
-
エンジンは 1 つのストリームの実行可能なセグメントを作成し、これらのセグメントをコンピューティングノードに送信します。
-
前のストリームのセグメントが完了すると、エンジンは次のストリームのセグメントを生成します。これにより、エンジンは前のストリームで何が発生したかを分析し (操作がディスクベースであったかどうかなど)、次のストリーム内におけるセグメントの生成に影響を与えることができます。
-
-
コンピューティングノードが完了すると、クエリ結果はリーダーノードに返され、最終処理が行われます。リーダーノードは、データを 1 つの結果セットにマージし、必要なソートまたは集約に対処します。
-
リーダーノードは結果をクライアントに返します。
次の図は、ストリーム、セグメント、ステップ、コンピューティングノードスライスの実行ワークフローを示しています。以下に留意してください。
-
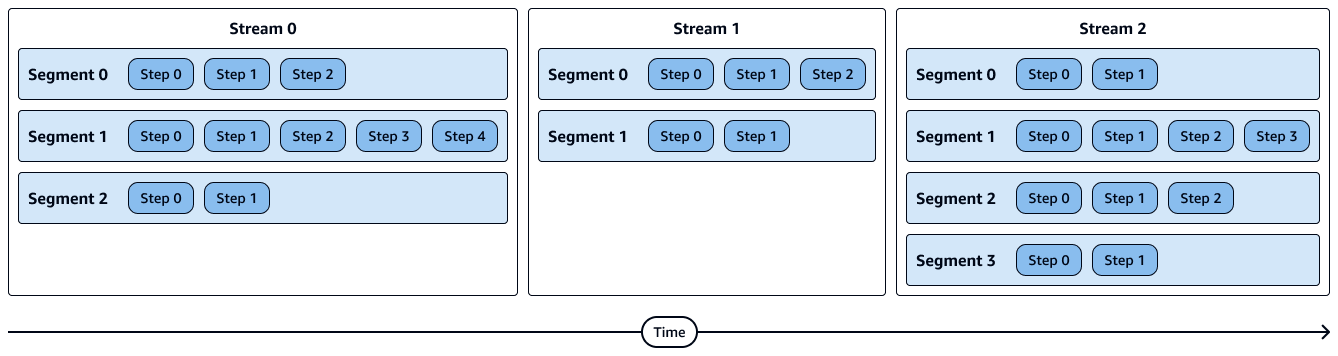
セグメント内のステップは順番に実行されます。
-
ストリーム内のセグメントは並行して実行されます。
-
ストリームは順番に実行されます。
-
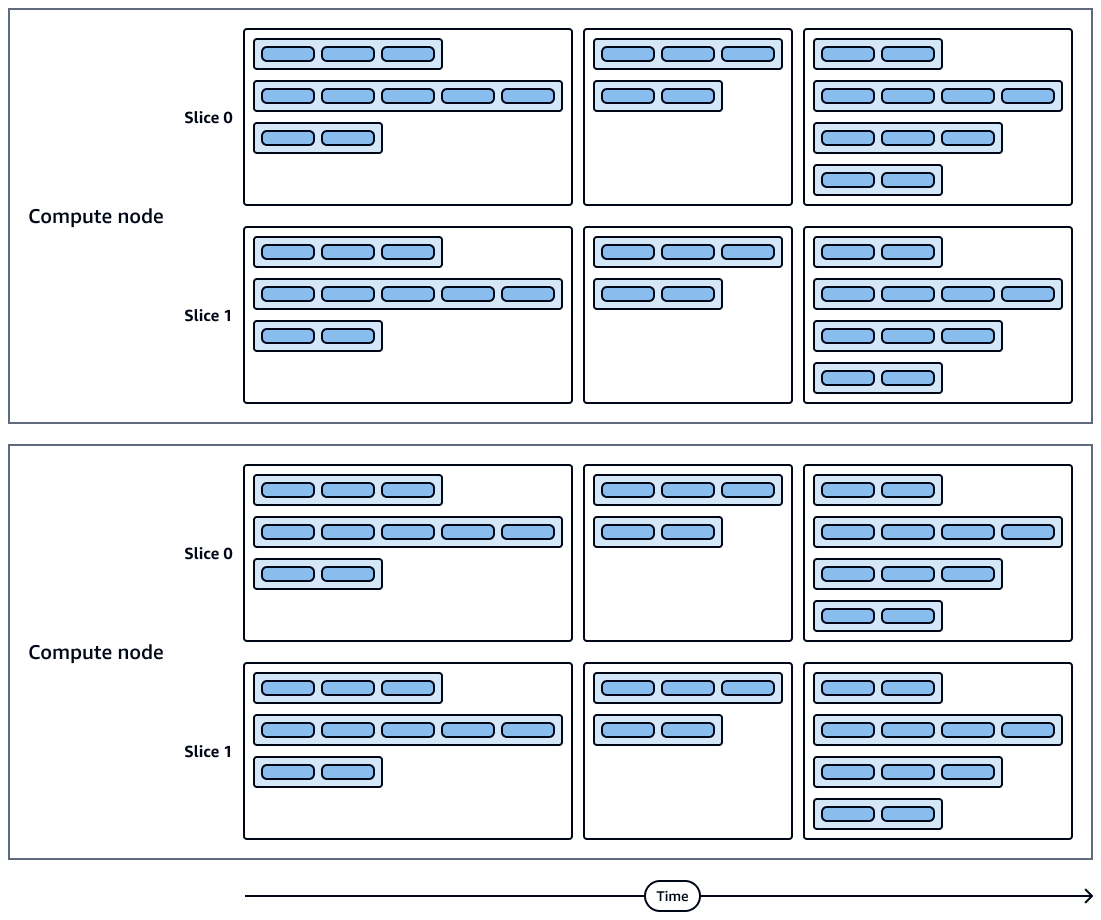
コンピューティングノードスライスは並列で実行されます。
次の図は、ストリーム、セグメント、ステップを視覚的に示しています。各セグメントには複数のステップが含まれ、各ストリームには複数のセグメントが含まれます。
次の図は、クエリ実行とコンピューティングノードスライスの視覚的表現を示しています。各コンピューティングノードには、複数のスライス、ストリーム、セグメント、ステップが含まれます。
追加の考慮事項
クエリ処理については、次の点を考慮することをお勧めします。
-
キャッシュされたコンパイル済みコードは、同じクラスター上のセッション間で共有されるため、多くの場合、パラメータが異なる場合でも、同じクエリの後続の実行が高速になります。
-
クエリのベンチマークを行うときは、常にクエリの 2 回目の実行時間を比較することをお勧めします。最初の実行時間には、コードのコンパイルのオーバーヘッドが含まれるためです。詳細については、「Amazon Redshift のクエリのベストプラクティス」ガイドの「クエリのパフォーマンス要因」を参照してください。
-
コンピューティングノードは、必要に応じてクエリの実行中にリーダーノードに一部のデータを返す場合があります。例えば、
LIMIT句を含むサブクエリがある場合、制限はリーダーノードに適用され、その後に処理するためにデータがクラスター全体に再分散されます。
