翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ユースケース: 拡張された患者データを使用した医療インテリジェンスアプリケーションの構築
生成 AI は、臨床機能と管理機能の両方を強化することで、患者のケアとスタッフの生産性を高めるのに役立ちます。ソノグラムの解釈などの AI 駆動型画像分析は、診断プロセスを高速化し、精度を向上させます。タイムリーな医療介入をサポートする重要なインサイトを提供できます。
生成 AI モデルをナレッジグラフと組み合わせると、電子患者レコードの時系列整理を自動化できます。これにより、臨床医と患者のやり取り、症状、診断、検査結果、画像分析からのリアルタイムデータを統合できます。これにより、医師には包括的な患者データが提供されます。このデータは、医師がより正確でタイムリーな医療上の意思決定を行い、患者の成果と医療提供者の生産性の両方を向上させるのに役立ちます。
ソリューションの概要
AI は、患者データと医療知識を合成して貴重なインサイトを提供することで、医師と臨床医を強化できます。この検索拡張生成 (RAG) ソリューションは、何百万もの臨床インタラクションから包括的な患者データと知識のセットを消費する医療インテリジェンスエンジンです。生成 AI の能力を活用して、患者ケアを改善するための証拠ベースのインサイトを作成します。これは、臨床ワークフローを強化し、エラーを減らし、患者の成果を向上させるように設計されています。
このソリューションには、LLMs。この機能により、医療担当者が同様の診断画像を手動で検索し、診断結果を分析しなければならない時間が短縮されます。
次の図は、このソリューションのend-to-end-workflowを示しています。Amazon Neptune、Amazon SageMaker AI、Amazon OpenSearch Service、Amazon Bedrock の基盤モデルを使用します。Neptune の医療知識グラフを操作するコンテキスト検索エージェントでは、Amazon Bedrock エージェントとLangChainエージェントのいずれかを選択できます。
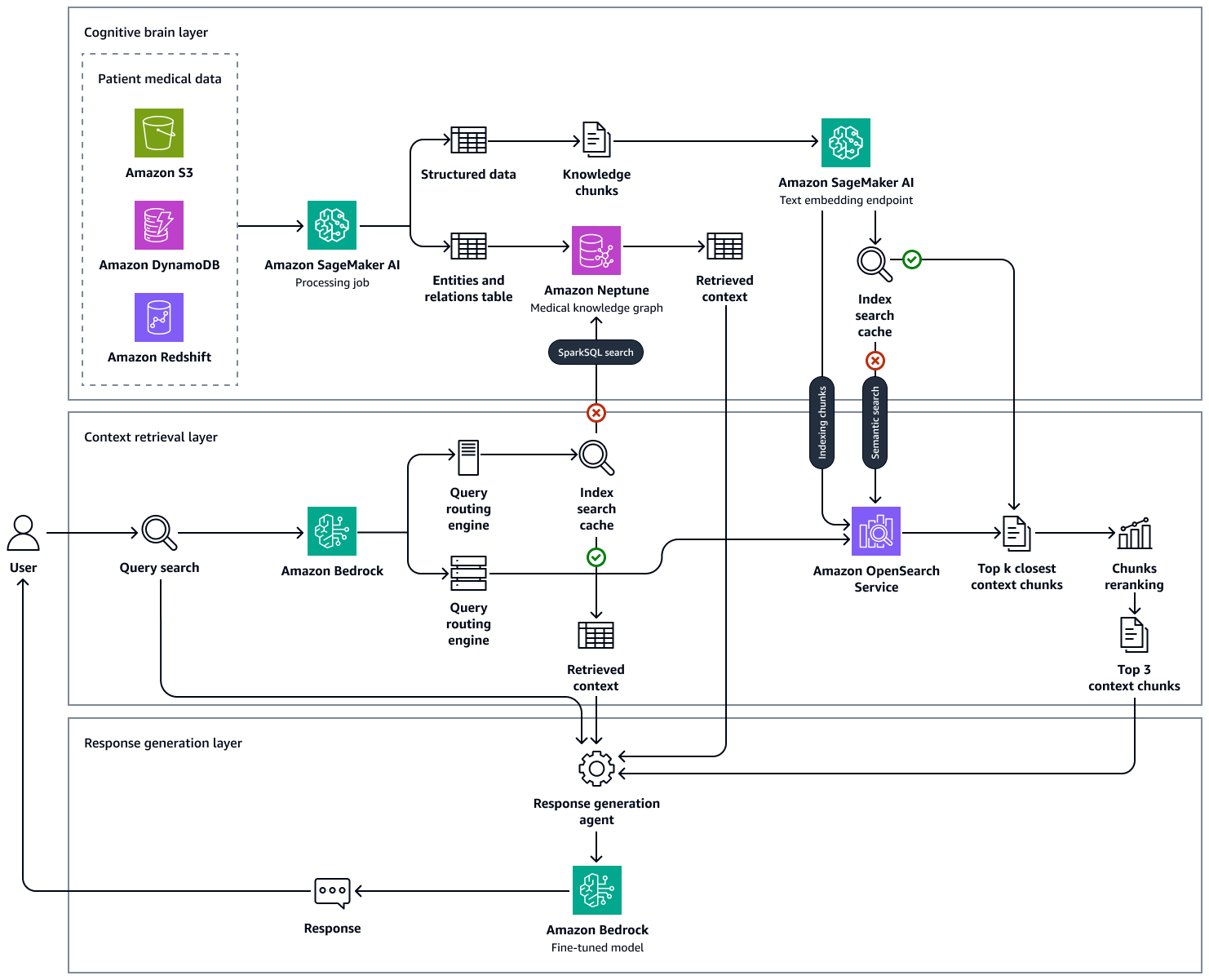
サンプル医療質問を用いた実験では、Neptune、臨床ナレッジベースを格納する OpenSearch ベクトルデータベース、Amazon Bedrock LLMs で維持されているナレッジグラフを使用してアプローチによって生成された最終的なレスポンスが事実に基づいており、誤検出を減らし、真陽性を増やすことではるかに正確であることがわかりました。このソリューションは、患者の健康状態に関する証拠ベースのインサイトを生成し、臨床ワークフローを強化し、エラーを減らし、患者の成果を向上させることを目的としています。
このソリューションの構築は、次のステップで構成されます。
ステップ 1: データを検出する
ヘルスケア AI 駆動型ソリューションの開発をサポートするために使用できるオープンソースの医療データセットは多数あります。このようなデータセットの 1 つは、MIMIC-IV データセット
また、研究目的で特別にキュレートされた、注釈付きで識別されていない患者の退床サマリーを提供するデータセットを使用することもできます。放出サマリーデータセットは、エンティティ抽出を試すのに役立ちます。これにより、テキストから主要な医療エンティティ (状態、処置、薬剤など) を識別できます。ステップ 2: 医療知識グラフを構築するこのガイドでは、MIMIC-IV および放出サマリーデータセットから抽出された構造化データを使用して医療知識グラフを作成する方法について説明します。この医療知識グラフは、医療専門家向けの高度なクエリおよび意思決定支援システムのバックボーンとして機能します。
テキストベースのデータセットに加えて、画像データセットを使用できます。例えば、筋骨格X線画像 (MURA) データセット
ステップ 2: 医療知識グラフを構築する
大規模なナレッジベースに基づいて意思決定支援システムを構築したい医療組織にとって、重要な課題は、臨床ノート、医学ジャーナル、解雇概要、その他のデータソースに存在する医療エンティティを見つけて抽出することです。また、抽出されたエンティティ、属性、関係を効果的に使用するには、これらの医療記録から時間的関係、件名、確実性の評価をキャプチャする必要があります。
最初のステップは、Amazon Bedrock の Llama 3 などの基盤モデルに数ショットのプロンプトを使用して、非構造化医療テキストから医療概念を抽出することです。少数のショットプロンプトは、LLM に同様のタスクの実行を求める前に、タスクと必要な出力を示す少数の例を提供する場合です。LLM ベースの医療エンティティエクストラクタを使用すると、構造化されていない医療テキストを解析し、医療知識エンティティの構造化データ表現を生成できます。ダウンストリーム分析と自動化のために患者属性を保存することもできます。エンティティ抽出プロセスには、次のアクションが含まれます。
-
疾患、薬剤、医療デバイス、投与量、薬剤頻度、薬剤期間、症状、医療処置、およびそれらの臨床的な関連属性などの医療概念に関する情報を抽出します。
-
抽出されたエンティティ、サブジェクト、確実性評価間の時間的関係などの機能機能をキャプチャします。
-
次のような標準医療語彙を拡張します。
-
RxNorm データベースからの概念識別子 (RxCUI) RxNorm
-
Systematized Nomenclature of Medicine, Clinical Terms (SNOMED CT)
の概念
-
-
退床メモを要約し、トランスクリプトから医療インサイトを取得します。
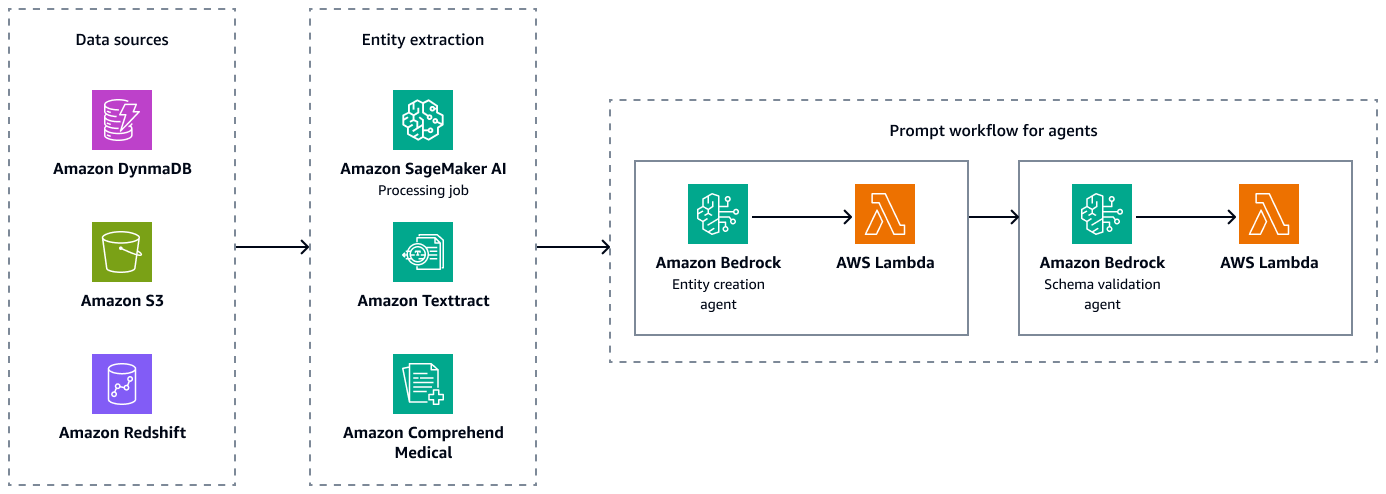
次の図は、エンティティ、属性、および関係の有効なペアの組み合わせを作成するためのエンティティ抽出とスキーマ検証の手順を示しています。退床サマリーや患者メモなどの非構造化データを Amazon Simple Storage Service (Amazon S3) に保存できます。エンタープライズリソースプランニング (ERP) データ、電子患者レコード、ラボ情報システムなどの構造化データを Amazon Redshift と Amazon DynamoDB に保存できます。Amazon Bedrock エンティティ作成エージェントを構築できます。このエージェントは、Amazon SageMaker AI データ抽出パイプライン、Amazon Textract、Amazon Comprehend Medical などのサービスを統合して、構造化データソースと非構造化データソースからエンティティ、関係、属性を抽出できます。最後に、Amazon Bedrock スキーマ検証エージェントを使用して、抽出されたエンティティと関係が事前定義されたグラフスキーマに準拠していること、ノードエッジ接続と関連プロパティの整合性が維持されていることを確認します。
エンティティ、リレーション、属性を抽出して検証した後、それらをリンクして subject-object-predicate トリプレットを作成できます。次の図に示すように、このデータを Amazon Neptune グラフデータベースに取り込みます。グラフデータベースは、データ項目間の関係を保存してクエリするように最適化されています。
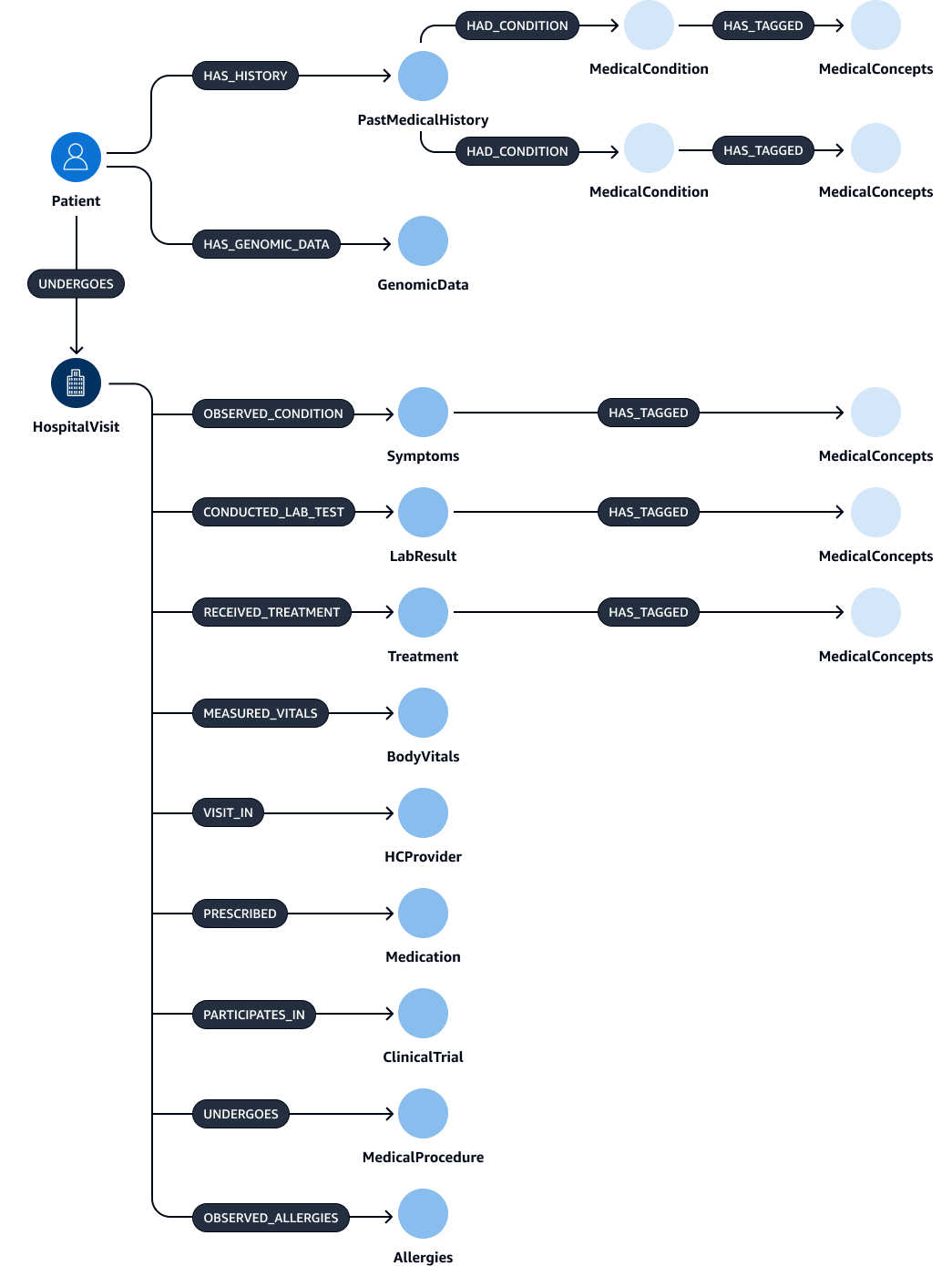
このデータを使用して包括的なナレッジグラフを作成できます。ナレッジグラフHospitalVisit、、PastMedicalHistorySymptomsMedicationMedicalProcedures、および のメジャーノードを持つナレッジグラフを作成できますTreatment。
次の表に、排出ノートから抽出できるエンティティとその属性を示します。
| エンティティ | 属性 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
次の表に、エンティティが持つ可能性のある関係とその対応する属性を示します。たとえば、Patientエンティティは [UNDERGOES]関係を持つHospitalVisitエンティティに接続できます。この関係の属性は ですVisitDate。
| サブジェクトエンティティ | 関係 | オブジェクトエンティティ | 属性 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
なし |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
なし |
|
|
|
なし |
|
|
|
なし |
|
|
|
なし |
ステップ 3: 医療知識グラフをクエリするためのコンテキスト検索エージェントを構築する
医療グラフデータベースを構築した後、次のステップはグラフ操作用のエージェントを構築することです。エージェントは、臨床医または臨床医が入力するクエリの適切で必要なコンテキストを取得します。ナレッジグラフからコンテキストを取得するこれらのエージェントを設定するには、いくつかのオプションがあります。
グラフインタラクション用の Amazon Bedrock エージェント
Amazon Bedrock エージェントは、Amazon Neptune グラフデータベースとシームレスに連携します。Amazon Bedrock アクショングループを使用して高度なインタラクションを実行できます。アクショングループは、Neptune openCypher クエリを実行する AWS Lambda 関数を呼び出してプロセスを開始します。
ナレッジグラフのクエリには、直接クエリの実行とコンテキスト埋め込みを使用したクエリの 2 つの異なるアプローチを使用できます。これらのアプローチは、特定のユースケースとランク付け基準に応じて、個別に適用することも組み合わせることもできます。両方のアプローチを組み合わせることで、より包括的なコンテキストを LLM に提供できるため、結果を向上させることができます。以下は、2 つのクエリ実行アプローチです。
-
埋め込みなしで直接 Cypher クエリを実行する – Lambda 関数は、埋め込みベースの検索なしで Neptune に対して直接クエリを実行します。このアプローチの例を次に示します。
MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason = 'Acute Diabetes' AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformation -
埋め込み検索を使用した直接 Cypher クエリの実行 – Lambda 関数は埋め込み検索を使用してクエリ結果を強化します。このアプローチは、データの高密度ベクトル表現である埋め込みを組み込むことで、クエリの実行を強化します。埋め込みは、クエリにセマンティック類似性や完全一致を超える広範な理解が必要な場合に特に役立ちます。事前トレーニング済みモデルまたはカスタムトレーニング済みモデルを使用して、病状ごとに埋め込みを生成できます。このアプローチの例を次に示します。
CALL { WITH "Acute Diabetes" AS query_term RETURN search_embedding(query_term) AS similar_reasons } MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason IN similar reasons AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformationこの例では、
search_embedding("Acute Diabetes")関数は意味的に「Acute" に近い条件を取得します。これにより、クエリは、前骨茎や異化症候群などの状態を持つ患者も検索できます。
次の図は、医療知識グラフの Cypher クエリを実行するために Amazon Bedrock エージェントが Amazon Neptune とやり取りする方法を示しています。
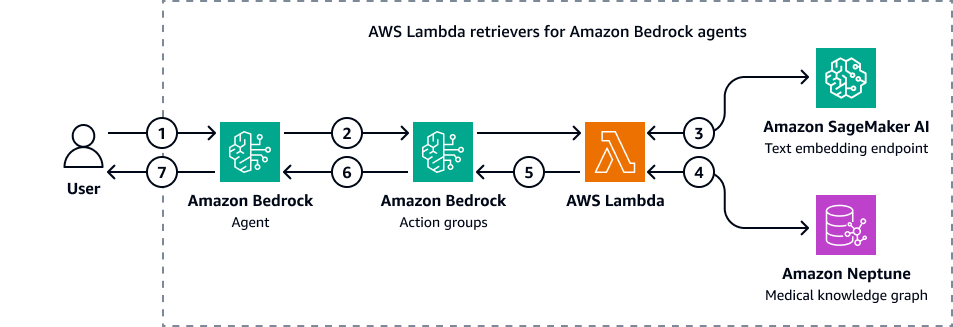
この図表は、次のワークフローを示しています:
-
ユーザーは Amazon Bedrock エージェントに質問を送信します。
-
Amazon Bedrock エージェントは、質問および入力フィルター変数を Amazon Bedrock アクショングループに渡します。これらのアクショングループには、Amazon SageMaker AI テキスト埋め込みエンドポイントと Amazon Neptune 医療知識グラフを操作する AWS Lambda 関数が含まれています。
-
Lambda 関数は SageMaker AI テキスト埋め込みエンドポイントと統合され、openCypher クエリ内でセマンティック検索を実行します。基になるLangChainエージェントを使用して、自然言語クエリを openCypher クエリに変換します。
-
Lambda 関数は、Neptune 医療ナレッジグラフに正しいデータセットをクエリし、Neptune 医療ナレッジグラフから出力を受け取ります。
-
Lambda 関数は、Neptune から Amazon Bedrock アクショングループに結果を返します。
-
Amazon Bedrock アクショングループは、取得したコンテキストを Amazon Bedrock エージェントに送信します。
-
Amazon Bedrock エージェントは、元のユーザークエリとナレッジグラフから取得したコンテキストを使用してレスポンスを生成します。
LangChain グラフインタラクションのエージェント
Neptune LangChainと統合して、グラフベースのクエリと取得を有効にすることができます。このアプローチでは、Neptune のグラフデータベース機能を使用することで、AI 主導のワークフローを強化できます。カスタムリLangChainトリーバーは仲介として機能します。Amazon Bedrock の基盤モデルは、直接 Cypher クエリとより複雑なグラフアルゴリズムの両方を使用して Neptune とやり取りできます。
カスタムリトリーバーを使用して、LangChainエージェントが Neptune グラフアルゴリズムとやり取りする方法を絞り込むことができます。たとえば、数ショットプロンプトを使用できます。これにより、特定のパターンや例に基づいて基盤モデルのレスポンスを調整できます。LLM で識別されたフィルターを適用してコンテキストを絞り込み、レスポンスの精度を向上させることもできます。これにより、複雑なグラフデータを操作する際の全体的な取得プロセスの効率と精度を向上させることができます。
次の図は、カスタムLangChainエージェントが Amazon Bedrock 基盤モデルと Amazon Neptune 医療知識グラフ間のインタラクションをオーケストレーションする方法を示しています。
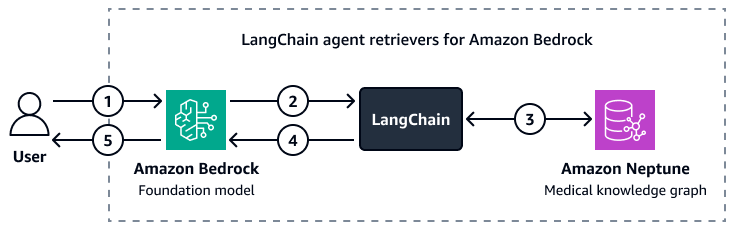
この図表は、次のワークフローを示しています:
-
ユーザーは Amazon Bedrock とLangChainエージェントに質問を送信します。
-
Amazon Bedrock 基盤モデルは、LangChainエージェントによって提供される Neptune スキーマを使用して、ユーザーの質問に対するクエリを生成します。
-
LangChain エージェントは、Amazon Neptune 医療知識グラフに対してクエリを実行します。
-
LangChain エージェントは、取得したコンテキストを Amazon Bedrock 基盤モデルに送信します。
-
Amazon Bedrock 基盤モデルは、取得したコンテキストを使用して、ユーザーの質問に対する回答を生成します。
ステップ 4: リアルタイムの記述的データのナレッジベースを作成する
次に、リアルタイムの記述的な臨床医と患者のやり取りに関するメモ、診断画像評価、およびラボ分析レポートのナレッジベースを作成します。このナレッジベースはベクトルデータベース
OpenSearch Service 医療ナレッジベースの使用
Amazon OpenSearch Service は、大量の高次元医療データを管理できます。これは、高性能な検索とリアルタイム分析を容易にするマネージドサービスです。RAG アプリケーションのベクトルデータベースとして最適です。OpenSearch Service は、医療記録、研究記事、臨床ノートなど、大量の非構造化または半構造化データを管理するバックエンドツールとして機能します。高度なセマンティック検索機能は、コンテキストに関連する情報を取得するのに役立ちます。これにより、臨床意思決定支援システム、患者クエリ解決ツール、医療知識管理システムなどのアプリケーションで特に役立ちます。例えば、臨床医は特定の症状や治療プロトコルに一致する関連する患者データや研究研究をすばやく見つけることができます。これにより、臨床医はup-to-date関連情報に基づいて意思決定を行うことができます。
OpenSearch Service は、リアルタイムのデータインデックス作成とクエリをスケーリングして処理できます。これにより、正確な情報へのタイムリーなアクセスが重要な動的な医療環境に最適です。さらに、医療画像や医師のメモなど、複数の入力を必要とする検索に最適なマルチモーダル検索機能を備えています。ヘルスケアアプリケーションに OpenSearch Service を実装する場合、データのインデックス作成と取得を最適化するために、正確なフィールドとマッピングを定義することが重要です。フィールドは、患者記録、医療履歴、診断コードなど、個々のデータを表します。マッピングは、これらのフィールドの保存方法 (埋め込み形式または元の形式) とクエリの方法を定義します。ヘルスケアアプリケーションでは、構造化データ (数値テスト結果など)、半構造化データ (患者メモなど)、非構造化データ (医療画像など) など、さまざまなデータ型に対応するマッピングを確立することが不可欠です。
OpenSearch Service では、厳選されたプロンプトを通じてフルテキストのニューラル検索
RAG アーキテクチャの作成
Amazon Bedrock エージェントを使用して OpenSearch Service の医療ナレッジベースをクエリするカスタマイズされた RAG ソリューションをデプロイできます。これを行うには、OpenSearch Service とやり取りしてクエリできる AWS Lambda 関数を作成します。Lambda 関数は、SageMaker AI テキスト埋め込みエンドポイントにアクセスして、ユーザーの入力質問を埋め込みます。Amazon Bedrock エージェントは、追加のクエリパラメータを入力として Lambda 関数に渡します。関数は OpenSearch Service の医療ナレッジベースをクエリし、関連する医療コンテンツを返します。Lambda 関数を設定したら、Amazon Bedrock エージェント内のアクショングループとして追加します。Amazon Bedrock エージェントは、ユーザーの入力を受け取り、必要な変数を識別し、変数と質問を Lambda 関数に渡してから、関数を開始します。関数は、基盤モデルがユーザーの質問に対してより正確な回答を提供するのに役立つコンテキストを返します。
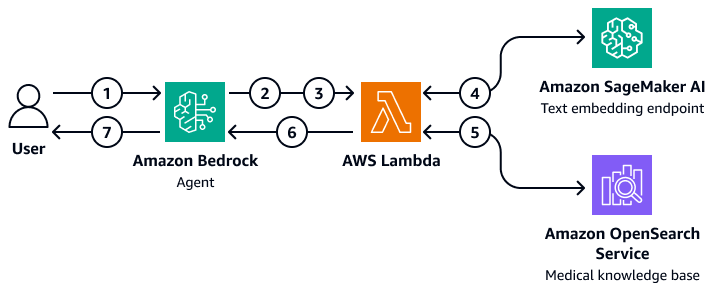
この図表は、次のワークフローを示しています:
-
ユーザーが Amazon Bedrock エージェントに質問を送信します。
-
Amazon Bedrock エージェントは、開始するアクショングループを選択します。
-
Amazon Bedrock エージェントは AWS Lambda 関数を開始し、パラメータを渡します。
-
Lambda 関数は、Amazon SageMaker AI テキスト埋め込みモデルを開始してユーザー質問を埋め込みます。
-
Lambda 関数は、埋め込みテキストと追加のパラメータとフィルターを Amazon OpenSearch Service に渡します。Amazon OpenSearch Service は医療ナレッジベースをクエリし、結果を Lambda 関数に返します。
-
Lambda 関数は、結果を Amazon Bedrock エージェントに返します。
-
Amazon Bedrock エージェントの基盤モデルは、結果に基づいてレスポンスを生成し、ユーザーにレスポンスを返します。
より複雑なフィルタリングが関係する状況では、カスタムリLangChainトリーバーを使用できます。に直接ロードされる OpenSearch Service ベクトル検索クライアントを設定して、このリトリーバーを作成しますLangChain。このアーキテクチャでは、フィルターパラメータを作成するためにより多くの変数を渡すことができます。リトリーバーを設定したら、Amazon Bedrock モデルとリトリーバーを使用して、取得に関する質問への回答チェーンを設定します。このチェーンは、ユーザー入力と潜在的なフィルターをリトリーバーに渡すことで、モデルとリトリーバー間のインタラクションを調整します。リトリーバーは、基盤モデルがユーザーの質問に答えるのに役立つ関連コンテキストを返します。
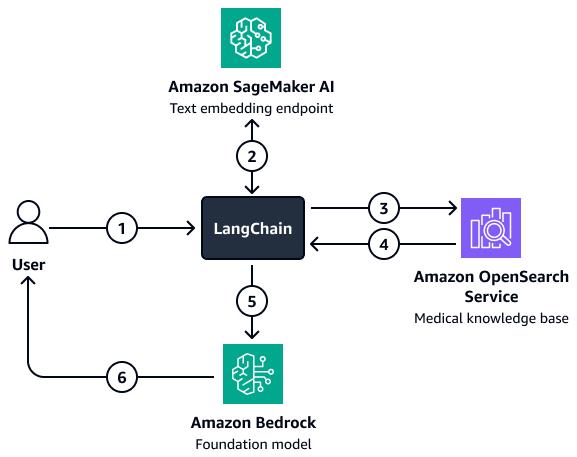
この図表は、次のワークフローを示しています:
-
ユーザーがリLangChainトリーバーエージェントに質問を送信します。
-
リLangChainトリーバーエージェントは、質問を埋め込むために Amazon SageMaker AI テキスト埋め込みエンドポイントに質問を送信します。
-
リLangChainトリーバーエージェントは埋め込みテキストを Amazon OpenSearch Service に渡します。
-
Amazon OpenSearch Service は、取得したドキュメントをLangChainリトリーバーエージェントに返します。
-
リLangChainトリーバーエージェントは、ユーザーの質問と取得したコンテキストを Amazon Bedrock 基盤モデルに渡します。
-
基盤モデルはレスポンスを生成し、ユーザーに送信します。
ステップ 5: LLMsを使用して医療上の質問に回答する
前のステップは、患者の医療記録を取得し、関連する薬剤や潜在的な診断を要約できる医療インテリジェンスアプリケーションを構築するのに役立ちます。次に、生成レイヤーを構築します。このレイヤーは、Llama 3 などの Amazon Bedrock の LLM の生成機能を使用して、アプリケーションの出力を補強します。
臨床医がクエリを入力すると、アプリケーションのコンテキスト取得レイヤーはナレッジグラフから取得プロセスを実行し、患者の履歴、人口統計、症状、診断、および結果に関連する上位レコードを返します。また、ベクトルデータベースから、リアルタイムの記述的な医師と患者のやり取りに関するメモ、診断画像評価のインサイト、ラボ分析レポートの概要、医学研究や学術書の膨大なコーパスからのインサイトも取得します。これらの取得された上位の結果、臨床医のクエリ、プロンプト (クエリの性質に基づいて回答をキュレートするように調整) は、Amazon Bedrock の基盤モデルに渡されます。これはレスポンス生成レイヤーです。LLM は、取得したコンテキストを使用して、臨床医のクエリに対するレスポンスを生成します。次の図は、このソリューションのステップのend-to-endのワークフローを示しています。
Amazon Bedrock では、Llama 3 などの事前トレーニング済みの基盤モデルを、医療インテリジェンスアプリケーションが処理する必要があるさまざまなユースケースに使用できます。特定のタスクに最も効果的な LLM は、ユースケースによって異なります。例えば、事前トレーニング済みのモデルは、患者と医師の会話を要約し、薬剤や患者の履歴を検索し、社内の医療データセットや科学的知識からインサイトを取得するのに十分です。ただし、リアルタイムの検査評価、医療処置の推奨事項、患者の成果の予測など、他の複雑なユースケースでは、微調整された LLM が必要になる場合があります。LLM は、医療ドメインデータセットでトレーニングすることで微調整できます。特定の、または複雑なヘルスケアやライフサイエンスの要件により、これらの微調整されたモデルの開発が促進されます。
LLM の微調整または医療ドメインデータでトレーニングされた既存の LLM の選択の詳細については、「Using large language models for healthcare and life science use cases」を参照してください。
AWS Well-Architected フレームワークへの調整
このソリューションは、次のように AWS Well-Architected フレームワーク
-
運用上の優秀性 – アーキテクチャは、効率的なモニタリングと更新のために切り離されます。Amazon Bedrock エージェントと は、ツールを迅速にデプロイおよびロールバックする AWS Lambda のに役立ちます。
-
セキュリティ – このソリューションは、HIPAA などの医療規制に準拠するように設計されています。暗号化、きめ細かなアクセスコントロール、Amazon Bedrock ガードレールを実装して、患者データを保護することもできます。
-
Amazon OpenSearch Service や Amazon Bedrock などの信頼性 AWS マネージドサービスは、継続的なモデルインタラクションのためのインフラストラクチャを提供します。
-
パフォーマンス効率 – RAG ソリューションは、最適化されたセマンティック検索と Cypher クエリを使用して関連データをすばやく取得し、エージェントルーターはユーザークエリに最適なルートを特定します。
-
コストの最適化 – Amazon Bedrock および RAG アーキテクチャのpay-per-tokenモデルにより、推論とトレーニング前のコストを削減できます。
-
持続可能性 — サーバーレスインフラストラクチャとpay-per-tokenコンピューティングを使用すると、リソースの使用量が最小限に抑えられ、持続可能性が向上します。
