翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
での結合ヒントの使用 Spark SQL
Spark3.0 では、実行時にSpark使用する結合アルゴリズムのタイプを指定できます。結合戦略ヒント 、、BROADCASTMERGESHUFFLE_HASH、および はSHUFFLE_REPLICATE_NL、指定された各リレーションを別のリレーションに結合するときに、ヒント戦略を使用するSparkように に指示します。このセクションでは、結合戦略のヒントについて詳しく説明します。
ブロードキャスト
Broadcast Hash 結合では、データセットの 1 つが他のデータセットよりも大幅に小さくなります。小さいデータセットはメモリに収まるため、クラスター内のすべてのエグゼキュターにブロードキャストされます。データがブロードキャストされると、標準のハッシュ結合が実行されます。Broadcast Hash 結合は 2 つのステップで行われます。
-
Broadcast – 小さいデータセットは、クラスター内のすべてのエグゼキュターにブロードキャストされます。
-
ハッシュ結合 – 小さいデータセットはすべてのエグゼキュターでハッシュされ、大きいデータセットに結合されます。
sort または mergeオペレーションはありません。大きなファクトテーブルを、スタースキーマ結合の実行に使用される小さなディメンションテーブルで結合する場合、Broadcast Hash は最速の結合アルゴリズムです。次の例は、ブロードキャストハッシュ結合の仕組みを示しています。ヒントを含む結合側は、 spark.sql.autoBroadcastJoinThresholdプロパティで指定されたサイズ制限に関係なくブロードキャストされます。結合の両側にブロードキャストヒントがある場合、サイズが小さいもの (統計に基づく) がブロードキャストされます。spark.sql.autoBroadcastJoinThreshold プロパティのデフォルト値は 10 MB です。これにより、結合の実行時にすべてのワーカーノードにブロードキャストされるテーブルの最大サイズがバイト単位で設定されます。
次の例では、クエリ、物理EXPLAINプラン、およびクエリの実行にかかる時間を示します。2 番目のEXPLAIN計画例に示すように、BROADCASTJOINヒントを使用してブロードキャスト結合を強制する場合、クエリの処理時間を短縮できます。
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
両方のデータセットが大きく、メモリに収まらない場合は、シャッフルソートマージ結合が推奨されます。名前が示すように、この結合には次の 3 つのフェーズが含まれます。
-
シャッフルフェーズ – 結合クエリの両方のデータセットがシャッフルされます。
-
ソートフェーズ – レコードは両側の結合キーでソートされます。
-
マージフェーズ – 結合条件の両側は、結合キーに基づいて反復されます。
次の画像は、シャッフルソートマージ結合の有向非巡回グラフ (DAG) の視覚化を示しています。両方のテーブルは最初の 2 つのステージで読み取られます。次のステージ (ステージ 17) では、シャッフルされ、ソートされ、最後にマージされます。
注: このイメージの一部のステージは、これらのステップが前のステージで完了したため、スキップ済みとして表示されます。そのデータはキャッシュまたは保持され、これらのステージで使用されます。 |

以下は、ソートマージ結合を示す物理プランです。
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
シャッフルハッシュ結合は、名前が示すように、両方のデータセットをシャッフルすることで機能します。両側の同じキーは、同じパーティションまたはタスクになります。データがシャッフルされると、2 つのデータセットのうち最小のデータセットがバケットにハッシュされ、パーティション内でハッシュ結合が実行されます。データセット全体がブロードキャストされないため、シャッフルハッシュ結合はブロードキャストハッシュ結合とは異なります。シャッフルハッシュ結合は 2 つのフェーズに分かれています。
-
シャッフルフェーズ – 両方のデータセットがシャッフルされます。
-
ハッシュ結合フェーズ – データの小さい側がハッシュされ、バケット化され、すべてのパーティションの大きい側とハッシュ結合されます。
パーティション内のシャッフルハッシュ結合ではソートは必要ありません。次の図は、シャッフルハッシュ結合のフェーズを示しています。データは最初に読み取られ、次にシャッフルされ、ハッシュが作成されて結合に使用されます。
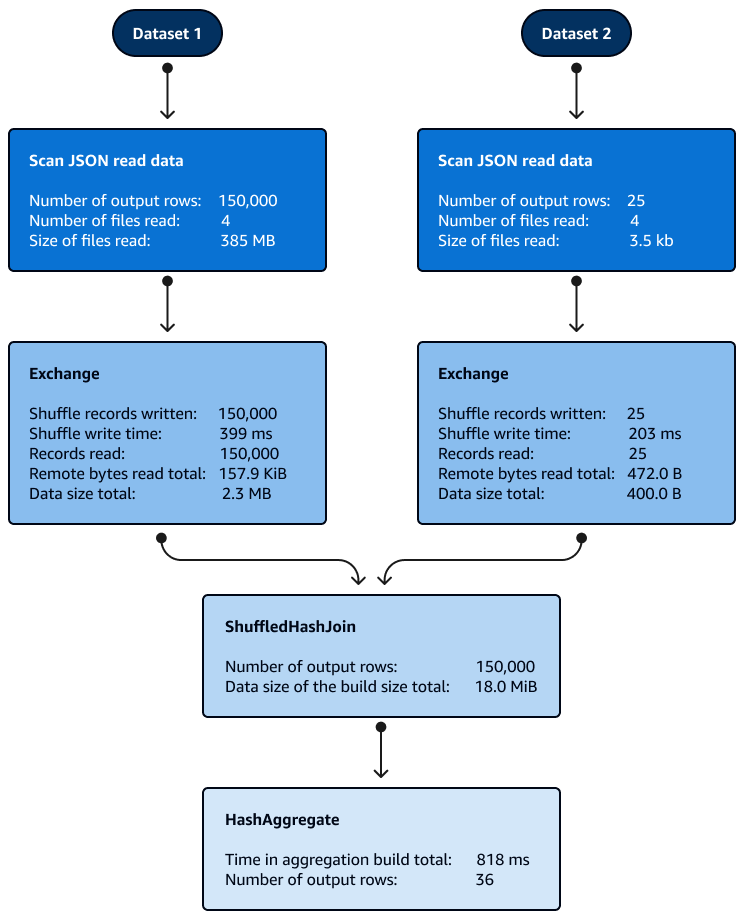
デフォルトでは、オプティマイザはブロードキャストハッシュ結合を使用できないときにシャッフルハッシュ結合を選択します。ブロードキャストハッシュ結合のしきい値サイズ (spark.sql.autoBroadcastJoinThreshold) と選択したシャッフルパーティションの数 (spark.sql.shuffle.partitions) に基づいて、論理 SQL の 1 つのパーティションがローカルハッシュテーブルを構築するのに十分な大きさである場合、シャッフルハッシュ結合を使用します。
SHUFFLE_REPLICATE_NL
デカルト積結合とも呼ばれるShuffle-and-Replicateネストされたループ結合は、データセットがブロードキャストされていない点を除いて、ブロードキャストハッシュ結合と非常によく似ています。
この結合アルゴリズムでは、同じキーを持つレコードが同じパーティションに送信されないため、シャッフルは真のシャッフルを参照しません。代わりに、両方のデータセットのパーティション全体がネットワーク経由でコピーされます。データセットのパーティションが使用可能になると、ネストされたループ結合が実行されます。最初のデータセットにレコードXの数があり、各パーティションの 2 番目のデータセットにレコードYの数がある場合、2 番目のデータセットの各レコードは、最初のデータセットのすべてのレコードに結合されます。これは、すべてのパーティションでループX × Y時間で継続されます。
