翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
最新のヘルスデータ戦略の実装例
AWS は、データに対するアジャイルアプローチをサポートするデータプラットフォームを理解して構築するために、医療組織が使用できるリファレンスアーキテクチャを提供します。次のリファレンスアーキテクチャは、ヘルスケア用のデータメッシュアーキテクチャ
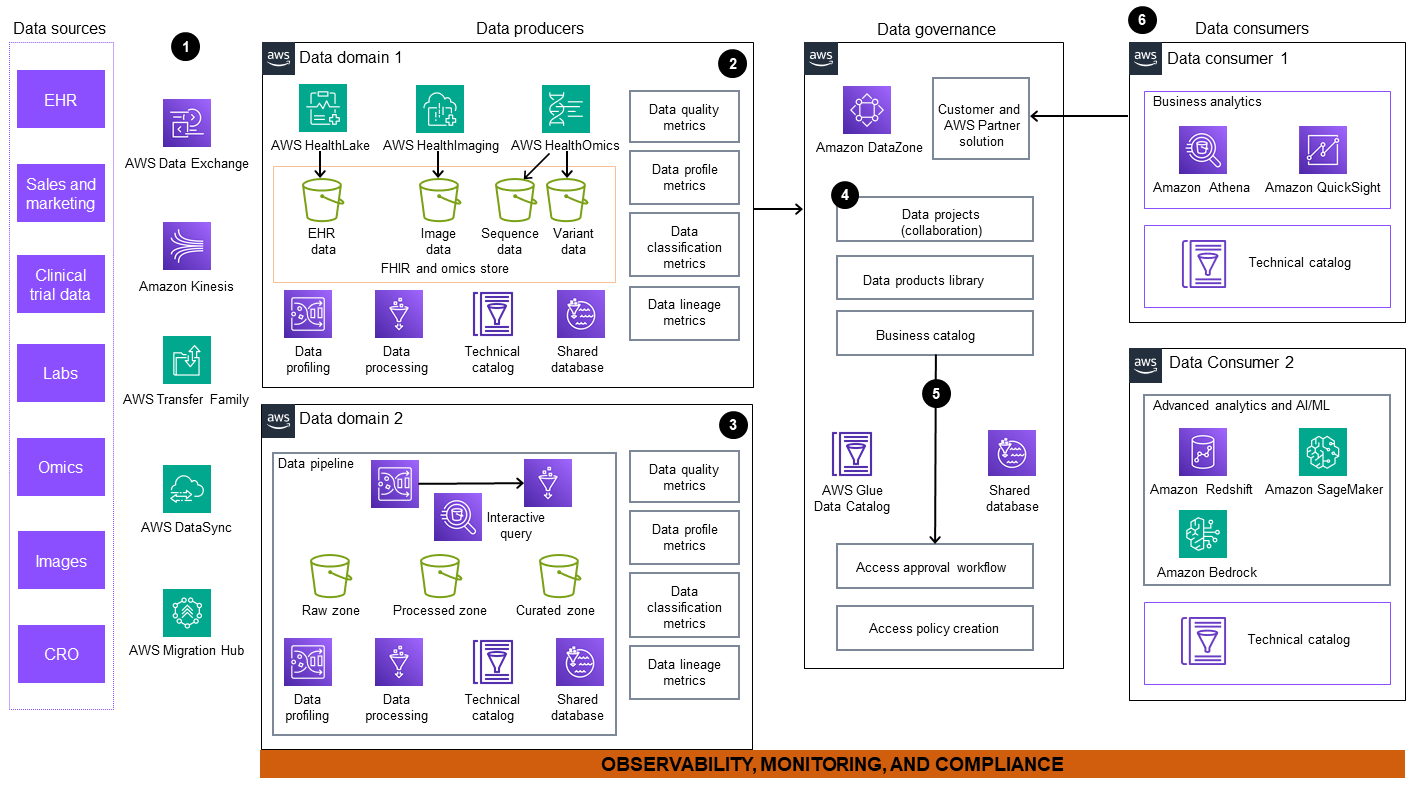
アーキテクチャ図には、次のコンポーネントが含まれています。
-
データは、外部データソースと内部データソースから取り込まれます。これらのソースには、電子医療記録 (EHR) システム、ラボ、シーケンス施設、画像センターなどがありますが、これらに限定されません。 AWS は、AWS Data Exchange
、Amazon Kinesis 、、AWS Transfer Family 、AWS DataSync AWS Migration Hub 、AWS HealthLake 、AWS Glue 、 (ETL) などの一連のサービスを提供しています。これらのサービスを使用して、内部データセットを移行し、内部データセットと外部データセットの両方をサブスクライブできます。 -
データドメイン 1 は、臨床データ、オミクスデータ、画像データなど、マルチモーダルな患者指向データを処理するための包括的なワークフローで構成されています。EHR の臨床データは、臨床データ専用のマネージドサービスである HealthLake データストアに取り込まれて保存されます。 AWS HealthOmics
は、オミクスデータ専用のサービスであり、シーケンスとバリアントのストアとワークフローを処理します。イメージングデータは に取り込まれて保存されますAWS HealthImaging 。このデータは、すぐに使用できる製品に変換され、エンタープライズデータマーケットプレイスに公開され、幅広いアクセシビリティと使用が可能になります。 -
データドメイン 2、Amazon Kinesis、および AWS Data Exchange では AWS Glue、raw データをデータパイプラインに取り込みます。データのソースには、パブリックレジストリ、リモート患者モニタリング、Enterprise Resource Planning (ERP) プログラムなどがあります。パイプラインは、raw データを Amazon Simple Storage Service (Amazon S3)
バケットにロードします。このデータは、データ製品として公開するためにクリーンアップ、キュレーション、変換、保存されます。Amazon Athena は、データプロデューサーが SQL を使用してデータを変換するために使用できるインタラクティブなクエリエンジンを提供します。 AWS Glue DataBrew は、ビジュアルデータ変換、正規化、プロファイリング機能を提供します。 -
Amazon DataZone
は、メタデータ、共同データプロジェクト、およびデータ製品ライブラリのセントラルビジネスカタログへの発行を処理します。 -
統合データ分析ポータルは、フェデレーティッドガバナンスを通じてデータ製品のビューを提供することで、データに関するコラボレーションを可能にします。Amazon DataZone では、 を AWS Glue Data Catalog 基盤とするセルフサービスワークフローが有効になり AWS Lake Formation、ユーザーはデータを共有、検索、検出し、使用許可をリクエストできます。
-
データコンシューマーは、データにアクセスし、ダウンストリームビューを作成し、Amazon Athena、Amazon QuickSight
、Amazon Redshift 、Amazon SageMaker AI 、Amazon Bedrock などの専用ツールを使用して以下を実行できます。 -
運用分析
-
臨床情報
-
リソース
-
患者と臨床の関与
データコンシューマーは、生成 AI を使用して革新的なアプリケーションを開発し、データ製品をビジネスカタログに公開することもできます。
-
データメッシュアーキテクチャの詳細については、「Data Mesh とは」を参照してください。
生成 AI
医療組織は、医療画像の解釈の自動化から、画像データとテキストデータの両方に基づく診断の推奨事項や治療計画の生成まで、さまざまなアプリケーションに生成 AI を使用しています。生成 AI の導入は、ケアの連続性全体でイノベーションを加速し、効率を高めています。生成 AI への新しい焦点により、ヘルスケアはデータフォーカスを拡張してより多くの形式の非構造化データを含める必要があり、AI に適したユースケースの数と種類が拡大されました。一般的に、生成 AI ソリューションを実装するために、組織はユースケースに応じて 4 つのパターンから選択できます。
-
プロンプトエンジニアリング – プロンプトエンジニアリングでは、ユーザーは関連するデータをコンテキストとして提供し、生成 AI モデルが希望するコンテンツを作成するようにガイドします。最新のヘルスデータ戦略を持つ組織は、関連するデータを簡単に検出、共有、および使用可能にすることができます。
-
Retrieval Augmented Generation (RAG) – RAG パターンはプロンプトエンジニアリングに基づいています。ユーザーが関連データを提供する代わりに、プログラムはユーザーの質問または入力をインターセプトします。プログラムは、データリポジトリを検索して、質問または入力に関連するコンテンツを取得します。プログラムは、検出したデータを生成 AI モデルにフィードしてコンテンツを生成します。最新の医療データ戦略により、エンタープライズデータのキュレーションとインデックス作成が可能になります。その後、データを検索してプロンプトや質問のコンテキストとして使用し、大規模言語モデル (LLM) がレスポンスを生成するのに役立ちます。
組織は、次の 2 つのパターンを使用して、生成 AI モデル出力をデータのコンテキストに適したコンテンツの生成に集中させることができます。
-
ファインチューニング — このパターンを使用すると、生成 AI モデルをカスタマイズすることで、組織はさらに一歩踏み出すことができます。これには、組織固有のデータの小さなサンプルでモデルを微調整することが含まれます。サンプルサイズが小さいため、このパターンはコストとカスタマイズのバランスを提供します。モデル出力のバイアスを回避するには、組織のデータパターンをできるだけ多様で代表的な小さなサンプルデータセットを使用します。最新のヘルスデータ戦略は、さまざまなデータへの効率的なアクセスをサポートし、サンプルデータセットを準備します。
-
独自のモデルを構築する – 高度に専門化された大量のデータにわたってコンテンツを生成する必要があり、前の 3 つのパターンでは不十分な場合は、独自のモデルを構築できます。
最新のデータ戦略は、データに次の特性があることを確認することで、生成 AI ソリューションで重要な役割を果たします。
-
精度をサポートする高品質のデータ
-
モデル出力が関連していることを確認するためのリアルタイムまたはほぼリアルタイムのデータ
-
さまざまなデータソースにまたがる複数のデータモダリティにより、コンテンツを生成するための強化されたデータセットへのアクセスをモデルに提供
次の図は、データメッシュアーキテクチャを使用して生成 AI ソリューションをサポートする最新のヘルスデータ戦略の実装を示しています。
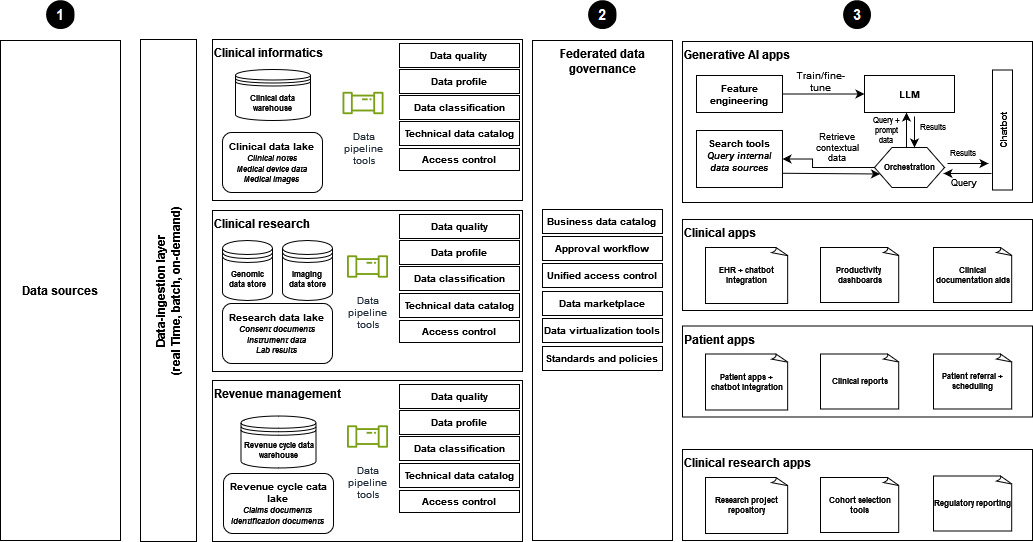
-
データは、臨床情報学、臨床研究、収益管理の各ドメインのさまざまなデータソースから取り込まれ、医療組織が利用できるようになります。
-
フェデレーティッドデータガバナンスは、データ共有と統合アクセスのための厳格なアクセスコントロールを確保するのに役立ちます。
-
データコンシューマーには以下が含まれます。
-
生成 AI アプリケーション、特にデータを使用して LLMs をトレーニングおよび微調整するアプリケーション。これらのアプリケーションは、Q&A チャットボットのエンタープライズデータを使用して、運用効率と患者とプロバイダーのエクスペリエンスを向上させます。
-
EHR 統合チャットボット、生産性ダッシュボード、ドキュメント支援などのツールを備えた臨床アプリケーション。
-
患者エクスペリエンスを向上させるための患者中心のアプリケーション。これらのアプリケーションは、チャットボットのやり取り、臨床レポート、効率的な紹介とスケジューリングのプロセスを備えています。
-
コホート分析と規制報告用に設計された研究プロジェクトのリポジトリとアプリケーションを備えた、 の臨床研究。
-
このアーキテクチャを使用すると、組織の関係者は、他のソースから収集したデータのキュレーションと管理に集中しながら、自分のデータを組織の他の部分にアクセスできるようになります。フェデレーティッドデータガバナンスレイヤーで使用できるツールを使用して、メタデータの定義、アクセス承認ワークフローの管理、ポリシーの定義と適用を行うことができます。さらに、フェデレーティッドデータガバナンスレイヤーは、一元的なアクセスコントロールを提供します。これにより、さまざまなデータソースをキュレートし、高品質のデータアセットを指定された頻度で更新して関連性を維持するための環境が作成されます。 は、生成 AI のニーズに対応するための包括的な機能セット AWS を提供します。Amazon Bedrock
