翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
シャッフルの最適化
join() や などの特定のオペレーションではgroupByKey()、Spark でシャッフルを実行する必要があります。シャッフルは、RDD パーティション間で異なるグループにデータを再分散するための Spark のメカニズムです。シャッフルは、パフォーマンスのボトルネックを修正するのに役立ちます。ただし、シャッフルには通常 Spark エグゼキュター間でのデータのコピーが含まれるため、シャッフルは複雑でコストがかかる操作です。たとえば、シャッフルによって次のコストが発生します。
-
ディスク I/O:
-
ディスク上に多数の中間ファイルを生成します。
-
-
ネットワーク I/O:
-
多数のネットワーク接続が必要です (接続数 =
Mapper × Reducer)。 -
レコードは別の Spark エグゼキュターでホストされている可能性のある新しい RDD パーティションに集約されるため、データセットの大部分がネットワーク経由で Spark エグゼキュター間を移動する可能性があります。
-
-
CPU とメモリの負荷:
-
値をソートし、データセットをマージします。これらのオペレーションはエグゼキュターで計画され、エグゼキュターに重い負荷がかかります。
-
シャッフルは、Spark アプリケーションのパフォーマンス低下における最も重要な要因の 1 つです。中間データの保存中に、エグゼキュターのローカルディスクの領域が枯渇し、Spark ジョブが失敗する可能性があります。
シャッフルパフォーマンスは、CloudWatch メトリクスと Spark UI で評価できます。
CloudWatch メトリクス
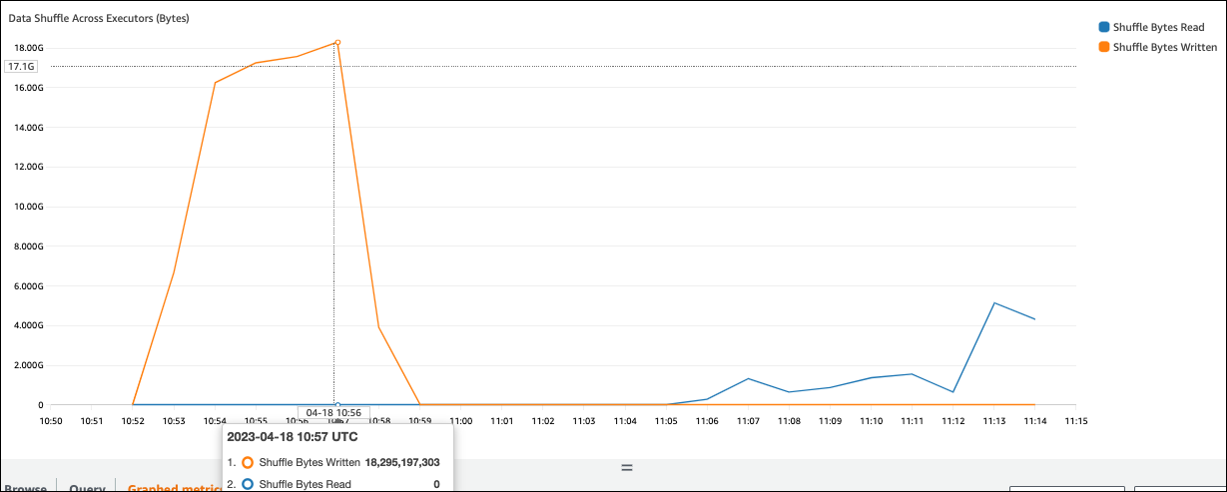
シャッフルバイトの書き込み値がシャッフルバイト読み取りと比較して高い場合、Spark ジョブは join()や などのシャッフルオペレーションgroupByKey()。
Spark UI
Spark UI のステージタブで、シャッフル読み取りサイズ/レコードの値を確認できます。エグゼキュタータブでも確認できます。
次のスクリーンショットでは、各エグゼキュターがシャッフルプロセスで約 18.6 GB/4020000 レコードを交換し、合計シャッフル読み取りサイズは約 75 GB) になります。
シャッフルスピル (ディスク) 列には、大量のデータスピルメモリがディスクに表示され、フルディスクやパフォーマンスの問題が発生する可能性があります。

これらの症状が発生し、ステージがパフォーマンス目標と比較して長すぎる場合、または Out Of Memoryまたは No space left on device エラーで失敗する場合は、次の解決策を検討してください。
結合の最適化
テーブルを結合する join()オペレーションは、最も一般的に使用されるシャッフルオペレーションですが、パフォーマンスのボトルネックになることがよくあります。結合はコストのかかる操作であるため、ビジネス要件に不可欠でない限り、使用しないことをお勧めします。次の質問をして、データパイプラインを効率的に使用していることを再確認します。
-
再利用できる他のジョブでも実行される結合を再計算していますか?
-
外部キーを出力のコンシューマーが使用していない値に解決するために結合していますか?
参加オペレーションがビジネス要件に不可欠であることを確認したら、要件を満たす方法で参加を最適化するための以下のオプションを参照してください。
参加前にプッシュダウンを使用する
結合を実行する前に、DataFrame 内の不要な行と列を除外します。これには次の利点があります。
-
シャッフル中のデータ転送量を削減
-
Spark エグゼキュターの処理量を削減します。
-
データスキャンの量を削減
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
DataFrame Join を使用する
RDD API または DynamicFrame 結合の代わりに、SparkSQL、DataFrame、データセットなどの Spark 高レベルdyf.toDF()。Apache Spark の「キートピック」セクションで説明したように、これらの結合オペレーションは、Catalyst オプティマイザによるクエリ最適化を内部的に活用します。
ハッシュ結合とヒントのシャッフルとブロードキャスト
Spark は、シャッフル結合とブロードキャストハッシュ結合の 2 種類の結合をサポートしています。ブロードキャストハッシュ結合にはシャッフルが不要で、シャッフル結合よりも処理が少なくて済みます。ただし、小さなテーブルを大きなテーブルに結合する場合にのみ該当します。単一の Spark エグゼキュターのメモリに収まるテーブルを結合する場合は、ブロードキャストハッシュ結合の使用を検討してください。
次の図は、ブロードキャストハッシュ結合とシャッフル結合の構造と手順の概要を示しています。
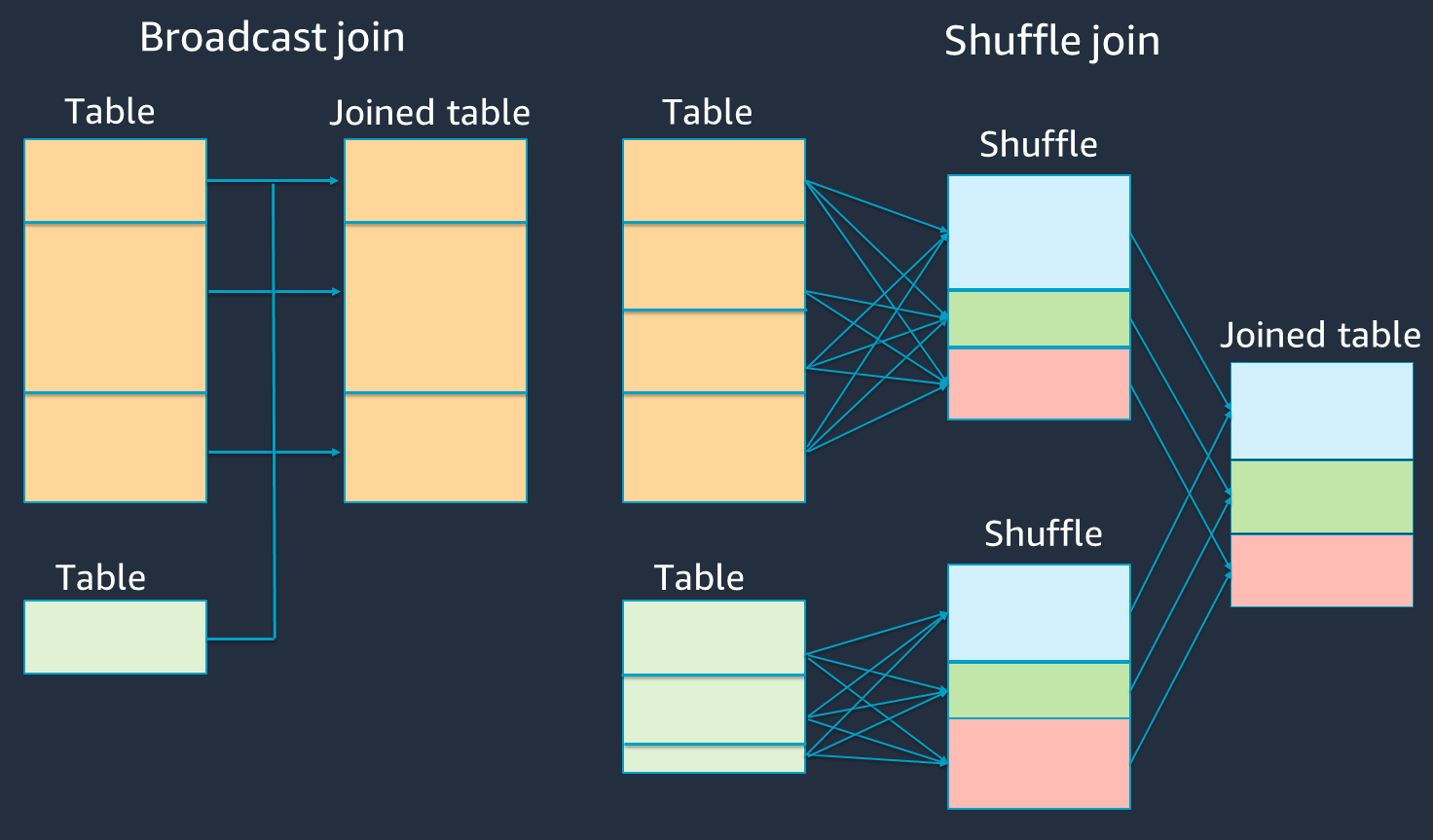
各結合の詳細は次のとおりです。
-
シャッフル結合:
-
シャッフルハッシュ結合は、ソートせずに 2 つのテーブルを結合し、2 つのテーブル間で結合を分散します。Spark エグゼキュターのメモリに保存できる小さなテーブルの結合に適しています。
-
ソートマージ結合は、結合する 2 つのテーブルをキーで分散し、結合する前にソートします。大きなテーブルの結合に適しています。
-
-
ブロードキャストハッシュ結合:
-
ブロードキャストハッシュ結合は、小さい RDD またはテーブルを各ワーカーノードにプッシュします。次に、より大きな RDD またはテーブルの各パーティションとマップ側の結合を行います。
RDDsまたはテーブルの 1 つがメモリに収まる場合や、メモリに収まるように作成できる場合の結合に適しています。ブロードキャストハッシュ結合はシャッフルを必要としないため、可能な限り行うことをお勧めします。結合ヒントを使用して、次のように Spark からブロードキャスト結合をリクエストできます。
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;結合ヒントの詳細については、「結合ヒント
」を参照してください。
-
AWS Glue 3.0 以降では、アダプティブクエリの実行
AWS Glue 3.0 では、 を設定することでアダプティブクエリの実行を有効にできますspark.sql.adaptive.enabled=true。AWS Glue 4.0 では、アダプティブクエリの実行がデフォルトで有効になっています。
シャッフルとブロードキャストハッシュ結合に関連する追加のパラメータを設定できます。
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
関連するパラメータの詳細については、「ソートマージ結合をブロードキャスト結合に変換する
AWS Glue 3.0 以降では、シャッフルに他の結合ヒントを使用して動作を調整できます。
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
バケット化を使用する
ソートマージ結合には、シャッフルとソートの 2 つのフェーズが必要で、その後マージします。これら 2 つのフェーズでは、Spark エグゼキュターがマージされていて、他のエグゼキュターが同時にソートされている場合、Spark エグゼキュターが過負荷になり、OOM とパフォーマンスの問題が発生する可能性があります。このような場合、バケット化
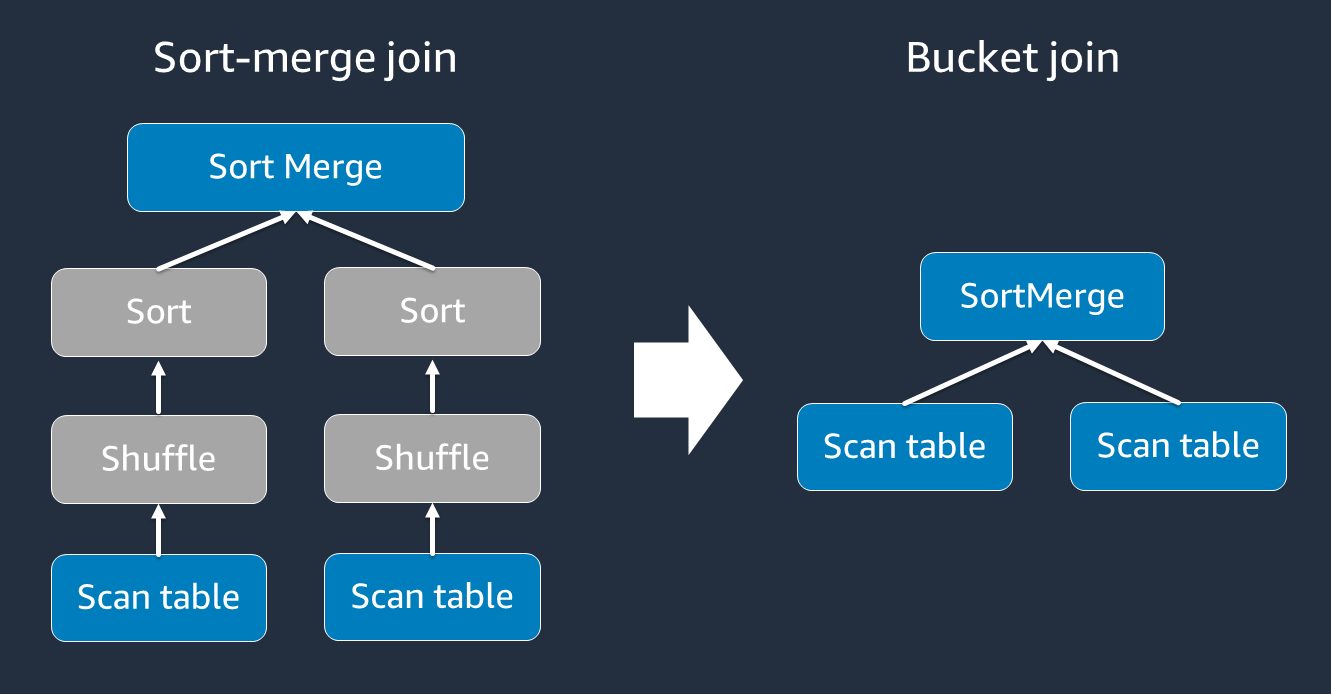
バケット化されたテーブルは、次の場合に便利です。
-
などの同じキーで頻繁に結合されるデータ
account_id -
共通の列にバケット化できるベーステーブルやデルタテーブルなど、毎日の累積テーブルをロードする
次のコードを使用して、バケット化されたテーブルを作成できます。
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
結合前に結合キーで DataFrames を再パーティションする
結合前に結合キーの 2 つの DataFramesを再パーティションするには、次のステートメントを使用します。
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
これにより、結合を開始する前に、結合キーで 2 つの (まだ分離された) RDDs がパーティション分割されます。2 つの RDDs が同じパーティション化コードを持つ同じキーでパーティション化されている場合、結合する計画が結合のシャッフル前に同じワーカーに共存する可能性が高くなります。これにより、結合中のネットワークアクティビティとデータスキューが減少し、パフォーマンスが向上する可能性があります。
データスキューを克服する
データスキューは、Spark ジョブのボトルネックの最も一般的な原因の 1 つです。これは、データが RDD パーティション間で均一に分散されていない場合に発生します。これにより、そのパーティションのタスクは他のパーティションよりもはるかに時間がかかり、アプリケーションの全体的な処理時間が遅延します。
データスキューを特定するには、Spark UI で次のメトリクスを評価します。
-
Spark UI のステージタブで、イベントのタイムラインページを確認します。次のスクリーンショットでは、タスクの不均等な分布を確認できます。不均等に分散されているタスクや実行に時間がかかりすぎるタスクは、データスキューを示している可能性があります。
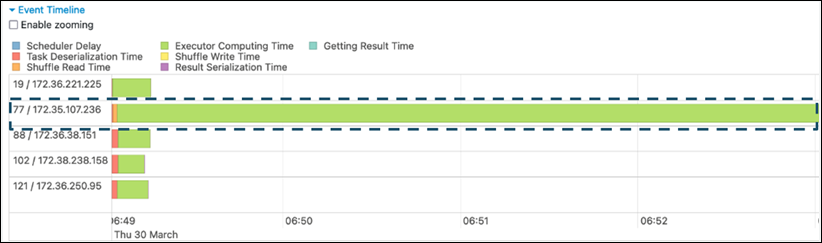
-
もう 1 つの重要なページは、Spark タスクの統計を表示する概要メトリクスです。次のスクリーンショットは、期間、GC 時間、スピル (メモリ)、スピル (ディスク) などのパーセンタイルを持つメトリクスを示しています。

タスクが均等に分散されると、すべてのパーセンタイルに同様の数値が表示されます。データスキューがある場合、各パーセンタイルに非常にバイアスされた値が表示されます。この例では、最小、25 パーセンタイル、中央値、および 75 パーセンタイルでタスクの所要時間が 13 秒未満です。 Max タスクは 75 パーセンタイルよりも 100 倍多くのデータを処理しましたが、6.4 分の期間は約 30 倍長くなります。つまり、少なくとも 1 つのタスク (またはタスクの最大 25%) が残りのタスクよりもはるかに時間がかかりました。
データスキューが表示された場合は、以下を試してください。
-
AWS Glue 3.0 を使用する場合は、 を設定してアダプティブクエリの実行を有効にします
spark.sql.adaptive.enabled=true。アダプティブクエリの実行は、デフォルトで AWS Glue 4.0 で有効になっています。次の関連パラメータを設定することで、結合によって導入されたデータスキューにアダプティブクエリ実行を使用することもできます。
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
詳細については、Apache Spark のドキュメント
を参照してください。 -
-
結合キーには、幅広い値を持つキーを使用します。シャッフル結合では、パーティションはキーのハッシュ値ごとに決定されます。結合キーのカーディナリティが低すぎる場合、ハッシュ関数はパーティション間でデータを分散する不正なジョブを実行する可能性が高くなります。したがって、アプリケーションとビジネスロジックでサポートされている場合は、より高い基数キーまたは複合キーの使用を検討してください。
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
キャッシュを使用する
反復的な DataFrames を使用する場合は、 または を使用して計算結果を各 Spark エグゼキュターのメモリとディスクにdf.persist()キャッシュすることで、追加のシャッフルdf.cache()や計算を避けます。Spark は、ディスクへの RDDs保持または複数のノード (ストレージレベル
例えば、 を追加して DataFrames を保持できますdf.persist()。キャッシュが不要になった場合は、 unpersistを使用してキャッシュされたデータを破棄できます。
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
不要な Spark アクションを削除する
count、、showまたは などの不要なアクションを実行しないでくださいcollect。Apache Spark の「キートピック」セクションで説明したように、Spark は遅延しています。変換された各 RDD は、アクションを実行するたびに再計算される場合があります。多くの Spark アクションを使用すると、アクションごとに複数のソースアクセス、タスク計算、シャッフル実行が呼び出されます。
商用環境で collect()やその他のアクションが必要ない場合は、それらを削除することを検討してください。
注記
Spark collect()は商用環境でできるだけ使用しないでください。collect() アクションは、Spark エグゼキュターの計算のすべての結果を Spark ドライバーに返します。これにより、Spark ドライバーが OOM エラーを返す可能性があります。OOM エラーを回避するために、Spark はspark.driver.maxResultSize = 1GBデフォルトで を設定します。これにより、Spark ドライバーに返される最大データサイズが 1 GB に制限されます。
