翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
のスケーラブルなウェブクローリングシステムのアーキテクチャ AWS
次のアーキテクチャ図は、ウェブサイトから環境、社会、ガバナンス (ESG) データを倫理的に抽出するように設計されたウェブクローラーシステムを示しています。 AWS インフラストラクチャに最適化された Pythonベースのクローラを使用します。 AWS Batch を使用して大規模なクローリングジョブをオーケストレーションし、ストレージに Amazon Simple Storage Service (Amazon S3) を使用します。ダウンストリームアプリケーションは、Amazon S3 バケットからデータを取り込んで保存できます。
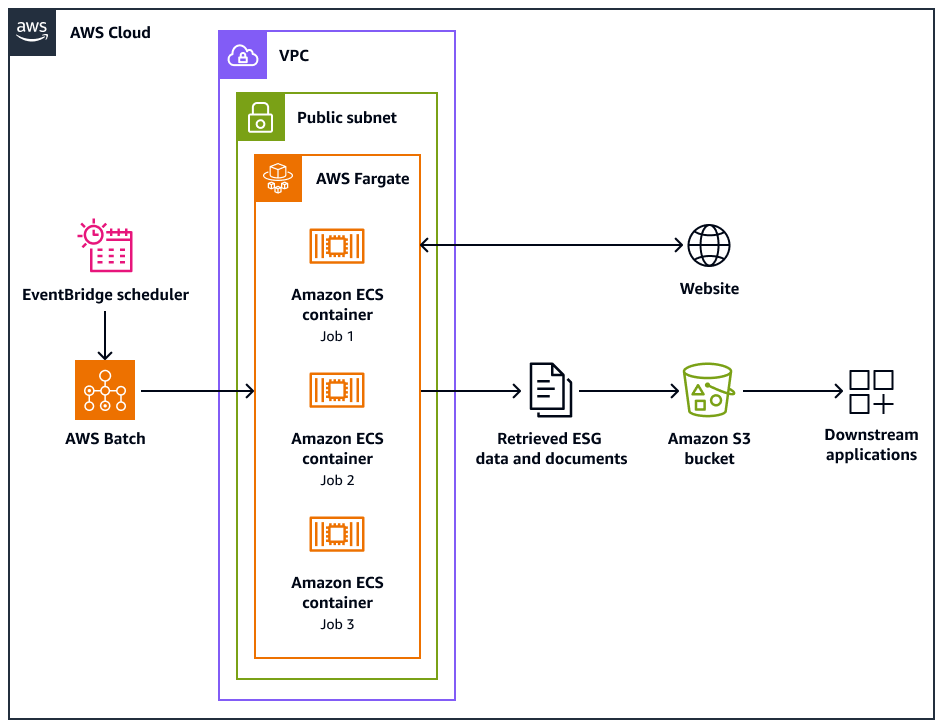
この図表は、次のワークフローを示しています:
-
Amazon EventBridge スケジューラは、スケジュールした間隔でクローリングプロセスを開始します。
-
AWS Batch は、ウェブクローラージョブの実行を管理します。 AWS Batch ジョブキューは、保留中のクローリングジョブを保持およびオーケストレーションします。
-
ウェブクロールジョブは、Amazon Elastic Container Service (Amazon ECS) コンテナで実行されます AWS Fargate。ジョブは、仮想プライベートクラウド (VPC) のパブリックサブネットで実行されます。
-
ウェブクローラーはターゲットウェブサイトをクロールし、PDF、CSV、またはその他のドキュメントファイルなどの ESG データおよびドキュメントを取得します。
-
ウェブクローラーは、取得したデータと raw ファイルを Amazon S3 バケットに保存します。
-
他のシステムまたはアプリケーションは、Amazon S3 バケットに保存されたデータとファイルを取り込み、処理します。
ウェブクローラーの設計と運用
一部のウェブサイトは、デスクトップまたはモバイルデバイスで実行するように特別に設計されています。ウェブクローラーは、デスクトップユーザーエージェントまたはモバイルユーザーエージェントの使用をサポートするように設計されています。これらのエージェントは、ターゲットウェブサイトへのリクエストを正常に行うのに役立ちます。
ウェブクローラーが初期化されると、次のオペレーションが実行されます。
-
ウェブクローラーは
setup()メソッドを呼び出します。このメソッドは、robots.txt ファイルを取得して解析します。注記
サイトマップを取得して解析するようにウェブクローラーを設定することもできます。
-
ウェブクローラーは robots.txt ファイルを処理します。robots.txt ファイルでクロール遅延が指定されている場合、ウェブクローラーはデスクトップユーザーエージェントのクロール遅延を抽出します。robots.txt ファイルでクロール遅延が指定されていない場合、ウェブクローラーはランダムな遅延を使用します。
-
ウェブクローラは
crawl()メソッドを呼び出し、クローリングプロセスを開始します。キューに URLs がない場合、開始 URL が追加されます。注記
クローラは、最大ページ数に達するか、クロールする URLs が不足するまで続行します。
-
クローラは URLs。キュー内の各 URL について、クローラーは URL がすでにクロールされているかどうかを確認します。
-
URL がクロールされていない場合、クローラは次のように
crawl_url()メソッドを呼び出します。-
クローラは robots.txt ファイルをチェックして、デスクトップユーザーエージェントを使用して URL をクロールできるかどうかを判断します。
-
許可されている場合、クローラはデスクトップユーザーエージェントを使用して URL のクロールを試みます。
-
許可されていない場合、またはデスクトップユーザーエージェントがクロールに失敗した場合、クローラーは robots.txt ファイルをチェックして、モバイルユーザーエージェントを使用して URL をクロールできるかどうかを判断します。
-
許可されている場合、クローラはモバイルユーザーエージェントを使用して URL のクロールを試みます。
-
-
クローラは
attempt_crawl()メソッドを呼び出し、コンテンツを取得して処理します。クローラは、適切なヘッダーを含む GET リクエストを URL に送信します。リクエストが失敗した場合、クローラは再試行ロジックを使用します。 -
ファイルが HTML 形式の場合、クローラは
extract_esg_data()メソッドを呼び出します。Beautiful Soupを使用して HTML コンテンツを解析します。キーワードマッチングを使用して、環境、社会、ガバナンス (ESG) データを抽出します。 ファイルが PDF の場合、クローラは
save_pdf()メソッドを呼び出します。クローラは PDF ファイルをダウンロードして Amazon S3 バケットに保存します。 -
クローラは
extract_news_links()メソッドを呼び出します。これにより、ニュース記事、プレスリリース、ブログ投稿へのリンクが検索され、保存されます。 -
クローラは
extract_pdf_links()メソッドを呼び出します。これにより、PDF ドキュメントへのリンクが識別され、保存されます。 -
クローラは
is_relevant_to_sustainable_finance()メソッドを呼び出します。これにより、事前定義されたキーワードを使用して、ニュースや記事が持続可能な金融に関連しているかどうかがチェックされます。 -
クロールが試行されるたびに、クローラは
delay()メソッドを使用して遅延を実装します。robots.txt ファイルで遅延が指定されている場合、その値が使用されます。それ以外の場合は、1~3 秒のランダムな遅延を使用します。 -
クローラは
save_esg_data()メソッドを呼び出して ESG データを CSV ファイルに保存します。CSV ファイルは Amazon S3 バケットに保存されます。 -
クローラは
save_news_links()メソッドを呼び出して、関連性情報を含む CSV ファイルにニュースリンクを保存します。CSV ファイルは Amazon S3 バケットに保存されます。 -
クローラは
save_pdf_links()メソッドを呼び出して PDF リンクを CSV ファイルに保存します。CSV ファイルは Amazon S3 バケットに保存されます。
バッチ処理とデータ処理
クローリングプロセスは、構造化された方法で編成および実行されます。 AWS Batch は、ジョブをバッチで並行して実行するように、各会社のジョブを割り当てます。各バッチは、データセットで特定した 1 つの会社のドメインとサブドメインに焦点を当てています。ただし、同じバッチ内のジョブは順番に実行されるため、リクエストが多すぎてウェブサイトに水没することはありません。これにより、アプリケーションはクローリングワークロードをより効率的に管理し、すべての関連データが企業ごとに確実にキャプチャされます。
ウェブクロールを会社固有のバッチに整理することで、収集されたデータをコンテナ化します。これにより、ある会社のデータが他の会社のデータと混在するのを防ぐことができます。
バッチ処理は、アプリケーションがウェブから効率的にデータを収集し、ターゲット企業とそれぞれのウェブドメインに基づいて情報の明確な構造と分離を維持するのに役立ちます。このアプローチは、収集されたデータの整合性と使いやすさを確保するのに役立ちます。収集されたデータは整理され、適切な会社とドメインに関連付けられています。
