クエリプランと実行ワークフロー
次の図は、クエリの計画と実行のワークフローの概要です。
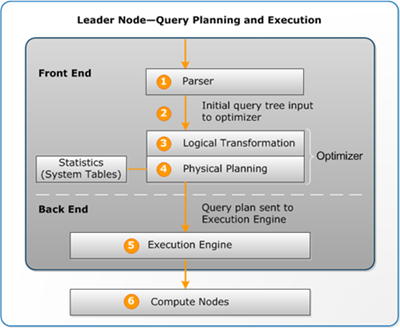
クエリプランと実行ワークフローは以下のステップに従います。
-
リーダーノードはクエリを受け取り、SQL を解析します。
-
クエリツリーパーサーは、元のクエリの論理的な表現である初期クエリツリーを生成します。次に、Amazon Redshift は、このクエリツリーをクエリオプティマイザに入力します。
-
オプティマイザは、クエリを評価し、必要に応じて書き換えて効率を最大限に高めます。このプロセスにより、関連するクエリが複数作成されて、単一のクエリが置き換えられることがあります。
-
オプティマイザは、最高のパフォーマンスで実行されるように 1 つのクエリプラン (または、前のステップで複数のクエリが生成された場合は複数のクエリプラン) を生成します。クエリプランは、結合の種類、結合の順序、集計オプション、データ分散要件などの実行オプションを指定します。
クエリプランを表示するには、EXPLAINコマンドを使用できます。クエリプランは、複雑なクエリを分析およびチューニングするための基本ツールです。詳細については、「クエリプランの作成と解釈」を参照してください。
-
実行エンジンは、クエリプランをステップ、セグメント、ストリームに変換します。
- Step
-
各ステップは、クエリ実行時に必要な別個の操作です。コンピューティングノードはステップを組み合わせることによってクエリ、結合、または他のデータベース操作を実行できます。
- Segment
-
1 つのプロセスで実行できる複数のステップの組み合わせ。コンピューティングノードスライスによって実行可能な最小コンパイル単位でもあります。スライスは、Amazon Redshift の並列処理単位です。並行して実行されるストリーム内のセグメント。
- ストリーム
-
使用できるコンピューティングノードスライスに並列化するセグメントのコレクション。
実行エンジンは、ステップ、セグメント、ストリームに基づいてコンパイルされたコードを生成します。コンパイルされたコードの実行は解釈されたコードよりも速く、使用するコンピューティングキャパシティも少なくなります。その後、このコンパイル済みコードは、コンピューティングノードにブロードキャストされます。
注記
クエリのベンチマークを行うときは、常に、クエリの 2 回目の実行の時間を比較する必要があります。1 回目の実行の時間には、コードをコンパイルするオーバーヘッドが含まれるためです。詳細については、「クエリパフォーマンスに影響を与える要因」を参照してください。
-
コンピューティングノードスライスは、クエリセグメントを並列的に実行します。このプロセスの一部として、Amazon Redshift は、最適化されたネットワーク通信、メモリ、ディスク管理を利用して、クエリプランのステップから次のステップに中間結果を渡します。これは、クエリ実行の高速化にも役立ちます。
ステップ 5 と 6 はストリームごとに 1 回ずつ行われます。エンジンは、1 つのストリームに対して実行可能なセグメントを作成し、コンピューティングノードに送信します。そのストリームのセグメントが完了したら、エンジンは次のストリームのセグメントを生成します。これにより、エンジンは前のストリームで何が発生したかを分析し (操作がディスクベースであったかどうかなど)、次のストリーム内におけるセグメントの生成に影響を与えることができます。
コンピューティングノードは、完了すると最終処理を行うためクエリの結果をリーダーノードに返します。リーダーノードは、データを 1 つの結果セットにマージし、必要なソートまたは集計すべてに対処します。次に、リーダーノードは結果をクライアントに返します。
注記
コンピューティングノードは、必要に応じてクエリの実行中に一部のデータをリーダーノードに返すことがあります。例えば、LIMIT 句を含むサブクエリがある場合、さらに処理を行うためデータがクラスターに再分散される前に制限がリーダーノードに適用されます。
