翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Data Wrangler フローを作成して使用する
Amazon SageMaker Data Wrangler フローまたはデータフローを使用して、データ準備パイプラインを作成および変更します。データフローは、データセット、変換、分析、または、パイプラインを定義するために作成して使用できるステップを接続します。
インスタンス
Amazon SageMaker Studio Classic でデータラングラーフローを作成すると、データラングラーは Amazon EC2 インスタンスを使用してフロー内の分析と変換を実行します。デフォルトでは、Data Wrangler は m5.4xlarge インスタンスを使用します。M5 インスタンスは、コンピューティングとメモリのバランスをとる汎用インスタンスです。M5 インスタンスはさまざまなコンピューティングワークロードに使用できます。
Data Wrangler には R5 インスタンスを使用するオプションもあります。R5 インスタンスは、メモリ内の大きなデータセットを処理する高速パフォーマンスを実現するように設計されています。
ワークロードに合わせて最適化されたインスタンスを選択することをお勧めします。例えば、r5.8xlarge は m5.4xlarge と比較して価格が高くても、よりワークロードに最適化されている場合があります。より最適化されたインスタンスでは、データフローを短時間に低コストで実行できます。
次の表は、Data Wrangler フローの実行に使用できるインスタンスを示しています。
| スタンダードインスタンス | vCPU | 「メモリ」 |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.8xlarge | 32 | 128 GiB |
| ml.m5.16xlarge | 64 |
256 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128 GiB |
| r5.8xlarge | 32 | 256 GiB |
| r5.24xlarge | 96 | 768 GiB |
R5 インスタンスの詳細については、「Amazon EC2 R5 インスタンス
各 Data Wrangler フローには、Amazon EC2 インスタンスが関連付けられています。1 つのインスタンスに複数のフローが関連付けられている場合があります。
フローファイルごとに、インスタンスタイプをシームレスに切り替えることができます。インスタンスタイプを切り替えても、フローの実行に使用したインスタンスは引き続き実行されます。
フローのインスタンスタイプを切り替えるには、以下の手順を実行します。
-
ホームアイコン
 を選択します。
を選択します。 -
使用しているインスタンスに移動して選択します。
-
使用するインスタンスタイプを選択します。

-
[保存] を選択します。
実行中のすべてのインスタンスに対して課金されます。追加料金が発生しないように、使用していないインスタンスは手動でシャットダウンしてください。実行中のインスタンスをシャットダウンするには、以下の手順に従います。
実行中のインスタンスをシャットダウンする方法
-
インスタンスアイコンを選択します。以下の画像は、[実行中のインスタンス] アイコンを選択する場所を示しています。
-
シャットダウンするインスタンスの横にある [シャットダウン] を選択します。
フローを実行するために使用するインスタンスをシャットダウンすると、そのフローには一時的にアクセスできなくなります。以前にシャットダウンしたインスタンスを実行しているフローを開く際にエラーが発生した場合は、5 分待ってからもう一度開いてください。
データフローを Amazon Simple Storage Service や Amazon SageMaker Feature Store などの場所にエクスポートすると、データラングラーは Amazon SageMaker 処理ジョブを実行します。Processing ジョブには、以下のいずれかのインスタンスを使用します。データのエクスポートの詳細については、「[Export] (エクスポート)」を参照してください。
| スタンダードインスタンス | vCPU | 「メモリ」 |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.12xlarge | 48 |
192 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
利用可能なインスタンスタイプを使用する場合の 1 時間あたりのコストの詳細については、「料金表」を参照してくださいSageMaker 。
データフロー UI
データセットをインポートすると、元のデータセットがデータフローに表示され、[Source] (ソース) という名前が付けられます。データのインポート時にサンプリングを有効にした場合、このデータセットには [ソース - サンプリング] という名前が付けられます。Data Wrangler は、データセット内の各列のタイプを自動的に推論し、[Data types] (データ型) という名前の新しいデータフレームを作成します。このフレームを選択して、推定されたデータ型を更新できます。1 つのデータセットをアップロードすると、次の図に示すような結果が表示されます。
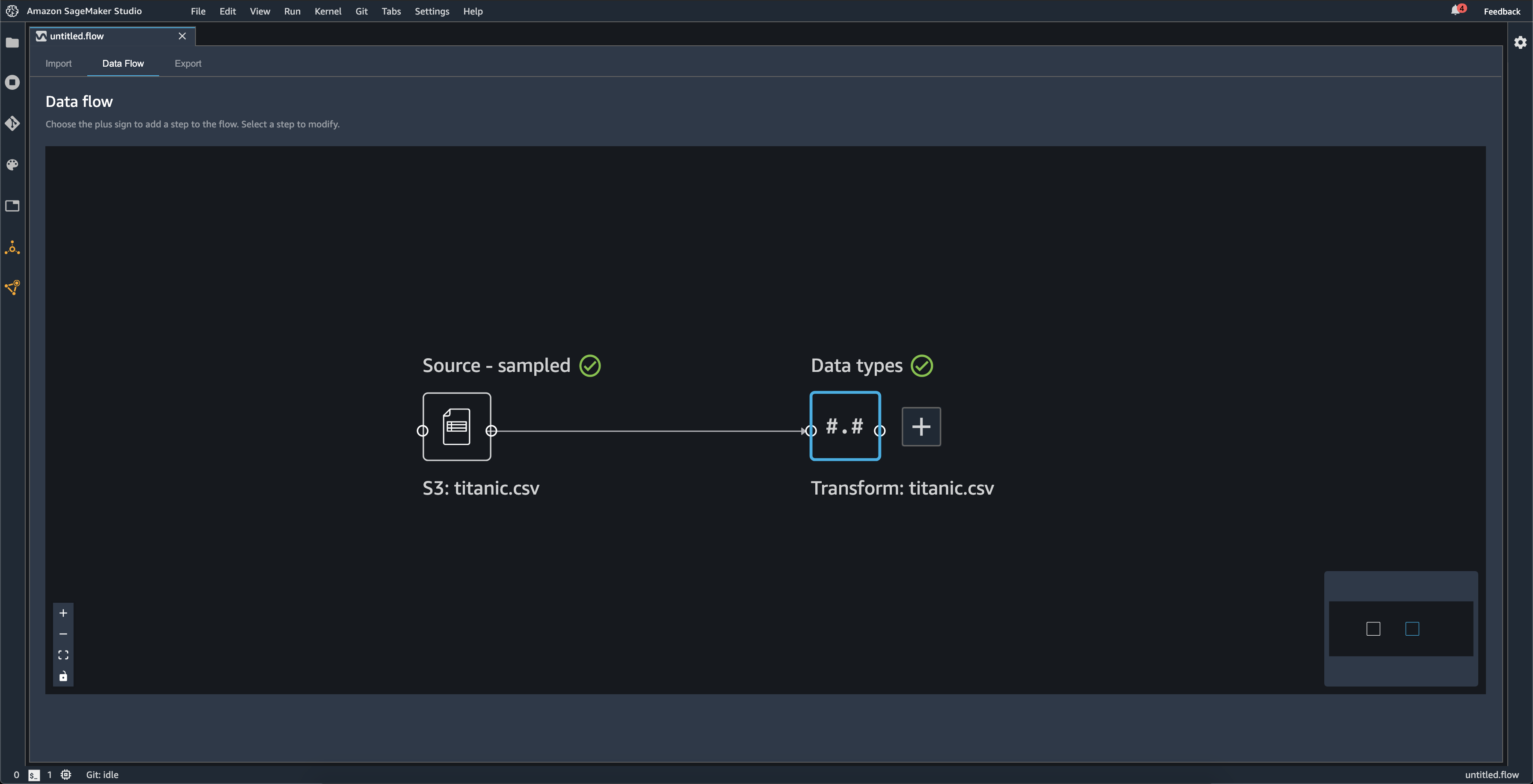
変換ステップを追加するたびに、新しいデータフレームを作成します。複数の変換ステップ ([結合] または [連結] 以外) を同じデータセットに追加すると、それらはスタックされます。
[結合] と [連結] は、結合または連結された新しいデータセットを含むスタンドアロンステップを作成します。
次の図は、2 つのデータセット間の結合とステップの 2 つのスタックを含むデータフローを示しています。最初のスタック (Steps (2)) は、[Data types] (データ型) データセットで推論されるタイプに 2 つの変換を追加します。ダウンストリームスタック (右側のスタック) は、demo-join という名前の結合から得られた変換をデータセットに追加します。
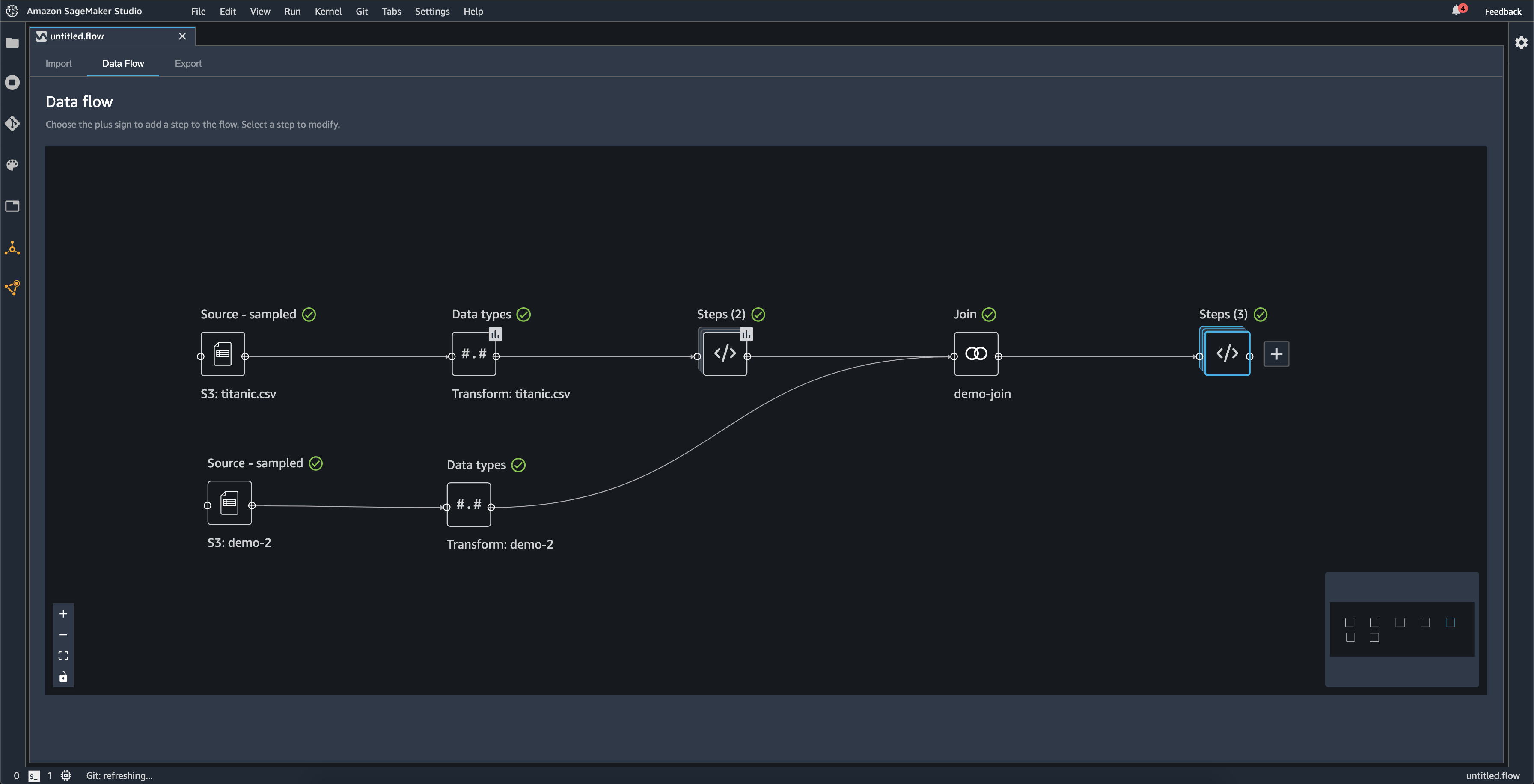
データフローの右下隅にある小さなグレーのボックスは、フロー内のスタックとステップの数や、フローのレイアウトの概要を示します。グレーのボックス内のより明るいボックスは、UI ビュー内のステップを示します。このボックスを使用して、UI ビュー外にあるデータフローのセクションを表示できます。画面に合わせるアイコン (
 ) を使用して、すべてのステップとデータセットを UI ビューに収めます。
) を使用して、すべてのステップとデータセットを UI ビューに収めます。
左下のナビゲーションバーには、データフローのズームイン (
 ) およびズームアウト (
) およびズームアウト (
 ) とデータフローの画面に合わせたサイズ変更 (
) に使用できるアイコンが含まれています。画面上の各ステップの位置をロックおよびロック解除する場合は、ロックアイコン (
) とデータフローの画面に合わせたサイズ変更 (
) に使用できるアイコンが含まれています。画面上の各ステップの位置をロックおよびロック解除する場合は、ロックアイコン (
 ) を使用します。
) を使用します。
データフローにステップを追加する
任意のデータセットまたは以前に追加したステップの横にある [+] を選択し、次のいずれかのオプションを選択します。
-
[データ型を編集] ([データ型] ステップの場合のみ): [データ型] ステップに変換を追加していない場合は、データセットのインポート時に [データ型を編集] を選択して Data Wrangler が推測するデータ型を更新できます。
-
Add transform (変換を追加): 新しい変換ステップを追加します。追加できるデータ変換の詳細については、「データを変換する」を参照してください。
-
Add analysis (分析を追加): 分析を追加します。このオプションを使用して、データフローの任意の時点でデータを分析できます。1 つ以上の分析をステップに追加すると、分析アイコン (
 ) がそのステップに表示されます。追加できる分析の詳細については、「分析および視覚化」を参照してください。
) がそのステップに表示されます。追加できる分析の詳細については、「分析および視覚化」を参照してください。 -
Join (結合): 2 つのデータセットを結合し、結果のデータセットをデータフローに追加します。詳細については、「データセットを結合する」を参照してください。
-
Concatenate (連結): 2 つのデータセットを連結し、結果のデータセットをデータフローに追加します。詳細については、「データセットを連結する」を参照してください。
データフローからステップを削除する
ステップを削除するには、ステップを選択し、[Delete] (削除) を選択します。ノードが 1 つの入力を持つノードの場合は、選択したステップのみを削除します。1 つの入力を持つステップを削除しても、そのステップに続くステップは削除されません。ソースノード、結合ノード、連結ノードのステップを削除する場合、それに続くすべてのステップも削除されます。
ステップのスタックからステップを削除するには、スタックを選択し、削除するステップを選択します。
次の手順のいずれかを使用して、ダウンストリームステップを削除せずにステップを削除できます


Data Wrangler フローのステップを編集する
Data Wrangler フローに追加した各ステップを編集できます。ステップを編集することで、列の変換やデータ型を変更できます。ステップを編集して変更を加えることで、より適切な分析を行うことができます。
ステップを編集するには、さまざまな方法があります。例としては、代入方法の変更や、値を外れ値と見なすためのしきい値の変更などがあります。
以下の手順に従って、 データソースを編集します。
ステップを編集するには、以下の手順を実行します。
-
Data Wrangler フローのステップを選択し、テーブルビューを開きます。

-
データフローのステップを選択します。
-
ステップを編集します。
次の画像は、ステップの編集の例を示しています。
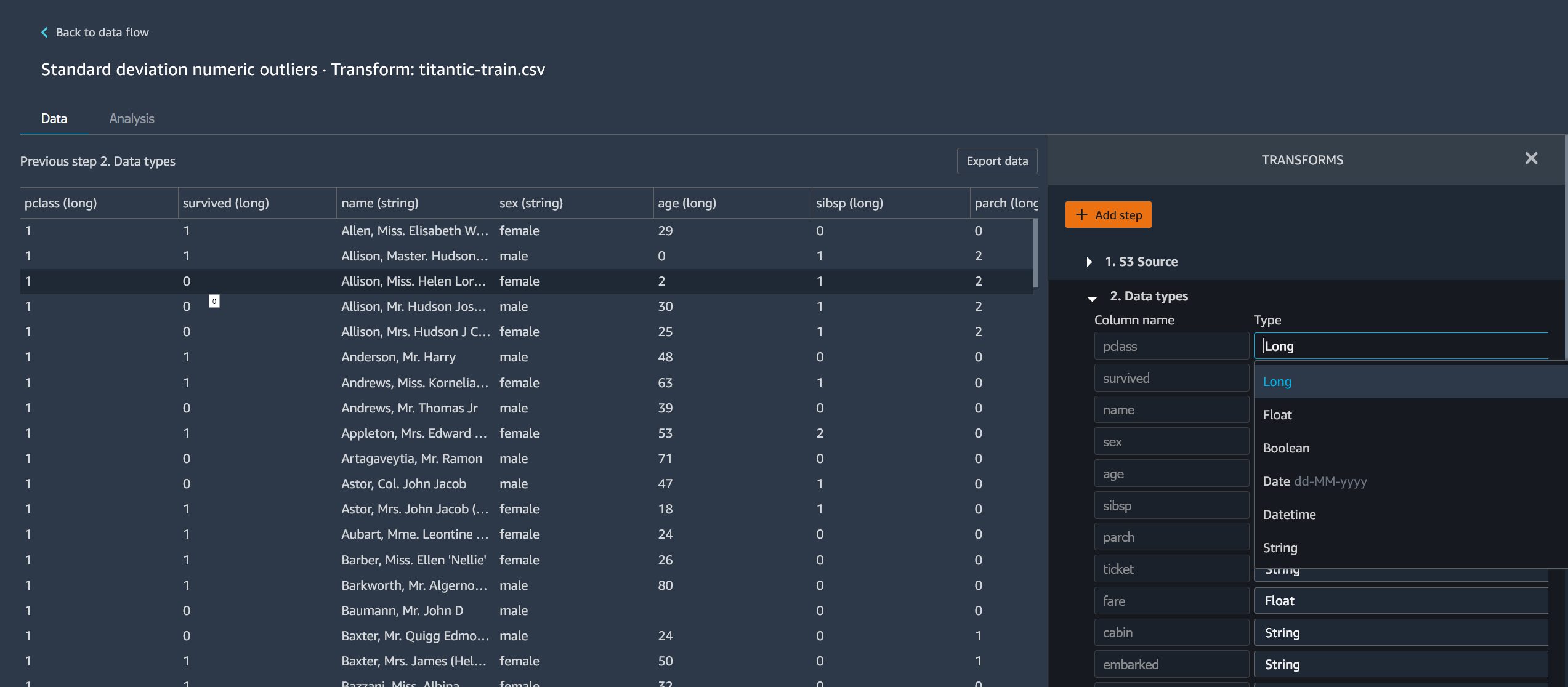
注記
Amazon SageMaker ドメイン内の共有スペースを使用して、Data Wrangler フローを共同作業できます。共有スペース内では、ユーザーと共同作業者はフローファイルをリアルタイムで編集できます。ただし、ユーザーも共同作業者も変更をリアルタイムで確認することはできません。Data Wrangler フローに変更を加えたら、すぐに保存する必要があります。ファイルを保存しても、ファイルを閉じてから再び開かない限り、共同編集者はそのファイルを見ることができません。1 人のユーザーが保存しなかった変更は、変更を保存したユーザーによって上書きされます。
