翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
外れ値検出による障害検出
複数のアベイラビリティーゾーンで相関性のない理由で発生するエラー率が高くなっている場合、前述の方法とのギャップが 1 つ生じることがあります。3 つのアベイラビリティーゾーンに EC2 インスタンスをデプロイしていて、可用性アラームのしきい値が 99% であるシナリオを想像してみてください。その後、1 つのアベイラビリティーゾーンで障害が発生し、多くのインスタンスが分離され、そのゾーンの可用性が 55% まで低下します。同時に、別のアベイラビリティーゾーンでは、1 つの EC2 インスタンスが EBS ボリュームのストレージをすべて使い果たし、ログファイルを書き込めなくなります。これによりエラーが返され始めますが、ロードバランサーのヘルスチェックはログファイルの書き込みをトリガーしないため、それでもパスします。その結果、そのアベイラビリティーゾーンの可用性が 98% に低下します。この場合、複数のアベイラビリティーゾーンで可用性の影響が見られるため、1 つのアベイラビリティーゾーンの影響アラームは有効になりません。ただし、障害のあるアベイラビリティーゾーンを退避させることで、影響のほぼすべてを軽減することはできます。
ワークロードの種類によっては、前の可用性メトリクスが役に立たない可能性があるすべてのアベイラビリティーゾーンで、エラーが一貫して発生することがあります。例えば AWS Lambda の場合について検討してみましょう。AWS は、カスタマーが独自のコードを作成して Lambda 関数で実行できるようにします。このサービスを使用するには、依存関係を含むコードを ZIP ファイルにアップロードし、関数へのエントリポイントを定義する必要があります。しかし、カスタマーはこの部分を間違えることがあります。例えば、ZIP ファイルの重要な依存関係を忘れたり、Lambda 関数定義のメソッド名を間違えたりすることがあります。これにより、関数が呼び出されず、エラーが発生します。AWS Lambda では、この種のエラーは常に発生しますが、必ずしも異常であることを示すものではありません。ただし、アベイラビリティーゾーンの障害などが原因でこれらのエラーが表示されることもあります。
この種のノイズに含まれるシグナルを見つけるには、外れ値検出を使用して、アベイラビリティーゾーン間でエラー数に統計的に有意な偏りがあるかどうかを判断できます。複数のアベイラビリティーゾーンでエラーが見られるものの、そのうちの 1 つで本当に障害が発生した場合、そのアベイラビリティーゾーンでは他のアベイラビリティーゾーンに比べてエラー率が大幅に高くなるか、はるかに低くなる可能性があります。しかし、どれくらい高い、または低いのでしょうか。
この分析を行う方法の 1 つは、カイ二乗
カイ二乗検定では、何らかの結果の分布が生じる確率を評価します。ここでは、一連の定義済みの AZ 全体にわたるエラーの分布を調べます。この例では、計算を簡単にするために、4 つのアベイラビリティーゾーンを考えてみます。
まず、帰無仮説を立てます。これにより、何をデフォルトの結果と信じるかを定義します。この検定では、帰無仮説として、エラーは各アベイラビリティーゾーンに均等に分布していると予想します。次に、エラーは均等に分布しておらず、アベイラビリティーゾーンの障害が示唆されているという対立仮説を立てます。これで、メトリクスのデータを使用して、これらの仮説を検定できるようになります。この目的のために、5 分間のウィンドウからメトリクスをサンプリングします。このウィンドウに 1,000 個の公開されたデータポイントがあり、合計で 100 個のエラーが確認されたとします。均等な分布では、4 つのアベイラビリティーゾーンのそれぞれで 25% の確率でエラーが発生すると予想されます。次の表は、予想した結果と実際の結果の比較を示しているものとします。
表 1: 予想したエラーと実際に確認されたエラー
| AZ | 予想 | 実際 |
|---|---|---|
use1-az1 |
25 | 20 |
use1-az2 |
25 | 20 |
use1-az3 |
25 | 25 |
use1-az4 |
25 | 35 |
したがって、実際には分布が均等ではないことがわかります。ただし、サンプリングしたデータポイントにある程度のランダム性があったために、このような結果になったとも考えられます。この種の分布がサンプルセットで発生する可能性がある程度あると、帰無仮説がまだ成り立つ余地があります。これは次の質問につながります。少なくともこれくらいの極端な結果が得られる確率はどれくらいであるか。その確率が定義したしきい値を下回っている場合は、帰無仮説を棄却します。統計的に有意である
1 Craparo, Robert M. (2007). 「有意水準」。Salkind, Neil J、Encyclopedia of Measurement and Statistics3. Thousand Oaks、CA: SAGE Publications。889〜891ページ。ISBN 1-412-91611-9.
この結果の確率は、どのように計算すればよいでしょうか。よく研究された分布を提供する χ2 統計を使用します。これは、この公式を使ってこれくらい極端な、あるいはもっと極端な結果が得られる確率を決定できます。
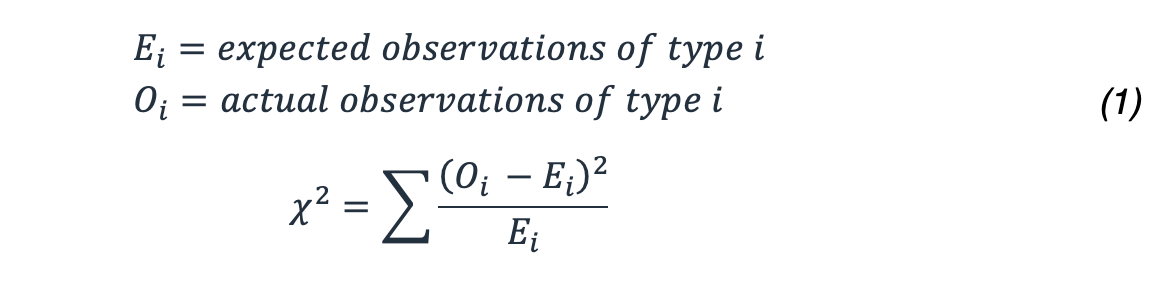
この例では、次のような結果になります。
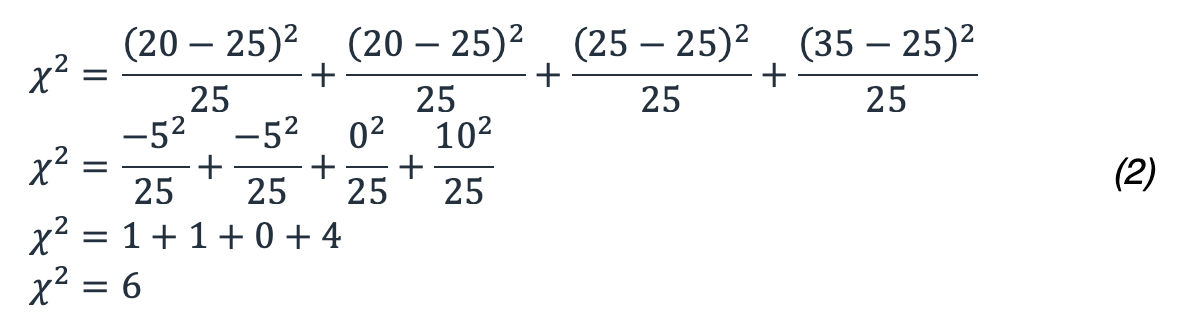
それでは、確率の観点から 6 は何を意味するでしょうか。カイ二乗分布は、適切な自由度で調べる必要があります。次の図は、さまざまな自由度でいくつかの異なるカイ二乗分布を示しています。

さまざまな自由度でのカイ二乗分布
自由度は、テストの選択肢の数より 1 つ少ない数として計算します。この場合、アベイラビリティーゾーンは 4 つあるため、自由度は 3 になります。次に、k = 3 プロットで x ≥ 6 の曲線の下の面積 (積分) を知りたいとします。一般的に使用される値を含む、事前に計算された表を使用して、その値を概算することもできます。
表 2: カイ二乗の臨界値
| 自由度 | 臨界値を下回る確率 | ||||
|---|---|---|---|---|---|
| 0.75 | 0.90 | 0.95 | 0.99 | 0.999 | |
| 1 | 1.323 | 2.706 | 3.841 | 6.635 | 10.828 |
| 2 | 2.773 | 4.605 | 5.991 | 9.210 | 13.816 |
| 3 | 4.108 | 6.251 | 7.815 | 11.345 | 16.266 |
| 4 | 5.385 | 7.779 | 9.488 | 13.277 | 18.467 |
自由度が 3 の場合、カイ二乗値 6 は、確率列 0.75 および 0.9 の間になります。つまり、この分布が発生する可能性は 10% を超え、しきい値の 5% を下回らないということです。したがって、帰無仮説を受け入れ、アベイラビリティーゾーン間のエラー率には統計的に有意な差はないと判断します。
カイ二乗統計テストの実行は CloudWatch メトリクスの計算ではネイティブにサポートされていないため、CloudWatch から該当するエラーメトリクスを収集し、Lambda などのコンピューティング環境でテストを実行する必要があります。このテストは、MVC コントローラー/アクション、個々のマイクロサービスレベル、またはアベイラビリティーゾーンレベルなどで実行するかを決めることができます。アベイラビリティーゾーンの障害が各コントローラー/アクションまたはマイクロサービスに等しく影響するのか、それとも DNS 障害のようなものが高いスループットのサービスではなく低いスループットのサービスに影響を与えてるのか、つまり集約したときにその影響を隠すことができるのかをについて検討する必要があります。いずれの場合も、適切なディメンションを選択してクエリを作成します。詳細度のレベルは、作成する結果の CloudWatch アラームにも影響します。
指定された時間枠内の各 AZ とコントローラー/アクションのエラー数メトリクスを収集します。まず、カイ二乗検定の結果を true (統計的に有意な偏りがあった) または false (なかった、つまり帰無仮説が成立する) のいずれかで計算します。結果が false の場合は、各アベイラビリティーゾーンの結果をカイ二乗するため、メトリクスストリームに 0 データポイントをパブリッシュします。結果が true の場合は、エラーが予想値から最も遠いアベイラビリティーゾーンの 1 データポイント、その他には 0 データポイントをパブリッシュします (Lambda 関数で使用できるサンプルコードについては 付録 B — カイ二乗計算の例 を参照)。Lambda 関数によって生成されるデータポイントに基づいて、3 つ連続の CloudWatch メトリクスアラームと 5 つのうち 3 つの CloudWatch メトリクスアラームを作成することで、以前の可用性アラームと同じアプローチをとることができます。前の例と同様に、この方法を変更して、短い枠または長い枠で使用するデータポイントを増減することができます。
次に、以下の図に示すように、コントローラーとアクションの組み合わせの既存のアベイラビリティーゾーンにこれらのアラームを追加します。

カイ二乗統計検定と複合アラームの統合
前述のように、ワークロードに新しい機能をオンボードするとき、その新機能に固有の適切な CloudWatch メトリクスアラームを作成し、複合アラーム階層の次の層を更新してそれらのアラームを含めるのみになります。残りのアラーム構造は変化しません。
