可用性の測定
前に説明したとおり、分散システムの将来を見据えた可用性モデルを作成することは困難で、必要な洞察が得られない場合があります。そこで有用なのは、ワークロードの可用性を測定する一貫した方法を開発することです。
可用性を稼働時間とダウンタイムとして定義すると、障害はバイナリーオプションとして表されます。つまりワークロードが稼働しているか、稼働していないかのどちらかです。
ただし、これは稀なケースです。障害にはある程度の影響があり、多くの場合、ワークロードの一部で発生し、一部のユーザーまたはリクエスト、一部の場所、または一部のレイテンシに影響を与える場合があります。これらはすべて部分的障害モードです。
また、MTTR と MTBF は、何がシステムの可用性に影響するのか、そしてそれをどのように改善するのかを理解するのに役立ちますが、その有用性は可用性の経験的な尺度としては役に立ちません。さらに、ワークロードは多くのコンポーネントで構成されています。例えば、支払い処理システムなどのワークロードは、多くのアプリケーションプログラミングインターフェイス (API) とサブシステムで構成されています。そこで、「ワークロード全体の可用性はどの程度か」というような質問は、実際には複雑で微妙な質問となります。
このセクションでは、可用性を経験的に測定する 3 つの方法、つまりサーバー側のリクエスト成功率、クライアント側のリクエスト成功率、および年間ダウンタイムについて説明します。
サーバー側とクライアント側のリクエスト成功率
最初の 2 つの方法は非常に似ており、測定する観点のみが異なります。サーバー側のメトリクスは、サービスの計測から収集できます。しかし、これらは完全ではありません。クライアントがサービスにアクセスできない場合、それらのメトリクスを収集することはできません。クライアントエクスペリエンスを理解するには、失敗したリクエストに関するクライアントからのテレメトリに頼ってはいけません。より簡単なのは、サービスを定期的に調査してメトリックを記録するソフトウェアの canary を使用しカスタマートラフィックをシミュレートすることがクライアント側のメトリクスを収集することです。
この 2 つの方法では、可用性は、サービスが受け取った有効な作業単位と正常に処理された作業単位の合計に対する割合として計算されます (404 エラーになる HTTP リクエストなどの無効な作業単位は無視されます)。

方程式 8
リクエストベースのサービスの場合、作業単位は HTTP リクエストと同様にリクエストです。イベントベースまたはタスクベースのサービスの場合、作業単位はイベントまたはタスク (キュー外のメッセージの処理など) です。この可用性の測定は、1 分または 5 分といった短い時間間隔では意味があります。また、リクエストベースのサービスの API レベル別の場合など、きめ細かい観点からも最適です。次の図は、この方法で計算した場合、時間の経過に伴って可用性がどのように変化するかを示しています。グラフの各データポイントは、式 (8) を使用して 5 分間隔で計算されます (1 分または 10 分間隔など、他の時間軸も選択できます)。例えば、データポイント 10 では 94.5% の可用性が示されています。つまり、t+45 から t+50 までの間に、サービスが 1,000 件のリクエストを受け取ったとしても、そのうち正常に処理されたのはそのうちの 945 件だけでした。
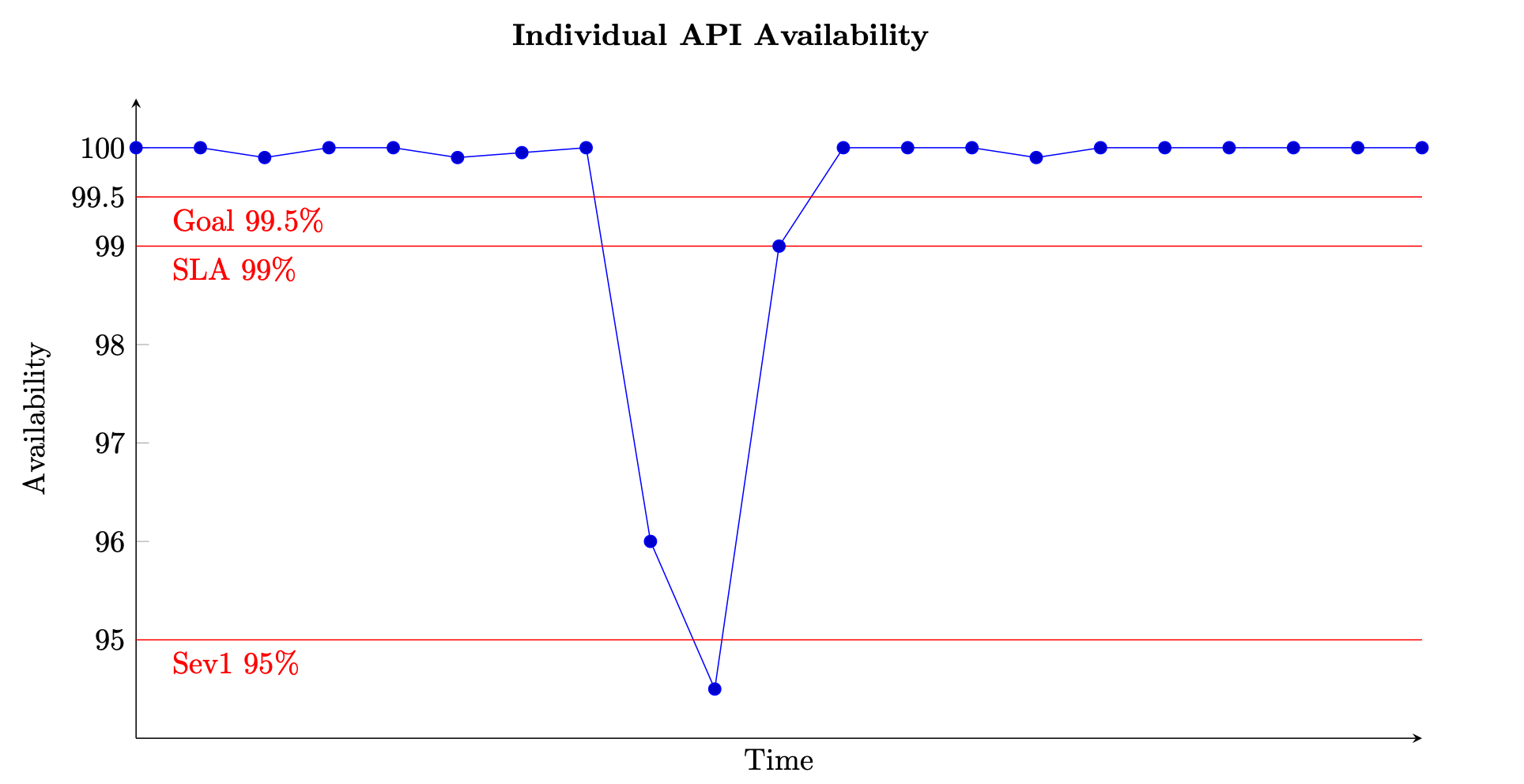
単一の API の可用性を時系列で測定する例
このグラフには、API の可用性目標である 99.5%、カスタマーに提供するサービスレベルアグリーメント (SLA)、99% の可用性、および重要度の高いアラームのしきい値(95%) も示されています。これらの各種しきい値のコンテキストが欠如すると、可用性のグラフではサービスの稼働状況に関する重要な分析情報が得られない可能性があります。
また、コントロールプレーンなどの大規模なサブシステムやサービス全体の可用性を追跡し、説明できることが理想です。その方法の 1 つは、各サブシステムの 5 分間のデータポイントの平均を取ることです。このグラフは前のグラフと似ていますが、より多数の入力を表しています。また、サービスを構成するすべてのサブシステムに同等の重みを与えています。別の方法として、サービス内のすべての API から受け取り、正常に処理されたすべてのリクエストを合計して、5 分間隔で可用性を計算することもできます。
ただし、後者の方法では、スループットが低く、可用性の低い個々の API は表されない可能性があります。簡単な例として、2 つの API を持つサービスについて考えてみましょう。
最初の API は 5 分以内に 1,000,000 件のリクエストを受け取り、そのうちの 999,000 件を正常に処理するため、99.9% の可用性を実現しています。2 番目の API は、同じ 5 分間にリクエストを 100 件受け取り、そのうちの 50 件しか正常に処理しないため、可用性が 50% です。
各 API からのリクエストを合計すると、合計で 1,000,100 件の有効なリクエストがあり、そのうちの 999,050 件が正常に処理され、サービス全体の可用性は 99.895% になります。ただし、前者の方法のように 2 つの API の可用性を平均すると、74.95%の可用性となり、実際のエクスペリエンスがより正しく表現している可能性があります。
どちらのアプローチも間違っていませんが、可用性のメトリクスが伝える内容を理解することが重要です。ワークロードが各サブシステムで同様のリクエスト量を受け取っている場合は、すべてのサブシステムのリクエストの合計を選択することもできます。このアプローチは、可用性とカスタマーエクスペリエンスの尺度としての「リクエスト」とその成功に焦点を当てています。あるいは、リクエスト量が異なっても、サブシステムの可用性を平均して、その重要度を等しく表すこともできます。このアプローチは、サブシステムおよびカスタマーエクスペリエンスのプロキシとしての各サブシステムの能力に焦点を当てています。
年間ダウンタイム
3 つ目のアプローチは、年間ダウンタイムを計算することです。この形式の可用性マトリクスは、長期的な目標設定とレビューに適しています。ダウンタイムがワークロードにとって何を意味するのかを定義する必要があります。これにより、特定の期間の合計時間 (分) に対してワークロードが「停止」状態ではない時間 (分) を基に可用性を測定できます。
ワークロードによっては、単一の API またはワークロード関数が 1 分または 5 分間隔で 95% の可用性を下回るようなものとして、ダウンタイムを定義できる場合があります (これは前述の可用性グラフで発生しました)。また、ダウンタイムが重要なデータプレーンのオペレーションのサブセットに適用されるときのみ検討する場合があるかもしれません。例えば、SQS の可用性に関する Amazon メッセージング (SQS、SNS) サービスレベルアグリーメント
大規模で複雑なワークロードでは、システム全体の可用性メトリクスの定義が必要な場合があります。大規模な e コマースサイトの場合、システム全体のメトリクスはカスタマーの注文率のようなものです。この場合、5 分間のうちに、予測数量と比較して 10% 以上注文が減少した場合に、ダウンタイムとなる可能性があります。
いずれの方法でも、すべての停止期間を合計して年間の可用性を計算できます。例えば、ある暦年に 5 分間のダウンタイムが 27 回発生した場合 (データプレーン API の可用性が 95% を下回ったと定義)、全体のダウンタイムは 135 分で (5 分間は連続していた場合と分離していた場合がある)、つまり、年間可用性は 99.97% です。
この可用性を測定する追加の方法を使うと、クライアント側とサーバー側のメトリクスにはないデータや洞察が得られる可能性があります。例えば、障害が発生し、エラー率が大幅に上昇しているワークロードについて考えてみましょう。このワークロードのカスタマーは、そのサービスへの呼び出しをすべて停止する可能性があります。もしかすると、回路遮断器を作動させたり、ディザスタリカバリ計画
レイテンシー
最後に、ワークロード内の処理単位のレイテンシーを測定することも重要です。可用性は一部として、確立された SLA の範囲内で作業を行うことと定義されます。レスポンスを返すのにクライアントのタイムアウトよりも時間がかかる場合、クライアントはリクエストが失敗し、ワークロードが利用できないと認識します。ただし、サーバー側では、リクエストが正常に処理されたように見える場合があります。
レイテンシーの測定は、可用性を評価するもう 1 つの方法となります。この測定では、パーセンタイルとトリミング平均を使用するのが適切な統計方法です。通常、50 パーセンタイル (P50 と TM50) と 99 パーセンタイル (P99 と TM99) で測定されます。レイテンシーは、クライアントエクスペリエンスを表す canary とサーバー側のメトリクスで測定する必要があります。P99 や TM99.9 など、あるパーセンタイルのレイテンシーの平均が目標 SLA を上回る場合は、常にそのダウンタイムを考慮して、年間ダウンタイムの計算に役立てることができます。
