This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data transformation
Event format and changing schema
Data at rest can be tuned to one format; however, it is not easy for all source systems to match that. Events generated at the source systems can vary depending on the use case and underlying technology. It is critical to build a data pipeline that can evolve and match with such a high degree of variance. For example, a product analytics workload will typically use a finite number of fields such as userid, timestamp, and productid, whereas a game event workload has fields that are unique to the game, scenario, and device type.
There are two approaches to this high-level scenario:
-
AWS has source systems, which are your upstream dependencies, that generate and collect the data. The source systems then use an ETL or extract, load and transform (ELT) mechanism to modify the data. There are transformation engines that are built for large-scale data processing to handle batch and/or streaming data. We then have the downstream dependencies that consume all or part of the data, which eventually makes its way to the data lake.
-
This is a similar approach as the first, with the key difference being a scenario for an unknown format. For this, you can use a data classifier that can read the data from the data store for known formats, and a custom-classifier to read the data when a new format emerges.
Transform/analytics engine
Whether you are generating a few gigabytes or are collecting and
storing multiple petabytes of user and game data every month, you
want to have a few questions answered ahead of time to transform
data efficiently and avoid a
data
swamp
-
How much data is coming in daily and monthly, and what does that growth look like over time?
-
What is the format and schema of the data?
-
Average file size?
-
How many sources?
-
Who will the stewards of the data be?
-
What type of transformations need to be done?
-
Who are the consumers?
-
How will the data be secured, governed and audited?
This is not a comprehensive list, but should start to give you an idea as to considerations and necessary decisions to make in order to run an efficient and scalable data lake. When talking about extracting, transforming, and loading data, there is not one tool that is the best for every use case. Instead, AWS offers many tools and options based on challenging use cases that customers have asked AWS to help with.
-
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. With AWS Glue, you can do data discovery, transformation, replication, and preparation with many of the different tools AWS Glue
offers. -
Streaming ETL jobs - With AWS Glue streaming ETL, you can consume data coming in from Amazon Kinesis Data Streams or Apache Kafka. This is useful when you need to transform and process your data in real-time, and load into downstream services such as databases, or a data warehouse such as Amazon Redshift
, which can be used to power a real-time dashboard for user behavior, fraudulent activity, game metrics, and more. -
Batch ETL jobs - You may not always need to transform data in real-time as you would with AWS Glue streaming. Instead, you can implement a batching strategy for your ETL jobs that can be scheduled to run as frequently or infrequently as needed. You can run batch ETL jobs for complex types of aggregations and joins of datasets. Some popular use cases for using batch jobs include:
-
Migrating table data from transactional databases to Amazon S3 for analysis of other downstream services such as Amazon Athena. You can then visualize this data with QuickSight
by using Amazon Athena as the query engine. -
Loading data from Amazon S3 into Amazon Redshift, where you can also use Amazon Redshift as the query engine for your BI tools.
-
Pre-aggregating and joining data in order to prepare a dataset to be consumed by Amazon SageMaker AI
, the fully managed ML service.
-
-
AWS Glue Elastic Views
makes it easy to build materialized views that combine and replicate data across multiple data stores without you having to write custom code. With AWS Glue Elastic Views, you can use familiar Structured Query Language (SQL) to quickly create a virtual table—a materialized view—from multiple different source data stores. Replicating and keeping data synced across different data stores is much easier with Elastic Views, as you only need to write an SQL query to start creating the materialized views in your target data stores. You no longer need to spend time developing AWS Lambda functions to read off of streams and then write the records to the target data store, or run AWS Glue jobs every five minutes or so just to keep data fresh.
-
AWS Glue DataBrew
is a visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and ML. You can choose from over 250 pre-built transformations to automate data preparation tasks, all without the need to write any code. AWS Glue DataBrew is a great option if you want to load your dataset into a visual editor, and then transform your data step-by-step. These steps are saved into a recipe, which is reusable, so you can consistently run and schedule DataBrew jobs with the recipes you create. 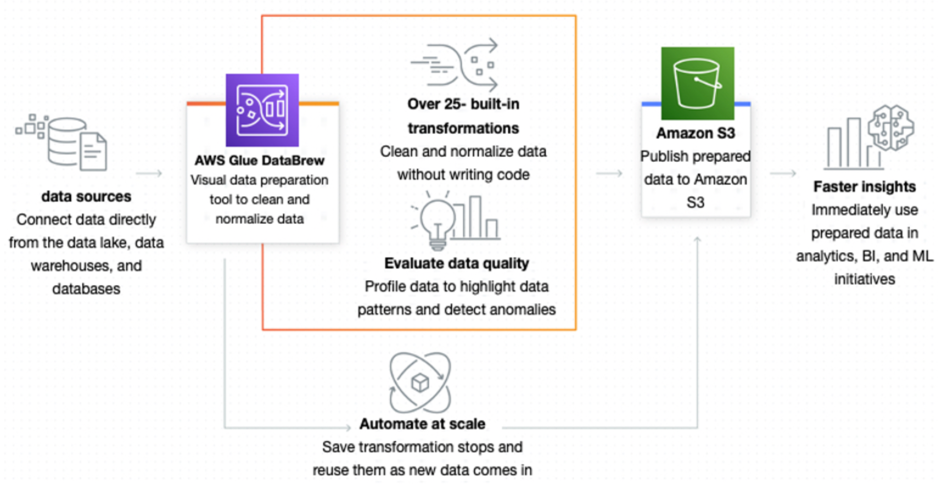
How AWS Glue DataBrew helps clean and normalize data
-
Amazon EMR
(previously called Amazon Elastic MapReduce) is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark , on AWS to process and analyze vast amounts of data. Using these frameworks and related open-source projects, you can process data for analytics purposes and BI workloads. Amazon EMR also lets you transform and move large amounts of data into and out of other AWS data stores and databases, such as Amazon S3 and Amazon DynamoDB. You would want to run an EMR cluster for your ETL operations if your use cases revolve around ETL jobs running 24/7, or you need to manage other tools such as Apache Hadoop, Apache HBase, Presto, Hive, and so on. -
Amazon Athena
is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. You can query data stores other than in S3, such as RDS databases, on premises databases, Amazon DynamoDB, ElastiCache (Redis OSS), Amazon Timestream, and more with Athena federated queries. With this functionality, you can combine and move data from many data stores using Athena. Athena is a great tool for ad-hoc data exploration, and benefits most when your data lake is built according to user query patterns. A common pattern and good place to start if you aren’t sure about what the query patterns are yet is to partition your data as year, month, and day. By doing this, you can use Athena to filter only the partitions you need to access, which will result in a reduction of cost and faster results per query. Athena can also be used as a lightweight ETL tool if you need to process a smaller subset of data through the use of the Create Table as Select (CTAS), where you can format, compress, and partition raw data into an optimized format to be consumed by downstream engines.
-
Amazon Redshift
is the fastest and most widely used cloud data warehouse. Amazon Redshift is integrated with your data lake and offers up to 3x better price performance than any other data warehouse. Amazon Redshift can help power your data lake when you have longer running, complex queries that need to aggregate large amounts of data. You can move data in and out of Amazon Redshift using integrated tools such as AWS Glue, Amazon EMR, AWS Database Migration Service (AWS DMS), Amazon Data Firehose, and more.
