ElastiCache (Redis OSS)
So far, we've been talking about ElastiCache (Memcached) as a passive component in our application—a big slab of memory in the cloud. Choosing Redis as our engine can unlock more interesting possibilities for our application, due to its higher-level data structures such as lists, hashes, sets, and sorted sets.
Deploying Redis makes use of familiar concepts such as clusters and nodes. However, Redis has a few important differences compared with Memcached:
-
Redis data structures cannot be horizontally sharded. As a result, ElastiCache (Redis OSS) clusters are always a single node, rather than the multiple nodes we saw with Memcached.
-
Redis supports replication, both for high availability and to separate read workloads from write workloads. A given ElastiCache (Redis OSS) primary node can have one or more replica nodes. A Redis primary node can handle both reads and writes from the app. Redis replica nodes can only handle reads, similar to Amazon RDS Read Replicas.
-
Because Redis supports replication, you can also fail over from the primary node to a replica in the event of failure. You can configure ElastiCache (Redis OSS) to automatically fail over by using the Multi-AZ feature.
-
Redis supports persistence, including backup and recovery. However, because Redis replication is asynchronous, you cannot completely guard against data loss in the event of a failure. We will go into detail on this topic in our discussion of Multi-AZ.
Architecture with ElastiCache (Redis OSS)
As with Memcached, when you deploy an ElastiCache (Redis OSS) cluster, it is an additional tier in your app. Unlike Memcached, ElastiCache (Redis OSS) clusters only contain a single primary node. After you create the primary node, you can configure one or more replica nodes and attach them to the primary Redis node. An ElastiCache (Redis OSS) replication group consists of a primary and up to five read replicas. Redis asynchronously replicates the data from the primary to the read replicas.
Because Redis supports persistence, it is technically possible to use Redis as your only data store. In practice, customers find that a managed database such as Amazon DynamoDB or Amazon RDS is a better fit for most use cases of long-term data storage.
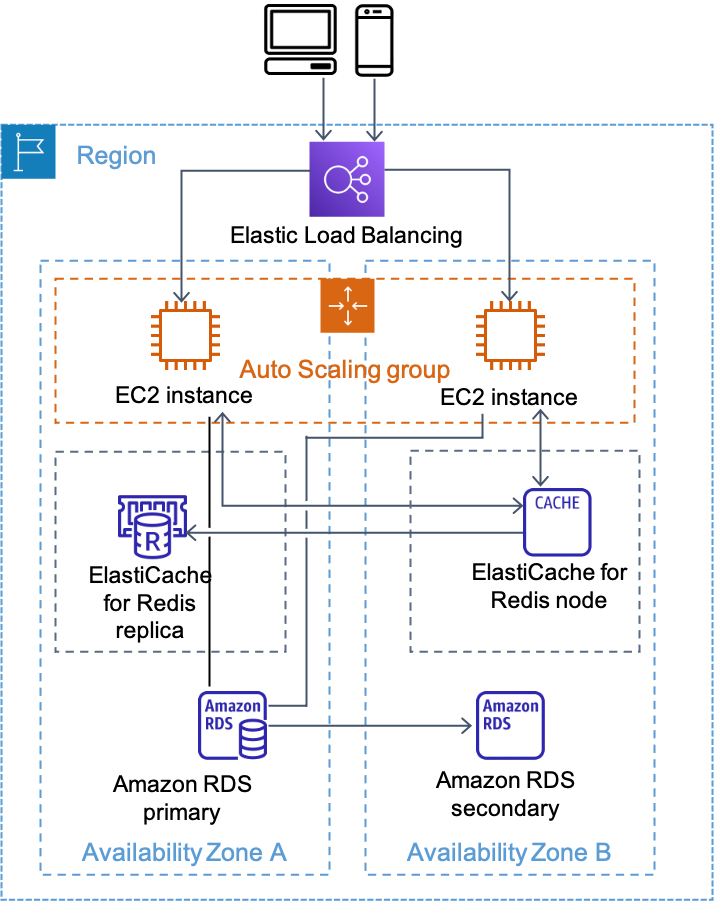
Amazon ElastiCache (Redis OSS)
ElastiCache (Redis OSS) has the concept of a primary endpoint, which is a DNS name that always points to the current Redis primary node. If a failover event occurs, the DNS entry will be updated to point to the new Redis primary node. To take advantage of this functionality, make sure to configure your Redis client so that it uses the primary endpoint DNS name to access your Redis cluster.
Keep in mind that the number of Redis replicas you attach will affect the performance of the primary node. Resist the urge to spin up lots of replicas just for durability. One or two replicas in a different Availability Zone are sufficient for availability. When scaling read throughput, monitor your application's performance and add replicas as needed. Be sure to monitor your ElastiCache cluster's performance as you add replica nodes. For more details, refer to Monitoring and tuning later in this whitepaper.
Distributing reads and writes
Using read replicas with Redis, you can separate your read and write workloads. This separation lets you scale reads by adding additional replicas as your application grows. In this pattern, you configure your application to send writes to the primary endpoint.
Then you read from one of the replicas, as shown in the following diagram. With this approach, you can scale your read and write loads independently, so your primary node only has to deal with writes.
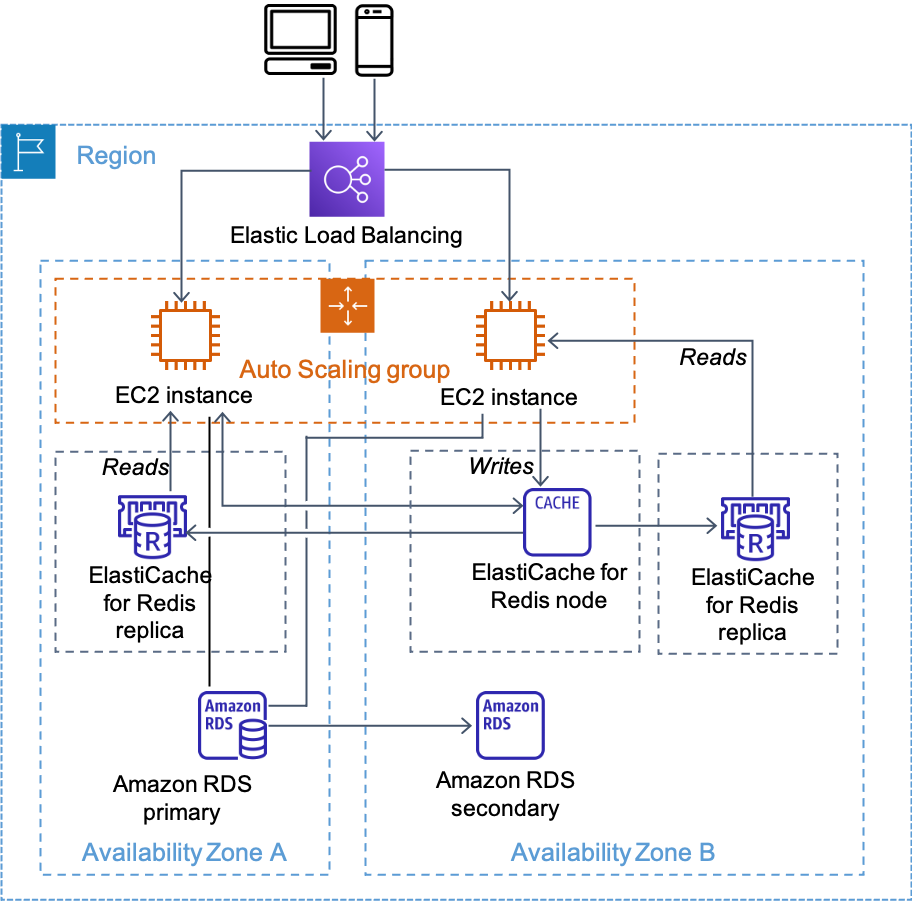
Distributing reads and writes
The main caveat to this approach is that reads can return data that is slightly out of date compared to the primary node, because Redis replication is asynchronous. For example, if you have a global counter of "total games played" that is being continuously incremented (a good fit for Redis), your master might show 51,782. However, a read from a replica might only return 51,775. In many cases, this is just fine. But if the counter is a basis for a crucial application state, such as the number of seconds remaining to vote on the most popular pop singer, this approach won't work.
When deciding whether data can be read from a replica, here are a few questions to consider:
-
Is the value being used only for display purposes? If so, being slightly out of date is probably okay.
-
Is the value a cached value, for example a page fragment? If so, again being slightly out of date is likely fine.
-
Is the value being used on a screen where the user might have just edited it? In this case, showing an old value might look like an application bug.
-
Is the value being used for application logic? If so, using an old value can be risky.
-
Are multiple processes using the value simultaneously, such as a lock or queue? If so, the value needs to be up-to-date and needs to be read from the primary node.
In order to split reads and writes, you will need to create two separate Redis connection handles in your application: one pointing to the primary node, and one pointing to the read replica(s). Configure your application to write to the DNS primary endpoint, and then read from the other Redis nodes.
Multi-AZ with auto-failover
During certain types of planned maintenance, or in the unlikely event of ElastiCache node failure or Availability Zone failure, Amazon ElastiCache can be configured to automatically detect the failure of the primary node, select a read replica, and promote it to become the new primary. ElastiCache auto-failover will then update the DNS primary endpoint with the IP address of the promoted read replica. If your application is writing to the primary node endpoint as recommended earlier, no application change will be needed.
Depending on how in-sync the promoted read replica is with the primary node, the failover process can take several minutes. First, ElastiCache needs to detect the failover, then suspend writes to the primary node, and finally complete the failover to the replica. During this time, your application cannot write to the ElastiCache (Redis OSS) cluster. Architecting your application to limit the impact of these types of failover events will ensure greater overall availability.
Unless you have a specific need otherwise, all production deployments should use Multi-AZ with auto-failover. Keep in mind that Redis replication is asynchronous, meaning if a failover occurs, the read replica that is selected might be slightly behind the master.
Bottom line: Some data loss might occur if you have rapidly changing data. This effect is currently a limitation of Redis replication itself. If you have crucial data that cannot be lost (for example, transactional or purchase data), we recommend that you also store that in a durable database such as Amazon DynamoDB or Amazon RDS.
Sharding with Redis
Redis has two categories of data structures: simple keys and counters, and multidimensional sets, lists, and hashes. The bad news is the second category cannot be sharded horizontally. But the good news is that simple keys and counters can.
In the simplest case, you can treat a single Redis node just like a single Memcached node. Just like you might spin up multiple Memcached nodes, you can spin up multiple Redis clusters, and each Redis cluster is responsible for part of the sharded dataset.

Sharding with Redis
In your application, you'll then need to configure the Redis client to shard between those two clusters. Here is an example from the Jedis Sharded Java Client:
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>(); shards.add(new JedisShardInfo("redis-cluster1", 6379)); shards.add(new JedisShardInfo("redis-cluster2", 6379)); ShardedJedisPool pool = new ShardedJedisPool(shards); ShardedJedis jedis = pool.getResource();
You can also combine horizontal sharding with split reads and writes. In this setup, you have two or more Redis clusters, each of which stores part of the key space. You configure your application with two separate sets of Redis handles, a write handle that points to the sharded masters and a read handle that points to the sharded replicas. Following is an example architecture, this time with Amazon DynamoDB rather than MySQL, just to illustrate that you can use either one:

Example architecture with DynamoDB
For the purpose of simplification, the preceding diagram shows replicas in the same Availability Zone as the primary node. In practice, you should place the replicas in a different Availability Zone. From an application perspective, continuing with our Java example, you configure two Redis connection pools as follows:
List<JedisShardInfo> masters = new ArrayList<JedisShardInfo>(); masters.add(new JedisShardInfo("redis-masterA", 6379)); masters.add(new JedisShardInfo("redis-masterB", 6379)); ShardedJedisPool write_pool = new ShardedJedisPool(masters); ShardedJedis write_jedis = write_pool.getResource(); List<JedisShardInfo> replicas = new ArrayList<JedisShardInfo>(); replicas.add(new JedisShardInfo("redis-replicaA", 6379)); replicas.add(new JedisShardInfo("redis-replicaB", 6379)); ShardedJedisPool read_pool = new ShardedJedisPool(replicas); ShardedJedis read_jedis = read_pool.getResource();
In designing your application, you need to make decisions as to whether a given value can be read from the replica pool, which might be slightly out of date, or from the primary write node. Be aware that reading from the primary node will ultimately limit the throughput of your entire Redis layer, because it takes I/O away from writes.
Using multiple clusters in this fashion is the most advanced configuration of Redis possible. In practice, it is overkill for most applications. However, if you design your application so that it can leverage a split read/write Redis layer, you can apply this design in the future, if your application grows to the scale where it is needed.
