ステップ 4: 予測子を評価する
機械学習の一般的なワークフローでは、モデル一式またはモデルの組み合わせをトレーニングセットでトレーニングし、ホールドアウトデータセットでその精度を評価します。このセクションでは、履歴データを分割する方法と、時系列予測でモデルを評価するために使用する指標について説明します。予測では、バックテスト手法が予測精度を評価するための主要なツールとなっています。
バックテスト
適切な評価とバックテストのフレームワークは、機械学習アプリケーションを成功に導く上で最も重要な要素の 1 つです。モデルのバックテストが成功すれば、モデルの将来の予測能力に自信が持てるようになります。さらに、ハイパーパラメーター最適化 (HPO) によるモデルのチューニング、モデルの組み合わせの学習、メタ学習と AutoML の有効化可能です。
時系列予測が、評価やバックテストの方法論の観点から、応用機械学習の他の分野とは異なるのは、その特性である時間に起因しています。通常、ML タスクでは、バックテストの予測エラーを評価するために、データセットを項目ごとに分割します。たとえば、画像関連のタスクでの交差検証では、何割かの画像でトレーニングを行い、それ以外の部分をテストと検証に使用します。予測では、トレーニングセットからテストセットや検証セットに情報が漏れないように、また本稼働環境でのケースをできる限り厳密にシミュレートするために、主に時間別に (また主にではないが項目別に) 分割する必要があります。
1 つの時点を選択するのではなく、複数の時点を選択する必要があるため、時間による分割は慎重に行う必要があります。そうしないと、分割点によって定義される予測開始日に精度が影響されすぎてしまいます。複数の時点で一連の分割を行い、平均結果を出力するローリング予測評価では、より確実で信頼性の高いバックテスト結果が得られます。次の図は、4 つの異なるバックテスト分割を示しています。

トレーニングセットのサイズは大きくなるが、テストのサイズは一定である 4 つの異なるバックテストシナリオの図
上の図では、すべてのバックテストシナリオに、予測値を実際の値と比較して評価できるように、全体を通して利用可能なデータがあります。
複数のバックテスト時間枠が必要な理由は、現実世界のほとんどの時系列が通常は非定常であるためです。このケーススタディの e コマースビジネスは北米を拠点としており、その製品需要の多くは第 4 四半期に集中し、特に感謝祭前後とクリスマス前にピークを迎えます。第 4 四半期のショッピングシーズンでは、時系列の変動が一年の他の時期よりも大きくなります。バックテストの時間枠を複数用意することで、よりバランスの取れた設定で予測モデルを評価できます。
各バックテストシナリオについて、次の図は Amazon Forecast の用語の基本要素を示しています。Amazon Forecast は、データをトレーニングデータセットとテストデータセットに自動的に分割します。Amazon Forecast は、create_predictor API でパラメータとして指定されている BackTestWindowOffset パラメータまたは ForecastHorizon のデフォルト値を使用して、入力データをどのように分割するかを決定します。
次の図では、BackTestWindowOffset パラメータと ForecastHorizon パラメータが等しくない場合の、より一般的な前者のケースを示しています。この BackTestWindowOffset パラメータは、仮想の予測開始日を定義します。次の図では、縦の破線で示されています。これを使うと、この日にモデルが導入されたら、どのような予測になるかというような仮説的な疑問に答えることができます。 ForecastHorizon は、仮想予測開始日から予測するタイムステップ数を定義します。
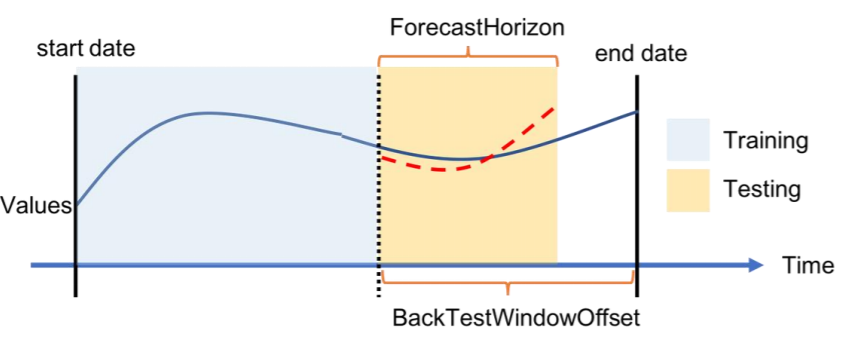
Amazon Forecast での単一バックテストシナリオとその設定の図
Amazon Forecast は、バックテスト中に生成された予測値と精度指標をエクスポートできます。エクスポートされたデータを使用して、特定の時点と分位数における特定の項目を評価できます。
予測分位数と精度指標
予測分位数では、予測値の上限と下限を指定できます。たとえば、0.1 (P10)、0.5 (P50)、0.9 (P90) の予測タイプを使用すると、P50 予測に対して 80% 信頼区間と呼ばれる値の範囲が得られます。P10、P50、P90 で予測を生成すると、真の値が 80% の確率でこの範囲に入ることが期待できます。
このホワイトペーパーでは、ステップ 5 で分位数についてさらに説明しています。
Amazon Forecast では、バックテスト中に重み付き分位損失 (wQL)、二乗平均平方根誤差 (RMSE)、重み付き絶対誤差率 (WAPE) の精度指標を使用して予測子を評価します。
重み付き分位損失 (wQL)
重み付き分位損失 (wQL) エラー指標は、指定された分位点におけるモデルの予測の精度を測定します。これは、過小予測と過大予測のコストが異なる場合に特に有用です。wQL 関数の重み (τ) を設定すると、過小予測と過大予測に対して異なるペナルティが自動的に組み込まれます。
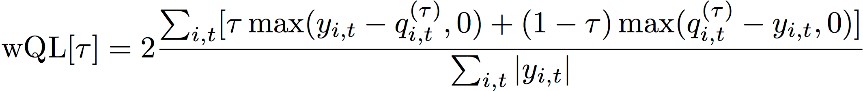
wQL 関数
各パラメータの意味は次のとおりです。
-
τ — セット {0.01, 0.02, ..., 0.99} 内の分位数
-
qi,t(τ) — モデルが予測する τ 分位数。
-
yi,t — ポイント (i,t) での観測値
重み付き絶対誤差率 (WAPE)
重み付き絶対誤差率 (WAPE) は、モデルの精度を測定するために一般的に使用される指標です。予測値と観測値の全体的な偏差を測定します。
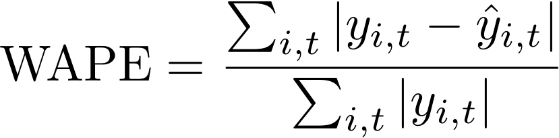
WAPE
各パラメータの意味は次のとおりです。
-
yi,t - ポイント (i,t) での観測値
-
ŷi,t - ポイント (i,t) での予測値
Forecast では、平均予測値を予測値 ŷi,t として使用します。
二乗平均平方根誤差 (RMSE)
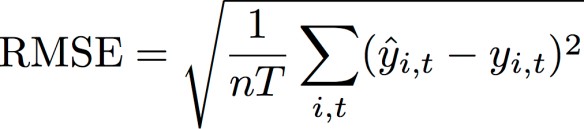
二乗平均平方根誤差 (RMSE) は、モデルの精度を測定するために一般的に使用される指標です。WAPE と同様に、予測値と観測値の全体的な偏差を測定します。
各パラメータの意味は次のとおりです。
-
yi,t - ポイント (i,t) での観測値
-
ŷi,t - ポイント (i,t) での予測値
-
nT - テストセット内のデータポイントの数
Forecast では、平均予測値を予測値 ŷi,t として使用します。予測指標を計算する場合、nT はバックテスト時間枠内のデータポイントの数です。
WAPE と RMSE に関する問題
ほとんどの場合、内部で、または他の予測ツールから生成できるポイント予測は、p50 分位数または平均予測値と一致する必要があります。WAPE と RMSE のどちらについても、Amazon Forecast は平均予測を使用して予測値 (yhat) を表します。
wQL [tau] 方程式の tau = 0.5 の場合、両方の重みが等しくなり、wQL [0.5] はポイント予測で一般的に使用されている重み付き絶対誤差率 (WAPE) になります。
![wQL[0.5] 方程式の画像。](images/wql.png)
ここでは、yhat = q(0.5) が計算予測です。wQL の式では、倍率 2 を使用して 0.5 係数を相殺し、正確な WAPE[中央値] 式を求めます。
上記の WAPE の定義は、平均絶対誤差率 (MAPE
tau が 0.5 に等しくない場合の重み付き分位損失指標とは異なり、各分位数に内在する偏りは、重みが等しい WAPE のような計算では捉えられません。WAPE のその他の欠点としては、対称性がない、数値が小さいと誤差率が過度に大きくなる、単なる点単位の指標であることなどが挙げられます。
RMSE は WAPE の誤差項の二乗で、他の機械学習アプリケーションでよく使用される誤差指標です。誤差の変動が大きいと RMSE は過度に高くなるため、RMSE 指標は個々の誤差の大きさが一定のモデルに適しています。二乗誤差のため、不適切な予測値がいくつかあるだけで、他の点では良好な予測でも、RMSE が高くなる可能性があります。また、二乗項があるため、誤差項が小さいほど、WAPE よりも RMSE での方が重みが小さくなります。
精度指標を使用すると、予測を定量的に評価できます。特に大規模な比較 (メソッド A はメソッド B より総合的に優れているのか) の場合、こうした精度指標は非常に重要です。ただし、多くの場合、これを個々の SKU のビジュアルで補うことが重要です。
