VPC에서 Amazon ECS 서비스를 연결하는 모범 사례
VPC에서 Amazon ECS 태스크를 사용할 경우 모놀리식 애플리케이션을 별도의 부분으로 분할하여 안전한 환경에서 독립적으로 배포하고 확장할 수 있습니다. 이 아키텍처를 서비스 지향 아키텍처(SOA) 또는 마이크로서비스라고 합니다. 하지만 VPC 내부와 외부 모두에서 이러한 모든 부분이 서로 통신할 수 있는지 확인하는 것이 어려울 수 있습니다. 원활한 통신을 보장하는 방법에는 여러 가지가 있지만 각각 장단점이 있습니다.
Service Connect 사용
서비스 검색, 연결 및 트래픽 모니터링을 위한 Amazon ECS 구성을 제공하는 Service Connect를 사용하는 것이 좋습니다. Service Connect를 사용하면 애플리케이션에서 짧은 이름과 표준 포트를 사용하여 동일한 리전에 있는 여러 VCP에 있는 항목을 포함하여 동일한 클러스터, 다른 클러스터의 서비스에 연결할 수 있습니다. 자세한 내용은 Amazon ECS Service Connect를 참조하세요.
Service Connect를 사용하면 Amazon ECS가 서비스 검색의 모든 부분을 관리합니다. 즉, 검색할 수 있는 이름을 생성하고, 작업이 시작 및 중지될 때 각 작업에 대한 항목을 동적으로 관리하며, 이름을 검색하도록 구성된 각 작업에서 에이전트를 실행할 수 있습니다. 애플리케이션은 DNS 이름에 대한 표준 기능을 사용하고 연결을 설정하여 이름을 조회할 수 있습니다. 애플리케이션이 이미 이 작업을 수행하는 경우 Service Connect를 사용하기 위해 애플리케이션을 수정할 필요가 없습니다.
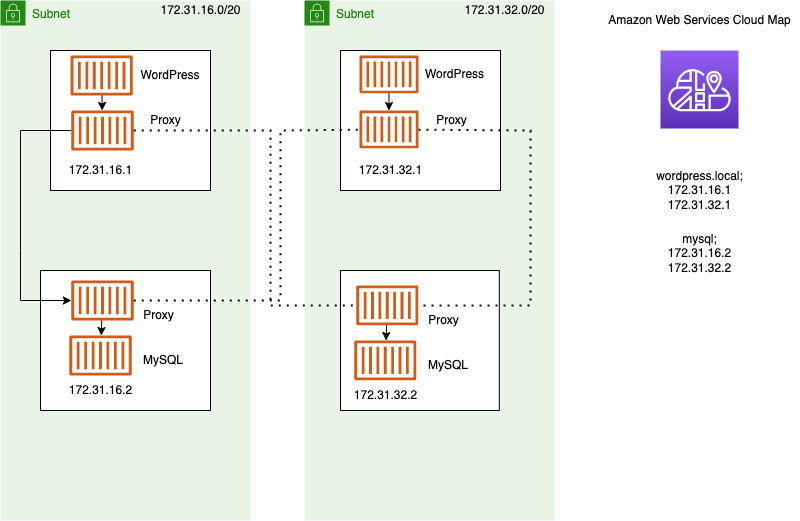
변경 사항은 배포 중에만 발생
각 서비스 및 작업 정의 내에 전체 구성을 제공합니다. Amazon ECS는 각 서비스 배포에서 이 구성의 변경 내용을 관리하여 배포의 모든 작업이 동일한 방식으로 작동하도록 합니다. 예를 들어, 서비스 검색으로 DNS에서 흔히 발생하는 문제는 마이그레이션 제어와 관련됩니다. 새 교체 IP 주소를 가리키도록 DNS 이름을 변경하는 경우 모든 클라이언트가 새 서비스를 사용하기 시작하는 데 최대 TTL 시간이 걸릴 수 있습니다. Service Connect를 사용하면 클라이언트 배포에서 클라이언트 작업을 교체하여 구성을 업데이트합니다. 다른 배포와 동일한 방식으로 Service Connect 변경 내용에 영향을 주도록 배포 회로 차단기 및 기타 배포 구성을 구성할 수 있습니다.
서비스 검색 사용
서비스 간 통신의 또 다른 접근 방식으로, 서비스 검색을 사용하는 직접 통신이 있습니다. 이 접근 방식에서는 Amazon ECS와의 AWS Cloud Map 서비스 검색 통합을 사용할 수 있습니다. Amazon ECS는 서비스 검색을 사용하여 시작된 작업 목록을 AWS Cloud Map과 동기화합니다. 이 제품에서는 해당 특정 서비스에서 하나 이상 작업에 대한 내부 IP 주소로 확인되는 DNS 호스트 이름을 유지 관리합니다. Amazon VPC의 다른 서비스는 이 DNS 호스트 이름을 사용하여 내부 IP 주소를 통해 다른 컨테이너로 직접 트래픽을 보낼 수 있습니다. 자세한 내용은 서비스 검색을 참조하세요.
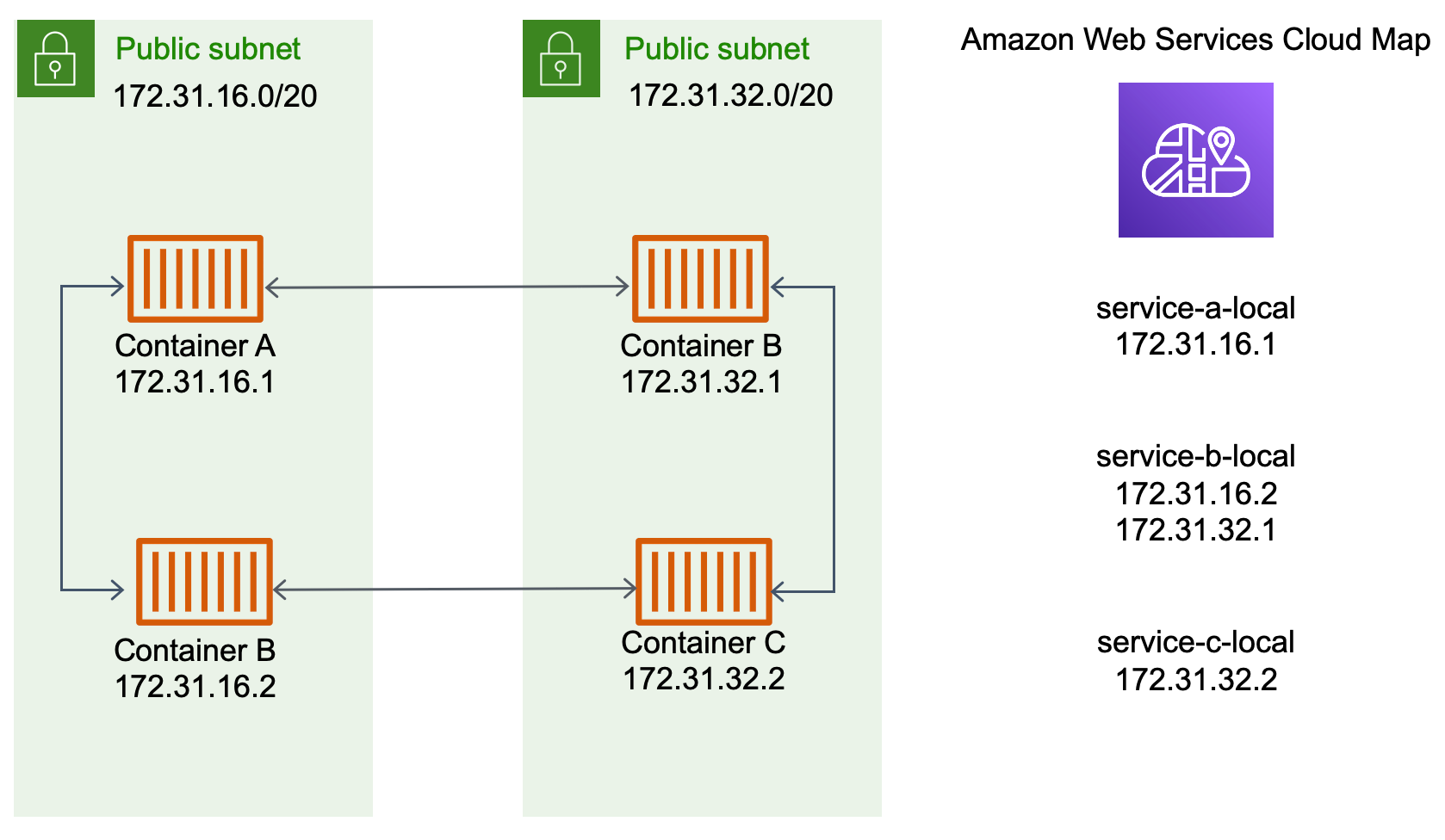
이전 다이어그램에는 세 가지 서비스가 있습니다. service-a-local에는 컨테이너가 하나 있고 컨테이너가 두 개 있는 service-b-local과 통신합니다. service-b-local도 컨테이너가 하나 있는 service-c-local과 통신해야 합니다. 세 서비스 모두에서 각 컨테이너는 AWS Cloud Map의 내부 DNS 이름을 사용하여 통신이 필요한 다운스트림 서비스의 컨테이너 내부 IP 주소를 찾을 수 있습니다.
서비스 간 통신에 대한 이러한 접근 방식은 지연 시간을 줄여줍니다. 컨테이너 사이에 추가 구성 요소가 없기 때문에 언뜻 보기에도 간단합니다. 트래픽은 한 컨테이너에서 다른 컨테이너로 직접 이동합니다.
이 접근 방식은 각 작업의 IP 주소가 고유한 awsvpc 네트워크 모드를 사용할 때 적합합니다. 대부분의 소프트웨어는 IP 주소로 직접 확인되는 DNS A 레코드 사용만 지원합니다. awsvpc 네트워크 모드를 사용하는 경우 각 작업의 IP 주소는 A 레코드입니다. 하지만 bridge 네트워크 모드를 사용하는 경우 여러 컨테이너가 동일한 IP 주소를 공유할 수 있습니다. 또한 동적 포트 매핑으로 해당 단일 IP 주소에서 컨테이너에 포트 번호가 무작위로 할당됩니다. 이 경우 A 레코드는 더 이상 서비스 검색에 충분하지 않습니다. 또한 SRV 레코드를 사용해야 합니다. 이 유형의 레코드는 IP 주소와 포트 번호를 모두 추적할 수 있지만 애플리케이션을 적절하게 구성해야 합니다. 사용하는 일부 사전 구축된 애플리케이션은 SRV 레코드를 지원하지 않을 수 있습니다.
awsvpc 네트워크 모드의 또 다른 이점은 각 서비스에 대해 고유한 보안 그룹이 보유한다는 점입니다. 해당 서비스와 통신해야 하는 특정 업스트림 서비스의 수신 연결만 허용하도록 이 보안 그룹을 구성할 수 있습니다.
서비스 검색을 사용하는 서비스 간 직접 통신의 주된 단점은 재시도 및 연결 실패 처리를 위해 추가 로직을 구현해야 한다는 점입니다. DNS 레코드에는 캐싱되는 시간을 제어하는 TTL(Time To Live) 기간이 있습니다. 애플리케이션이 최신 버전의 DNS 레코드를 선택할 수 있도록 DNS 레코드를 업데이트하고 캐시가 만료되기까지 어느 정도 시간이 걸립니다. 따라서 애플리케이션이 DNS 레코드를 확인할 때 더 이상 존재하지 않는 다른 컨테이너를 가리킬 수 있습니다. 애플리케이션은 재시도를 처리하고 잘못된 백엔드를 무시할 수 있는 로직을 포함해야 합니다.
내부 로드 밸런서 사용
서비스 간 통신에 대한 또 다른 접근 방식은 내부 로드 밸런서를 사용하는 것입니다. 내부 로드 밸런서는 VPC 내부에만 존재하며 VPC 내부의 서비스에만 액세스할 수 있습니다.
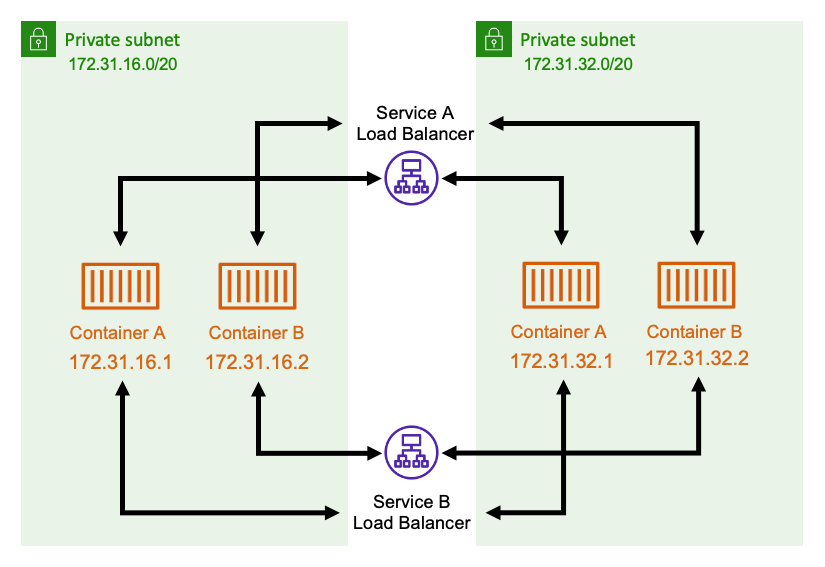
로드 밸런서는 각 서브넷에 중복 리소스를 배포하여 고가용성을 유지합니다. serviceA의 컨테이너가 serviceB의 컨테이너와 통신해야 하는 경우 로드 밸런서에 대한 연결을 엽니다. 그러면 로드 밸런서가 service B의 컨테이너에 대한 연결을 엽니다. 로드 밸런서는 각 서비스 간의 모든 연결을 관리하는 중앙 위치의 역할을 합니다.
serviceB의 컨테이너가 중지되면 로드 밸런서가 해당 컨테이너를 풀에서 제거할 수 있습니다. 또한 로드 밸런서는 풀의 각 다운스트림 대상에 대해 상태 확인을 수행하여 잘못된 대상이 다시 정상 상태가 될 때까지 풀에서 자동으로 제거할 수 있습니다. 애플리케이션은 더 이상 다운스트림 컨테이너가 몇 개 있는지 알 필요가 없습니다. 단순히 로드 밸런서에 대한 연결을 열면 됩니다.
이 접근 방식은 모든 네트워크 모드에서 이점이 있습니다. 로드 밸런서는 awsvpc 네트워크 모드를 사용할 때는 태스크 IP 주소를 추적하고 bridge 네트워크 모드를 사용할 때는 더 복잡한 IP 주소 및 포트 조합을 추적할 수 있습니다. 로드 밸런서는 모든 IP 주소 및 포트 조합 간에 트래픽을 균등하게 분배합니다. 이는 여러 컨테이너가 실제로 동일한 Amazon EC2 인스턴스에서 호스팅되고 포트만 다른 경우에도 마찬가지입니다.
이 접근 방식의 한 가지 단점은 비용입니다. 고가용성을 보장하려면 로드 밸런서의 각 가용 영역에 리소스가 있어야 합니다. 따라서 로드 밸런서에 대한 비용과 로드 밸런서를 통과하는 트래픽 양에 대한 비용을 계산하는 오버헤드 때문에 추가 비용이 발생합니다.
하지만 여러 서비스가 로드 밸런서를 공유하도록 하면 오버헤드 비용을 줄일 수 있습니다. 특히 Application Load Balancer를 사용하는 REST 서비스에 적합합니다. 서로 다른 서비스로 트래픽을 라우팅하는 경로 기반 라우팅 규칙을 생성할 수 있습니다. 예를 들어, /api/user/* 규칙은 user 서비스의 일부인 컨테이너로 라우팅하고 /api/order/* 규칙은 연관된 order 서비스로 라우팅할 수 있습니다. 이 접근 방식을 사용하면 Application Load Balancer 하나에 대해서만 비용을 지불하고 API에 대해 하나의 일관된 URL을 갖게 됩니다. 하지만 백엔드의 다양한 마이크로서비스로 트래픽을 분산시킬 수 있습니다.
