기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Valkey 및 Redis OSS와 함께 다중 AZ를 사용하여 ElastiCache의 가동 중지 시간 최소화
ElastiCache for Valkey 및 Redis OSS가 프라이머리 노드를 교체해야 할 수 있는 여러 인스턴스가 있습니다. 여기에는 특정 유형의 계획된 유지 관리와 가능성이 낮은 프라이머리 노드 또는 가용 영역 장애 이벤트가 포함됩니다.
이러한 교체로 인해 클러스터에 약간의 가동 중지가 발생하지만 다중 AZ를 활성화한 경우 가동 중지 시간이 최소화됩니다. 기본 노드의 역할은 자동으로 읽기 전용 복제본 중 하나로 장애 조치됩니다. ElastiCache가 이 장애 조치를 투명하게 처리하기 때문에 새로운 기본 노드를 생성하고 프로비저닝할 필요가 없습니다. 이 장애 조치 및 복제본 승격을 통해 승격이 완료되는 즉시 새 기본 노드에 작성을 재개할 수 있습니다.
또한 ElastiCache는 승격된 복제본의 DNS(Domain Name Service) 이름을 전파합니다. 이렇게 하면 애플리케이션이 기본 엔드포인트에 쓰는 경우 애플리케이션에서 엔드포인트를 변경할 필요가 없기 때문입니다. 개별 엔드포인트를 읽을 경우 기본으로 승격된 복제본의 읽기 엔드포인트를 새 복제본의 엔드포인트로 변경해야 합니다.
계획된 노드 교체의 경우, 유지 관리 업데이트 또는 셀프 서비스 업데이트로 인해 시작되었으며 다음 사항에 유의하세요.
Valkey 및 Redis OSS 클러스터의 경우 클러스터가 수신 쓰기 요청을 처리하는 동안 계획된 노드 교체가 완료됩니다.
다중 AZ가 활성화되어 5.0.6 이상 엔진에서 실행 중인 Valkey 및 Redis OSS 클러스터 모드 비활성화 클러스터의 경우, 클러스터에서 들어오는 쓰기 요청을 처리하는 중에 계획된 노드 교체가 완료됩니다.
다중 AZ가 활성화되어 4.0.10 이하 엔진에서 실행 중인 Valkey 및 Redis OSS 클러스터 모드 비활성화 클러스터의 경우, DNS 업데이트와 관련하여 짧은 쓰기 중단이 발생할 수 있습니다. 이 중단은 최대 몇 초가 걸릴 수 있습니다. 이 프로세스는 다중 AZ를 활성화하지 않은 경우 발생하는, 새 기본 노드를 다시 생성하고 프로비저닝하는 것보다 훨씬 빠릅니다.
ElastiCache 관리 콘솔 AWS CLI, 또는 ElastiCache API를 사용하여 다중 AZ를 활성화할 수 있습니다.
Valkey 또는 Redis OSS 클러스터(API 및 CLI의 복제 그룹)의 ElastiCache 다중 AZ를 활성화하면 내결함성이 개선됩니다. 특히 클러스터의 읽기/쓰기 기본 클러스터 노드에 접속할 수 없거나 어떤 이유로든 실패하는 경우에 특히 그렇습니다. 다중 AZ는 각 샤드에 둘 이상의 노드가 있는 Valkey 및 Redis OSS 클러스터에서만 지원됩니다.
다중 AZ 활성화
ElastiCache 콘솔 또는 ElastiCache API를 사용하여 클러스터(API 또는 CLI AWS CLI, 복제 그룹)를 생성하거나 수정할 때 다중 AZ를 활성화할 수 ElastiCache.
사용 가능한 읽기 전용 복제본이 하나 이상 있는 Valkey 또는 Redis OSS(클러스터 모드 비활성화됨) 클러스터에서만 다중 AZ를 활성화할 수 있습니다. 읽기 전용 복제본이 없는 클러스터는 고가용성 또는 내결함성을 제공하지 않습니다. 복제하여 클러스터를 생성에 대한 정보는 Valkey 또는 Redis OSS 복제 그룹 생성을 참조하세요. 복제하여 있는 클러스터에 읽기 전용 복제본 추가에 대한 정보는 Valkey 또는 Redis OSS에 대한 읽기 전용 복제본 추가(클러스터 모드 비활성화됨)를 참조하세요.
다중 AZ 활성화(콘솔)
새 Valkey 또는 Redis OSS 클러스터를 생성하거나 기존 클러스터를 복제하여 수정할 때 ElastiCache 콘솔을 사용하여 다중 AZ를 활성화할 수 있습니다.
다중 AZ는 Valkey 또는 Redis OSS(클러스터 모드 활성화됨) 클러스터에서 기본적으로 활성화되어 있습니다.
중요
ElastiCache는 클러스터에 모든 샤드의 기본 노드에서 다른 가용 영역에 있는 복제본이 하나 이상 포함된 경우에만 다중 AZ를 자동으로 활성화합니다.
ElastiCache 콘솔을 사용하여 클러스터를 생성할 때 다중 AZ 활성화
이 프로세스에 대한 자세한 내용은 Valkey(클러스터 모드 비활성화됨) 클러스터 생성(콘솔)을 참조하세요. 복제본이 하나 이상 있어야 하고 다중 AZ를 활성화해야 합니다.
기존 클러스터에서 다중 AZ 활성화(콘솔)
이 프로세스에 대한 자세한 내용은 클러스터 수정 ElastiCache AWS Management Console사용섹션을 참조하세요.
다중 AZ 활성화(AWS CLI)
다음 코드 예제에서는 AWS CLI 를 사용하여 복제 그룹에 대해 다중 AZ를 활성화합니다redis12.
중요
복제 그룹 redis12가 이미 존재해야 하며 사용할 수 있는 읽기 전용 복제본이 하나 이상 있어야 합니다.
Linux, macOS, Unix의 경우:
aws elasticache modify-replication-group \ --replication-group-idredis12\ --automatic-failover-enabled \ --multi-az-enabled \ --apply-immediately
Windows의 경우:
aws elasticache modify-replication-group ^ --replication-group-idredis12^ --automatic-failover-enabled ^ --multi-az-enabled ^ --apply-immediately
이 명령의 JSON 출력은 다음과 같습니다.
{
"ReplicationGroup": {
"Status": "modifying",
"Description": "One shard, two nodes",
"NodeGroups": [
{
"Status": "modifying",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-001.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-002.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-002"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis12.v5r9dc.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ReplicationGroupId": "redis12",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabling",
"MultiAZ": "enabled",
"SnapshotWindow": "07:00-08:00",
"SnapshottingClusterId": "redis12-002",
"MemberClusters": [
"redis12-001",
"redis12-002"
],
"PendingModifiedValues": {}
}
}자세한 내용은 AWS CLI 명령 참조의 다음 항목을 참조하세요.
-
AWS CLI 명령 참조의 modify-replication-group
다중 AZ 활성화(ElastiCache API)
다음 코드 예제에서는 ElastiCache API를 사용하여 복제 그룹 redis12에 대해 다중 AZ를 활성화합니다.
참고
이 예제를 사용하려면 복제 그룹 redis12가 이미 존재해야 하며 사용할 수 있는 읽기 전용 복제본이 하나 이상 있어야 합니다.
https://elasticache.us-west-2.amazonaws.com/ ?Action=ModifyReplicationGroup &ApplyImmediately=true &AutoFailover=true &MultiAZEnabled=true &ReplicationGroupId=redis12 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
자세한 내용은ElastiCache API 참조에서 다음 주제들을 참조하세요.
다중 AZ 응답이 있는 장애 시나리오
다중 AZ를 도입하기 전에 ElastiCache는 장애가 발생한 노드를 재생성하고 재프로비저닝하여 클러스터의 장애가 발생한 노드를 탐지해 교체했습니다. 다중 AZ를 활성화하면 장애가 발생한 기본 노드가 복제 지연이 가장 짧은 복제본으로 장애 조치됩니다. 선택한 복제본이 자동으로 승격되기 때문에 새 기본 노드를 생성하고 프로비저닝하는 것보다 훨씬 빠릅니다. 이 프로세스는 보통 클러스터에 다시 작성하려면 몇 초 정도 소요됩니다.
다중 AZ가 활성화된 경우 ElastiCache가 기본 노드의 상태를 지속적으로 모니터링합니다. 기본 노드에 장애가 발생하면 장애 유형에 따라 다음 작업 중 하나가 수행됩니다.
주제
프라이머리 노드에만 장애가 발생한 경우의 장애 시나리오
기본 노드에 장애가 발생하면 복제 지연 시간이 가장 짧은 읽기 전용 복제본을 기본 노드로 승격시킵니다. 그러면 대체 읽기 전용 복제본이 생성되어 장애가 발생한 기본 노드와 동일한 가용 영역에 프로비저닝됩니다.
기본 노드에만 장애가 발생한 경우 ElastiCache 다중 AZ는 다음 작업을 수행합니다.
장애가 발생한 기본 노드는 오프라인 상태로 전환됩니다.
복제 지연 시간이 가장 짧은 읽기 전용 복제본을 기본으로 승격시킵니다.
승격 프로세스가 완료되는 즉시 쓰기를 재개할 수 있으며 일반적으로 몇 초 정도 소요됩니다. 애플리케이션이 기본 엔드포인트에 쓰는 경우 쓰기 또는 읽기에 대한 엔드포인트를 변경할 필요가 없습니다. ElastiCache가 승격된 복제본의 DNS 이름을 전파합니다.
대체 읽기 전용 복제본을 시작하고 프로비저닝합니다.
장애가 발생한 기본 노드가 있는 가용 영역에서 대체 읽기 전용 복제본을 시작하여 노드 배포를 유지합니다.
복제본이 새 기본 노드와 동기화됩니다.
새 복제본을 사용할 수 있게 되면 다음 효과에 유의하세요.
-
기본 엔드포인트 - 새 기본 노드의 DNS 이름이 기본 엔드포인트로 전파되므로 애플리케이션을 변경할 필요가 없습니다.
-
읽기 엔드포인트 - 리더 엔드포인트는 새 복제본 노드를 가리키도록 자동으로 업데이트됩니다.
클러스터의 엔드포인트를 찾는 방법에 대한 정보는 다음 항목을 참조하세요.
기본 노드 및 일부 읽기 전용 복제본에 장애가 발생한 경우의 장애 시나리오
기본 복제본 및 하나 이상의 복제본에 장애가 발생하면 지연 시간이 가장 짧은 사용 가능한 복제본이 기본 클러스터로 승격됩니다. 또한 기본으로 승격된 복제본 및 장애가 발생한 노드로 새로운 읽기 전용 복제본이 동일 가용 영역에 생성되고 프로비저닝됩니다.
기본 노드와 일부 읽기 전용 복제본에 장애가 발생한 경우 ElastiCache 다중 AZ는 다음 작업을 수행합니다.
장애가 발생한 기본 노드 및 읽기 전용 복제본이 오프라인 상태로 전환됩니다.
복제 지연 시간이 가장 짧은 사용 가능한 복제본을 기본 노드로 승격시킵니다.
승격 프로세스가 완료되는 즉시 쓰기를 재개할 수 있으며 일반적으로 몇 초 정도 소요됩니다. 애플리케이션이 기본 엔드포인트에 쓰는 경우 쓰기에 대한 엔드포인트를 변경할 필요가 없습니다. ElastiCache가 승격된 복제본의 DNS 이름을 전파합니다.
교체용 복제본을 생성하고 프로비저닝합니다.
장애가 발생한 노드의 가용 영역에서 교체용 복제본을 생성하여 노드 배포를 유지합니다.
모든 클러스터가 새 기본 노드와 동기화됩니다.
새 노드를 사용할 수 있게 되면 애플리케이션을 다음과 같이 변경합니다.
-
기본 엔드포인트 - 애플리케이션을 변경하지 마십시오. 새 기본 노드의 DNS 이름이 기본 엔드포인트로 전파됩니다.
-
읽기 엔드포인트 - 읽기 엔드포인트는 새 복제본 노드를 가리키도록 자동으로 업데이트됩니다.
복제 그룹의 엔드포인트를 찾는 방법에 대한 정보는 다음 항목을 참조하세요.
전체 클러스터에 장애가 발생한 경우의 장애 시나리오
모든 것에 장애가 발생하면 모든 노드를 동일한 가용 영역에 원본 노드로 재생성하고 프로비저닝합니다.
이 시나리오에서는 클러스터의 모든 노드에 장애가 발생하여 클러스터의 모든 데이터가 손실됩니다. 이는 거의 발생하지 않습니다.
전체 클러스터에 장애가 발생한 경우 ElastiCache 다중 AZ는 다음 작업을 수행합니다.
장애가 발생한 기본 노드 및 읽기 전용 복제본이 오프라인 상태로 전환됩니다.
대체 기본 노드를 생성하고 프로비저닝합니다.
교체용 복제본을 생성하고 프로비저닝합니다.
장애가 발생한 노드의 가용 영역에서 대체를 생성하여 노드 배포를 유지합니다.
전체 클러스터에 장애가 발생했으므로 데이터가 손실되고 모든 새 노드가 콜드를 시작합니다.
각각의 교체 노드에는 교체하는 노드와 동일한 엔드포인트가 있기 때문에 애플리케이션에서 엔드포인트를 변경할 필요가 없습니다.
복제 그룹의 엔드포인트를 찾는 방법에 대한 정보는 다음 항목을 참조하세요.
내결함성 수준을 높이려면 다른 가용 영역에 기본 노드 및 읽기 전용 복제본을 생성하는 것이 좋습니다.
자동 장애 조치 테스트
자동 장애 조치를 활성화한 후에는 ElastiCache 콘솔, AWS CLI및 ElastiCache API를 사용하여 이를 테스트할 수 있습니다.
테스트 시 다음 사항에 유의하세요.
-
이 작업을 사용하여 24시간 동안 최대 15개의 샤드(ElastiCache API 및 에서는 노드 그룹이라고 함 AWS CLI)에서 자동 장애 조치를 테스트할 수 있습니다.
-
다른 클러스터(API 및 CLI의 복제 그룹이라고 함)에 있는 샤드에서 이 작업을 동시에 호출할 수 있습니다.
-
경우에 따라 동일한 Valkey 또는 Redis OSS(클러스터 모드 활성화됨) 복제 그룹의 서로 다른 샤드에서 이 작업을 여러 번 호출할 수 있습니다. 이러한 경우 후속 호출이 이루어지기 전에 첫 번째 노드 교체가 완료되어야 합니다.
-
노드 교체가 완료되었는지 확인하려면 Amazon ElastiCache 콘솔 AWS CLI, 또는 ElastiCache API를 사용하여 이벤트를 확인합니다. 발생 순서대로 나열되어 있는 아래 목록에서 다음과 같은 자동 장애 조치 관련 이벤트를 찾습니다.
-
복제 그룹 메시지:
Test Failover API called for node group <node-group-id> -
캐시 클러스터 메시지:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
복제 그룹 메시지:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
캐시 클러스터 메시지:
Recovering cache nodes <node-id> -
캐시 클러스터 메시지:
Finished recovery for cache nodes <node-id>
자세한 내용은 다음 자료를 참조하세요.
-
ElastiCache 사용 설명서의 ElastiCache 이벤트 보기
-
ElastiCache API 참조의 DescribeEvents
-
AWS CLI 명령 참조의 describe-events
-
이 API는 ElastiCache 장애 조치의 경우 애플리케이션의 동작을 테스트하도록 설계되었습니다. 클러스터 문제를 해결하기 위해 장애 조치를 시작하는 운영 도구로 설계되지 않았습니다. 또한 대규모 운영 이벤트와 같은 특정 조건에서이 API를 차단할 AWS 수 있습니다.
주제
를 사용하여 자동 장애 조치 테스트 AWS Management Console
다음 절차에 따라 콘솔로 자동 장애 조치를 테스트합니다.
자동 장애 조치를 테스트하려면
-
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/elasticache/
ElastiCache 콘솔을 엽니다. -
탐색 창에서 Valkey 또는 Redis OSS를 선택합니다.
-
클러스터 목록에서 테스트할 클러스터 왼쪽에 있는 확인란을 선택합니다. 이 클러스터에는 읽기 전용 복제본 노드가 하나 이상 있어야 합니다.
-
[Details] 영역에서 이 클러스터가 다중 AZ 활성 상태인지 확인합니다. 해당 클러스터가 다중 AZ 활성 상태가 아닌 경우 다른 클러스터를 선택하거나 다중 AZ를 활성화하도록 이 클러스터를 수정합니다. 자세한 내용은 ElastiCache AWS Management Console사용 단원을 참조하십시오.
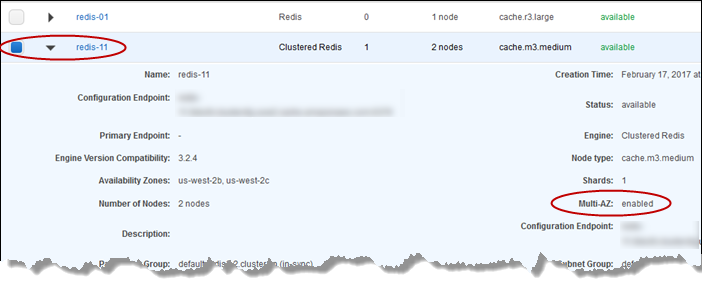
Valkey 또는 Redis OSS(클러스터 모드 비활성화됨)의 경우 클러스터 이름을 선택합니다.
Valkey 또는 Redis OSS(클러스터 모드 활성화됨)의 경우 다음을 수행합니다.
-
클러스터의 이름을 선택합니다.
-
[Shards] 페이지에서 장애 조치를 테스트할 샤드(API 및 CLI의 노드 그룹이라고 함)에 대해 샤드 이름을 선택합니다.
-
-
노드 페이지에서 [Failover Primary]를 선택합니다.
-
기본 노드를 장애 조치하려면 [Continue]를 선택하고 작업을 취소하여 기본 노드를 장애 조치하지 않으려면 [Cancel]을 선택합니다.
장애 조치 프로세스 중에 콘솔은 노드 상태를 계속해서 사용 가능으로 표시합니다. 장애 조치 테스트 진행률을 추적하려면 콘솔 탐색 창에서 [Events]를 선택합니다. [Events] 탭에서 장애 조치의 시작(
Test Failover API called) 및 완료(Recovery completed)를 나타내는 이벤트를 주시합니다.
를 사용하여 자동 장애 조치 테스트 AWS CLI
AWS CLI 작업을 사용하여 다중 AZ 지원 클러스터에서 자동 장애 조치를 테스트할 수 있습니다test-failover.
파라미터
-
--replication-group-id- 필수입니다. 테스트할 복제 그룹(콘솔, 클러스터)입니다. -
--node-group-id- 필수입니다. 자동 장애 조치를 테스트할 노드 그룹의 이름입니다. 24시간 동안 최대 15개의 노드 그룹을 테스트할 수 있습니다.
다음 예제에서는 AWS CLI 를 사용하여 Valkey 또는 Redis OSS(클러스터 모드 활성화됨) 클러스터 redis00-0003의 노드 그룹에서 자동 장애 조치를 테스트합니다redis00.
예 자동 장애 조치 테스트
Linux, macOS, Unix의 경우:
aws elasticache test-failover \ --replication-group-idredis00\ --node-group-idredis00-0003
Windows의 경우:
aws elasticache test-failover ^ --replication-group-idredis00^ --node-group-idredis00-0003
이전 명령의 출력은 다음과 같습니다.
{
"ReplicationGroup": {
"Status": "available",
"Description": "1 shard, 3 nodes (1 + 2 replicas)",
"NodeGroups": [
{
"Status": "available",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2c",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-001.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-002.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-002"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-003.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-003"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis1x3.7ekv3t.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ClusterEnabled": false,
"ReplicationGroupId": "redis1x3",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabled",
"MultiAZ": "enabled",
"SnapshotWindow": "11:30-12:30",
"SnapshottingClusterId": "redis1x3-002",
"MemberClusters": [
"redis1x3-001",
"redis1x3-002",
"redis1x3-003"
],
"CacheNodeType": "cache.m3.medium",
"DataTiering": "disabled",
"PendingModifiedValues": {}
}
}장애 조치 진행 상황을 추적하려면 작업을 사용합니다 AWS CLI describe-events.
자세한 내용은 다음 자료를 참조하세요.
-
AWS CLI 명령 참조의 test-failover
-
AWS CLI 명령 참조의 describe-events
ElastiCache API를 사용하여 자동 장애 조치 테스트
ElastiCache API 작업 TestFailover를 사용하여 다중 AZ가 활성화된 모든 클러스터에서 자동 장애 조치를 테스트할 수 있습니다.
파라미터
-
ReplicationGroupId- 필수입니다. 테스트할 복제 그룹(콘솔, 클러스터)입니다. -
NodeGroupId- 필수입니다. 자동 장애 조치를 테스트할 노드 그룹의 이름입니다. 24시간 동안 최대 15개의 노드 그룹을 테스트할 수 있습니다.
다음 예제에서는 복제 그룹(콘솔, 클러스터에서) redis00의 노드 그룹 redis00-0003에 대한 자동 장애 조치를 테스트합니다.
예 자동 장애 조치 테스트
https://elasticache.us-west-2.amazonaws.com/ ?Action=TestFailover &NodeGroupId=redis00-0003 &ReplicationGroupId=redis00 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
장애 조치 진행률을 추적하려면 ElastiCache DescribeEvents API 작업을 사용하세요.
자세한 내용은 다음 자료를 참조하세요.
-
ElastiCache API 참조의 TestFailover
-
ElastiCache API 참조의 DescribeEvents
다중 AZ에 대한 제한 사항
다중 AZ에 대한 다음 제한 사항에 유의하세요.
-
다중 AZ는 Valkey 및 Redis OSS 버전 2.8.6 이상에서 지원됩니다.
-
다중 AZ는 T1 노드 유형에서는 지원되지 않습니다.
-
Valkey 및 Redis OSS 복제는 비동기식입니다. 따라서 기본 노드를 복제본으로 장애 조치하면 복제 지연으로 인해 소량의 데이터가 손실될 수 있습니다.
기본으로 승격할 복제본을 선택할 때 ElastiCache는 최소 복제 지연 시간으로 복제본을 선택합니다. 즉, 가장 최신 복제본을 선택합니다. 이로써 손실 데이터 양을 최소화할 수 있습니다. 복제 지연 시간이 가장 짧은 복제본은 실패한 기본 노드와 같은 가용 영역에 있을 수도 있고 다른 가용 영역에 있을 수도 있습니다.
-
클러스터 모드가 비활성화된 Valkey 또는 Redis OSS 클러스터에서 읽기 전용 복제본을 기본 복제본으로 수동으로 승격하는 경우 다중 AZ 및 자동 장애 조치가 비활성화된 경우에만 이 작업을 수행할 수 있습니다. 읽기 전용 복제본을 기본으로 승격하려면 다음 단계를 따릅니다.
-
클러스터에서 다중 AZ를 비활성화합니다.
-
클러스터에서 자동 장애 조치를 비활성화합니다. 이 작업은 콘솔을 통해 복제 그룹의 자동 장애 조치 확인란을 선택 취소하여 수행할 수 있습니다.
ModifyReplicationGroup작업을 호출할false때AutomaticFailoverEnabled속성을 로 설정 AWS CLI 하여를 사용하여이 작업을 수행할 수도 있습니다. -
읽기 전용 복제본을 기본으로 승격합니다.
-
다중 AZ를 다시 활성화합니다.
-
-
ElastiCache for Redis OSS 다중 AZ 및 추가 전용 파일(AOF)은 상호 배타적입니다. 하나를 활성화하면 다른 하나를 활성화할 수 없습니다.
-
노드 장애는 드물지만 전체 가용 영역에 장애가 발생하는 경우로 인해 발생할 수 있습니다. 이 경우 장애가 발생한 기본 서버를 대체하는 복제본은 가용 영역이 백업된 경우에만 생성됩니다. 예를 들어, AZ-a에 기본 노드가 있고 AZ-b 및 AZ-c에 복제본이 있는 복제 그룹을 가정해 보겠습니다. 기본 노드에 문제가 발생하면 복제 지연 시간이 가장 짧은 사용 가능한 복제본을 기본 노드로 승격시킵니다. 그런 다음 ElastiCache는 AZ-a가 백업되어 사용할 수 있는 경우에만 AZ-a(장애가 발생한 기본이 있는 위치)에 새 복제본을 생성합니다.
-
고객이 실행한 기본 재부팅은 자동 장애 조치를 트리거하지 않습니다. 다른 재부팅 및 장애는 자동 장애 조치를 트리거합니다.
-
기본을 재부팅하는 경우 온라인 상태가 되면 데이터가 지워집니다. 읽기 전용 복제본은 기본 클러스터가 지워진 것을 확인하면 데이터 복제본을 지우기 때문에 데이터가 손실됩니다.
-
읽기 전용 복제본이 승격된 후 다른 복제본은 새 기본 복제본과 동기화됩니다. 초기 동기화 후 복제본의 콘텐츠가 삭제되고 새 기본 복제본의 데이터가 동기화됩니다. 이 동기화 프로세스로 인해 복제본에 액세스할 수 없는 잠깐 중단이 발생합니다. 또한 이 동기화 프로세스로 인해 복제본과 동기화되는 동안 기본에 임시 로드가 증가합니다. 이 동작은 Valkey 및 Redis OSS의 기본 동작이며 ElastiCache 다중 AZ에 고유하지 않습니다. 이 동작에 대한 자세한 내용은 Valkey 웹 사이트의 복제
를 참조하세요.
중요
Valkey 7.2.6 이상 또는 Redis OSS 버전 2.8.22 이상에서는 외부 복제본을 만들 수 없습니다.
2.8.22 이전의 Redis OSS 버전에서는 다중 AZ가 활성화된 ElastiCache 클러스터에 외부 복제본을 연결하지 않는 것이 좋습니다. 이 지원되지 않는 구성으로 ElastiCache가 장애 조치 및 복구를 제대로 수행하지 못하는 문제를 유발할 수 있습니다. 외부 복제본을 ElastiCache 클러스터에 연결하려면 연결하기 전에 다중 AZ가 활성화되지 않았는지 확인합니다.
