Aurora PostgreSQL의 메모리 파라미터 조정
Amazon Aurora PostgreSQL에서는 다양한 처리 작업에 사용되는 메모리 양을 제어하는 여러 파라미터를 사용할 수 있습니다. 작업에서 지정된 파라미터에 설정된 양보다 많은 메모리를 사용하는 경우 Aurora PostgreSQLdms 다른 리소스를 사용하여 처리합니다(예: 디스크에 쓰기). 이로 인해 Aurora PostgreSQL DB 클러스터가 느려지거나 중단될 수 있으며 메모리 부족 오류가 발생할 수 있습니다.
각 메모리 파라미터의 기본 설정은 일반적으로 의도한 처리 작업을 취급할 수 있습니다. 그러나 Aurora PostgreSQL DB 클러스터의 의 메모리 관련 파라미터를 조정할 수도 있습니다. 이렇게 조정하여 특정 워크로드를 처리하기에 충분한 메모리가 할당되도록 합니다.
다음에서 메모리 관리를 제어하는 파라미터에 관한 정보를 확인할 수 있습니다. 메모리 사용률을 평가하는 방법도 알아볼 수 있습니다.
파라미터 값 확인 및 설정
메모리를 관리하고 Aurora PostgreSQL DB 클러스터의 메모리 사용량을 평가하기 위해 설정할 수 있는 파라미터는 다음과 같습니다.
work_mem- Aurora PostgreSQL DB 클러스터가 임시 디스크 파일에 쓰기 전에 내부 정렬 작업 및 해시 테이블에 사용하는 메모리 양을 지정합니다.log_temp_files- 임시 파일 생성, 파일 이름 및 크기를 기록합니다. 이 파라미터가 켜져 있으면 생성되는 각 임시 파일에 대해 로그 항목이 저장됩니다. 이 기능을 켜면 Aurora PostgreSQL DB 클러스터가 디스크에 써야 하는 빈도를 확인할 수 있습니다. 과도한 로깅을 방지하려면 Aurora PostgreSQL DB 클러스터의 임시 파일 생성에 대한 정보를 수집한 후 다시 끄세요.logical_decoding_work_mem– 디스크로 유출되기 전에 각 내부 재정렬 버퍼에서 사용할 메모리 양(KB)을 지정합니다. 이 메모리는 복제본을 만드는 프로세스인 논리적 디코딩에 사용됩니다. 이는 미리 쓰기 로그(WAL) 파일의 데이터를 대상에 필요한 논리적 스트리밍 출력으로 변환하여 수행됩니다.이 파라미터의 값은 각 복제 연결에 지정된 크기의 단일 버퍼를 생성합니다. 기본값은 65,536KB입니다. 이 버퍼가 채워지면 초과분은 디스크에 파일로 기록됩니다. 디스크 활동을 최소화하기 위해 이 파라미터의 값을
work_mem보다 훨씬 높게 설정할 수 있습니다.
이러한 파라미터는 모두 동적 파라미터이므로 현재 세션에 맞게 변경할 수 있습니다. 이렇게 하려면 다음과 같이 psql과 SET 문을 사용하여 Aurora PostgreSQL DB 클러스터 에 연결합니다.
SET parameter_name TO parameter_value;세션 설정은 세션 기간 동안만 지속됩니다. 세션이 끝나면 파라미터는 DB 클러스터 파라미터 그룹의 설정으로 되돌아갑니다. 파라미터를 변경하려면 먼저 다음과 같이 pg_settings 테이블을 쿼리하여 현재 값을 확인해야 합니다.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
예를 들어 work_mem 파라미터의 값을 찾으려면 Aurora PostgreSQL DB 클러스터의 라이터 인스턴스에 연결하고 다음 쿼리를 실행합니다.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
파라미터 설정이 유지되도록 변경하려면 사용자 지정 DB 클러스터 파라미터 그룹을 사용해야 합니다. SET 문을 사용하여 이러한 파라미터에 대해 다른 값으로 Aurora PostgreSQL DB 클러스터 를 실행한 후 사용자 지정 파라미터 그룹을 생성하고 Aurora PostgreSQL DB 클러스터에 적용할 수 있습니다. 자세한 내용은 Amazon Aurora의 파라미터 그룹 단원을 참조하세요.
작업 메모리 파라미터 이해
작업 메모리 파라미터(work_mem)는 Aurora PostgreSQL이 복잡한 쿼리를 처리하는 데 사용할 수 있는 최대 메모리 양을 지정합니다. 복잡한 쿼리에는 정렬 또는 그룹화 작업, 즉 다음 절을 사용하는 쿼리가 포함됩니다.
ORDER BY
DISTINCT
GROUP BY
JOIN(MERGE 및 HASH)
쿼리 플래너는 Aurora PostgreSQL DB 클러스터가 작업 메모리를 사용하는 방식에 간접적으로 영향을 미칩니다. 쿼리 플래너는 SQL 문을 처리하기 위한 실행 계획을 생성합니다. 주어진 계획을 따르면 복잡한 쿼리를 병렬로 실행할 수 있는 여러 작업 단위로 분할할 수 있습니다. 가능한 경우 Aurora PostgreSQL은 각 병렬 프로세스에서 디스크에 쓰기 전에 각 세션에 대해 work_mem 파라미터에 지정된 메모리 양을 사용합니다.
여러 데이터베이스 사용자가 동시에 여러 작업을 실행하고 여러 작업 단위를 병렬로 생성하면 Aurora PostgreSQL DB 클러스터에 할당된 작업 메모리가 소진될 수 있습니다. 이로 인해 임시 파일 생성 및 디스크 I/O가 과도하게 발생하거나 더 심각한 경우 메모리 부족 오류가 발생할 수 있습니다.
임시 파일 사용 확인
쿼리 처리에 필요한 메모리가 work_mem 파라미터에 지정된 값을 초과할 때마다 작업 데이터가 임시 파일의 디스크에 오프로드됩니다. log_temp_files 파라미터를 켜면 발생하는 빈도를 파악할 수 있습니다. 기본적으로 이 파라미터는 해제(-1로 설정됨)되어 있습니다. 모든 임시 파일 정보를 캡처하려면 이 파라미터를 0으로 설정합니다. log_temp_files를 다른 양의 정수로 설정하여 해당 데이터 양(KB) 이상인 파일의 임시 파일 정보를 캡처하세요. 다음 이미지에서는 AWS Management Console의 예를 볼 수 있습니다.
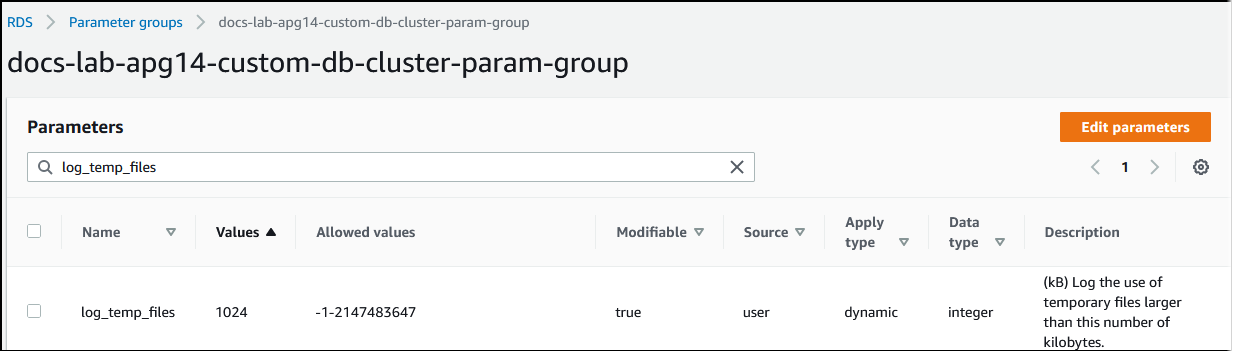
임시 파일 로깅을 구성한 후 자체 워크로드로 테스트하여 작업 메모리 설정이 충분한지 확인할 수 있습니다. PostgreSQL 커뮤니티의 간단한 벤치마킹 애플리케이션인 pgbench를 사용하여 워크로드를 시뮬레이션할 수도 있습니다.
다음 예제는 테스트를 실행하는 데 필요한 테이블과 행을 생성하여 pgbench를 초기화합니다(-i). 이 예에서 배율 인수(-s 50)는 labdb 데이터베이스의 pgbench_branches 테이블에 50개 행, pgbench_tellers에 500개 행, pgbench_accounts 테이블에 5,000,000개 행을 생성합니다.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)환경을 초기화한 후 특정 시간(-T) 동안 특정 클라이언트 수(-c)에 대해 벤치마크를 실행할 수 있습니다. 또한 이 예에서는 -d 옵션을 사용하여 Aurora PostgreSQL DB 클러스터에서 트랜잭션을 처리할 때 디버깅 정보를 출력합니다.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
pgbench
psql metacommand 명령(\d)을 사용하여 pgbench에서 생성한 테이블, 뷰 및 인덱스와 같은 관계를 나열할 수 있습니다.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
출력에 표시된 대로 pgbench_accounts 테이블은 aid 열에서 인덱싱됩니다. 이 다음 쿼리가 작업 메모리를 사용하도록 하려면 다음 예에 표시된 것과 같이 인덱싱되지 않은 열을 쿼리합니다.
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
로그에서 임시 파일을 확인합니다. 이렇게 하려면 AWS Management Console을 열고 Aurora PostgreSQL DB 클러스터 인스턴스를 선택한 다음 로그 및 이벤트 탭을 선택합니다. 로그는 콘솔에서 확인하거나 다운로드하여 추가 분석을 수행할 수 있습니다. 다음 이미지에 표시된 것처럼 쿼리를 처리하는 데 필요한 임시 파일의 크기는 work_mem 파라미터에 지정된 양을 늘려야 함을 나타냅니다.

운영상의 필요에 따라 개인 및 그룹에 대해 이 파라미터를 다르게 구성할 수 있습니다. 예를 들어 dev_team이라는 역할에 대해 work_mem 파라미터를 8GB로 설정할 수 있습니다.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
work_mem에 대한 이 설정을 사용하면 dev_team 역할의 구성원인 역할에 최대 8GB의 작업 메모리가 할당됩니다.
응답 시간 단축을 위한 인덱스 사용
쿼리가 결과를 반환하는 데 너무 오래 걸리는 경우 인덱스가 예상대로 사용되고 있는지 확인할 수 있습니다. 먼저 다음과 같이 psql 메타 명령인 \timing을 켭니다.
postgres=>\timing on
타이밍을 켠 후 간단한 SELECT 문을 사용합니다.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
출력에 표시된 대로 이 쿼리를 완료하는 데 3초가 조금 넘게 걸렸습니다. 응답 시간을 개선하려면 다음과 같이 pgbench_accounts에 인덱스를 생성합니다.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
쿼리를 다시 실행하면 응답 시간이 더 빨라지는 것을 확인할 수 있습니다. 이 예시에서는 쿼리가 약 0.5초 만에 5배 더 빠르게 완료되었습니다.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
논리적 디코딩을 위한 작업 메모리 조정
논리적 복제는 PostgreSQL 버전 10에 도입된 이후 모든 버전의 Aurora PostgreSQL 에서 사용할 수 있습니다. 논리적 복제를 구성할 때 논리적 디코딩 프로세스가 디코딩 및 스트리밍 프로세스에 사용할 수 있는 메모리 양을 지정하도록 logical_decoding_work_mem 파라미터를 설정할 수도 있습니다.
논리적 디코딩 중에 미리 쓰기 로그(WAL) 레코드는 SQL 문으로 변환된 다음 논리적 복제나 다른 작업을 위해 다른 대상으로 전송됩니다. 트랜잭션이 WAL에 작성된 다음 변환되면 전체 트랜잭션이 logical_decoding_work_mem에 지정된 값에 맞아야 합니다. 기본적으로 이 파라미터는 65,536MB로 설정됩니다. 모든 오버플로우는 디스크에 기록됩니다. 따라서 디스크에서 다시 읽어야 대상으로 보낼 수 있기 때문에 전체 프로세스 속도가 느려집니다.
다음 예와 같이 aurora_stat_file 함수를 사용하여 특정 시점에서 현재 워크로드의 트랜잭션 오버플로 양을 평가할 수 있습니다.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
이 쿼리는 쿼리가 호출될 때 Aurora PostgreSQL DB 클러스터에 있는 유출 파일의 수와 크기를 반환합니다. 더 오래 실행되는 워크로드는 아직 디스크에 유출 파일이 없을 수 있습니다. 장기 실행 워크로드를 프로파일링하려면 워크로드가 실행될 때 유출 파일 정보를 캡처하는 테이블을 생성하는 것이 좋습니다. 다음과 같이 테이블을 만들 수 있습니다.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
논리적 복제 중에 스필 파일이 사용되는 방식을 보려면 게시자와 구독자를 설정한 다음 단순 복제를 시작합니다. 자세한 내용은 Aurora PostgreSQL DB 클러스터의 논리적 복제 설정 단원을 참조하십시오. 복제가 진행되면 다음과 같이 aurora_stat_file() 유출 파일 함수에서 결과 집합을 캡처하는 작업을 만들 수 있습니다.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
다음 psql 명령을 사용하여 초당 한 번씩 작업을 실행합니다.
\watch 0.5
작업이 실행 중일 때 다른 psql 세션에서 라이터 인스턴스에 연결합니다. 다음 일련의 명령문을 사용하여 메모리 구성을 초과하는 Aurora PostgreSQL이 유출 파일을 생성하도록 하는 워크로드를 실행하세요.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
이러한 명령문은 완료하는 데 몇 분 정도 걸립니다. 완료되면 Ctrl 키와 C 키를 함께 눌러 모니터링 기능을 중지합니다. 그런 다음 아래 명령을 사용하여 Aurora PostgreSQL DB 클러스터의 유출 파일 사용에 대한 정보를 보관하는 테이블을 생성합니다.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
출력은 예를 실행하면 611MB의 메모리를 사용하는 유출 파일 5개가 생성되었음을 보여줍니다. 디스크에 쓰지 않으려면 logical_decoding_work_mem 파라미터는 다음으로 높은 메모리 크기인 1024로 설정하는 것이 좋습니다.
