io/aurora_redo_log_flush
io/aurora_redo_log_flush 이벤트는 세션이 Amazon Aurora 스토리지에 영구 데이터를 쓸 때 발생합니다.
지원되는 엔진 버전
이 대기 이벤트 정보는 다음 엔진 버전에서 지원됩니다.
-
Aurora MySQL 버전 2
컨텍스트
io/aurora_redo_log_flush 이벤트는 Aurora MySQL에서 쓰기 입력/출력(I/O) 작업을 위한 것입니다.
참고
Aurora MySQL 버전 3에서는 이 대기 이벤트의 이름이 io/redo_log_flush입니다.
대기 증가의 가능한 원인
데이터 지속성을 위해 커밋에는 안정적인 스토리지에 대한 내구성 있는 쓰기가 필요합니다. 데이터베이스가 너무 많은 커밋을 수행하는 경우 쓰기 I/O 작업에 대기 이벤트인 io/aurora_redo_log_flush 대기 이벤트가 있습니다.
다음 예에서는 db.r5.xlarge DB 인스턴스 클래스를 사용하여 50,000개의 레코드를 Aurora MySQL DB 클러스터에 삽입합니다.
-
첫 번째 예에서 각 세션은 행별로 10,000개의 레코드를 삽입합니다. 기본적으로 데이터 조작 언어(DML) 명령이 트랜잭션 내에 있지 않으면 Aurora MySQL은 암시적 커밋을 사용합니다. 자동 커밋이 활성화됩니다. 즉, 각 행 삽입마다 커밋이 있습니다. 성능 개선 도우미는 연결이 대부분의 시간을
io/aurora_redo_log_flush대기 이벤트에서 기다리면서 소비한다는 것을 보여줍니다.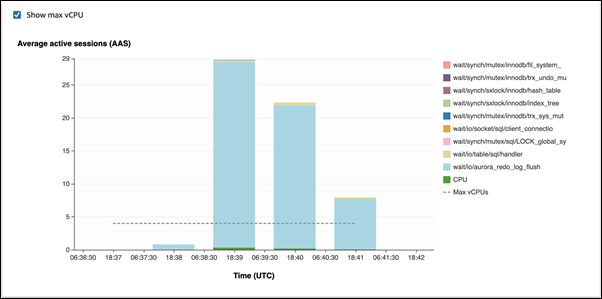
이 이벤트는 사용되는 간단한 삽입 문 때문에 발생합니다.
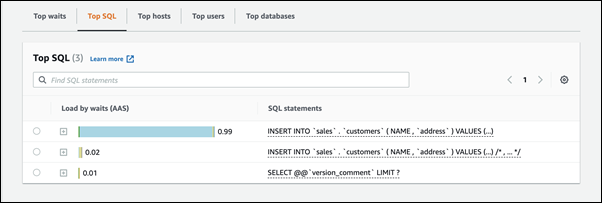
50,000개의 레코드를 삽입하는 데 3.5분이 걸립니다.
-
두 번째 예에서는 삽입이 1,000개의 배치로 만들어집니다. 즉, 각 연결은 10,000개가 아닌 10개의 커밋을 수행합니다. 성능 개선 도우미에 따르면 연결은 대부분의 시간을
io/aurora_redo_log_flush대기 이벤트에서 소비하지 않습니다.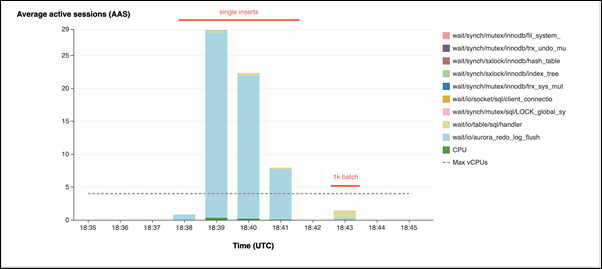
50,000개의 레코드를 삽입하는 데 4초가 걸립니다.
작업
대기 이벤트의 원인에 따라 다른 작업을 권장합니다.
문제가 있는 세션 및 쿼리 식별
DB 인스턴스에 병목 현상이 발생하는 경우 첫 번째 작업은 이를 유발하는 세션과 쿼리를 찾는 것입니다. 유용한 AWS 데이터베이스 블로그 게시물은 성능 개선 도우미를 통해 Amazon Aurora MySQL 워크로드 분석
병목 현상을 일으키는 세션 및 쿼리를 식별하려면
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. -
탐색 창에서 Performance Insights(성능 개선 도우미)를 선택합니다.
-
DB 인스턴스를 선택합니다.
-
데이터베이스 로드(Database load)에서 대기별 조각(Slice by wait)을 선택합니다.
-
페이지 하단에서 상위 SQL(Top SQL)을 선택합니다.
목록 맨 위에 있는 쿼리로 인해 데이터베이스에 대한 로드가 가장 높습니다.
쓰기 작업 그룹화
다음 예에서는 io/aurora_redo_log_flush 대기 이벤트를 트리거합니다. (자동 커밋이 활성화됩니다.)
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
io/aurora_redo_log_flush 대기 이벤트에서 대기하는 시간을 줄이려면 쓰기 작업을 논리적으로 단일 커밋으로 그룹화하여 스토리지에 대한 지속적인 호출을 줄입니다.
자동 커밋 해제
다음 예와 같이 트랜잭션 내에 없는 대규모 변경을 수행하기 전에 자동 커밋을 해제합니다.
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
트랜잭션 사용
다음 예와 같이 트랜잭션을 사용할 수 있습니다.
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
배치 사용
다음 예와 같이 배치를 변경할 수 있습니다. 그러나 너무 큰 배치를 사용하면 특히 읽기 전용 복제본이나 특정 시점으로 복구(PITR)를 수행할 때 성능 문제가 발생할 수 있습니다.
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;
