SQL Server 데이터베이스를 Babelfish for Aurora PostgreSQL로 마이그레이션
Babelfish for Aurora PostgreSQL을 사용하여 SQL Server 데이터베이스에서 Amazon Aurora PostgreSQL DB 클러스터로 마이그레이션할 수 있습니다. 마이그레이션하기 전에 단일 데이터베이스 또는 여러 데이터베이스에서 Babelfish 사용 섹션을 검토하세요.
주제
마이그레이션 프로세스 개요
다음 요약에는 SQL Server 애플리케이션을 성공적으로 마이그레이션하고 Babelfish와 함께 사용하는 데 필요한 단계가 나열되어 있습니다. 내보내기 및 가져오기 프로세스에 사용할 수 있는 도구에 대한 자세한 내용과 심층적인 정보는 SQL Server에서 Babelfish로 마이그레이션하기 위한 가져오기/내보내기 도구 섹션을 참조하세요. 데이터를 로드하려면 대상 엔드포인트로 Aurora PostgreSQL DB 클러스터가 있는 AWS DMS를 사용하는 것이 좋습니다.
-
Babelfish를 설정한 새로운 Aurora PostgreSQL DB 클러스터를 생성합니다. 자세한 방법은 Babelfish for Aurora PostgreSQL DB 클러스터 생성(을)를 참조하세요.
SQL Server 데이터베이스에서 내보낸 다양한 SQL 아티팩트를 가져오려면 sqlcmd
와 같은 SQL Server 도구를 사용하여 Babelfish 클러스터에 연결하면 됩니다. 자세한 내용은 SQL Server 클라이언트 도구를 사용하여 DB 클러스터에 연결 단원을 참조하십시오. -
마이그레이션할 SQL Server 데이터베이스에서 데이터 정의 언어(DDL)를 내보냅니다. DDL은 사용자 데이터(예: 테이블, 인덱스 및 뷰)와 사용자가 작성한 데이터베이스 코드(예: 저장 프로시저, 사용자 정의 함수 및 트리거)를 포함하는 데이터베이스 객체를 설명하는 SQL 코드입니다.
자세한 내용은 SQL Server Management Studio(SSMS)를 사용하여 Babelfish로 마이그레이션 단원을 참조하십시오.
-
Babelfish가 SQL Server에서 실행 중인 애플리케이션을 효과적으로 지원할 수 있도록 평가 도구를 실행하여 변경해야 할 내용 범위를 평가합니다. 자세한 내용은 SQL Server 및 Babelfish 간의 차이점 평가 및 처리 단원을 참조하십시오.
-
AWS DMS 대상 엔드포인트 제한 사항을 검토하고 필요에 따라 DDL 스크립트를 업데이트합니다. 자세한 내용은 Aurora PostgreSQL을 대상으로 사용에서 Babelfish 테이블과 함께 PostgreSQL 대상 엔드포인트 사용 시 제한 사항을 참조하세요.
-
새 Babelfish DB 클러스터에서, 지정한 T-SQL 데이터베이스 내에서 DDL을 실행하여 프라이머리 키 제약 조건이 있는 스키마, 사용자 정의 데이터 유형과 테이블만 생성합니다.
-
AWS DMS를 사용하여 SQL Server의 데이터를 Babelfish 테이블로 마이그레이션합니다. SQL Server Change Data Capture 또는 SQL Replication를 사용한 연속 복제의 경우, Babelfish 대신 Aurora PostgreSQL을 엔드포인트로 사용합니다. 방법은 AWS Database Migration Service의 대상으로 Babelfish for Aurora PostgreSQL 사용을 참조하십시오.
-
데이터 로드가 완료되면, Babelfish 클러스터의 애플리케이션을 지원하는 나머지 T-SQL 객체를 모두 생성합니다.
-
SQL Server 데이터베이스 대신 Babelfish 엔드포인트에 연결하도록 클라이언트 애플리케이션을 재구성합니다. 자세한 내용은 Babelfish DB 클러스터에 연결 단원을 참조하십시오.
-
필요한 경우 애플리케이션을 수정하여 다시 테스트합니다. 자세한 내용은 Babelfish for Aurora PostgreSQL과 SQL Server의 차이점 단원을 참조하십시오.
여전히 클라이언트 측 SQL 쿼리를 평가해야 합니다. SQL Server 인스턴스에서 생성된 스키마는 서버 측 SQL 코드만 변환합니다. 다음 단계를 수행하는 것이 좋습니다.
-
TSQL_Replay 미리 정의된 템플릿과 함께 SQL Server 프로파일러를 사용하여 클라이언트측 쿼리를 캡처합니다. 이 템플릿은 반복적인 튜닝 및 테스트를 위해 재생할 수 있는 T-SQL 문 정보를 캡처합니다. SQL Server Management Studio의 Tools(도구) 메뉴에서 프로파일러를 시작할 수 있습니다. SQL Server 프로파일러(SQL Server Profiler)를 선택하여 프로파일러를 열고 TSQL_Replay 템플릿을 선택합니다.
Babelfish 마이그레이션에 사용하려면 추적을 시작한 다음 기능 테스트를 사용하여 애플리케이션을 실행합니다. 프로파일러는 T-SQL 문을 캡처합니다. 테스트를 마친 후 추적을 중단합니다. 클라이언트 측 쿼리를 사용하여 XML 파일에 결과를 저장합니다(파일(File) > 다른 이름으로 저장(Save as) > XML 파일을 추적하여 재생(Trace XML File for Replay)).
자세한 내용은 Microsoft 설명서에서 SQL Server 프로파일러
를 참조하세요. TSQL_Replay 템플릿에 대한 자세한 내용은 SQL Server 프로파일러 템플릿 을 참조하세요. -
복잡한 클라이언트 측 SQL 쿼리가 있는 애플리케이션의 경우 Babelfish 호환성을 위해 Babelfish Compass를 사용하여 이러한 쿼리를 분석하는 것이 좋습니다. 분석에서 클라이언트 측 SQL 문에 지원되지 않는 SQL 기능이 포함되어 있음이 드러난 경우 클라이언트 애플리케이션의 SQL 측면을 검토하고 필요한 경우 수정합니다.
-
SQL 쿼리를 확장 이벤트(.xel 형식)로 캡처할 수도 있습니다. 이렇게 하려면 SSMS XEvent Profiler를 사용해야 합니다. .xel 파일을 생성한 후, SQL 문을 Compass에서 처리할 수 있는 .xml 파일로 추출합니다. 자세한 내용은 Microsoft 설명서에서 SQL Server 프로파일러
를 참조하세요.
마이그레이션된 애플리케이션에 필요한 모든 테스트, 분석 및 수정이 완료되면 프로덕션용으로 Babelfish 데이터베이스를 사용할 수 있습니다. 이렇게 하려면 원래 데이터베이스를 중지하고 라이브 클라이언트 애플리케이션을 리디렉션하여 Babelfish TDS 포트를 사용하면 됩니다.
참고
AWS DMS는 이제 Babelfish에서 데이터 복제를 지원합니다. 자세한 내용은 이제 AWS DMS가 소스로서 Aurora PostgreSQL용 Babelfish를 지원함
SQL Server 및 Babelfish 간의 차이점 평가 및 처리
최상의 결과를 얻으려면 SQL Server 데이터베이스 애플리케이션을 Babelfish로 실제로 마이그레이션하기 전에 생성된 DDL/DML 및 클라이언트 쿼리 코드를 평가하는 것이 좋습니다. Babelfish의 버전과 애플리케이션에서 구현하는 SQL Server의 특정 기능에 따라 애플리케이션을 리팩터링하거나 Babelfish에서 아직 완전히 지원되지 않는 기능에 대한 대안을 사용해야 할 수 있습니다.
-
SQL Server 애플리케이션 코드를 평가하려면, 생성된 DDL에서 Babelfish Compass를 사용하여 Babelfish에서 얼마나 많은 T-SQL 코드를 지원하는지 확인해야 합니다. Babelfish에서 실행하기 전에 수정이 필요할 수 있는 T-SQL 코드를 식별합니다. 이 도구에 대한 자세한 내용은 GitHub의 Babelfish Compass 도구
를 참조하세요. 참고
Babelfish Compass는 오픈 소스 도구입니다. AWS Support 대신 GitHub를 통해 Babelfish Compass와 관련된 모든 문제를 보고하십시오.
SQL Server Management Studio(SSMS)와 함께 스크립트 생성 마법사를 사용하여, Babelfish Compass 또는 AWS Schema Conversion Tool CLI에서 평가하는 SQL 파일을 생성할 수 있습니다. 다음 단계를 따라 평가를 간소화하는 것이 좋습니다.
-
Choose Objects(객체 선택) 페이지에서 Script entire database and all database objects(전체 데이터베이스 및 모든 데이터베이스 객체 스크립팅)를 선택합니다.
-
Set Scripting Options(스크립팅 옵션 설정)에서 Save as script file(스크립트 파일로 저장)을 Single script file(단일 스크립트 파일)로 선택합니다.
-
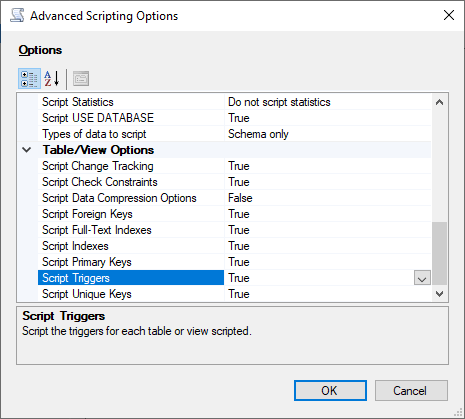
전체 평가에서 일반적으로 false로 설정되는 기능을 식별하도록 기본 스크립팅 옵션을 변경하려면 Advanced(고급)를 선택합니다.
-
Script Change Tracking(스크립트 변경 사항 트래킹)을 True로
-
Script Full-Text Indexes(스크립트 전체 텍스트 인덱스)를 True로
-
Script Triggers(스크립트 트리거)를 True롤
-
Script Logins(스크립트 로그인)를 True로
-
Script Owner(스크립트 소유자)를 True로
-
Script Object-Level Permissions(스크립트 객체 수준 권한)를 True로
-
Script Collations(스크립트 콜레이션)를 True로
-
-
마법사의 나머지 단계를 수행하여 파일을 생성합니다.
SQL Server에서 Babelfish로 마이그레이션하기 위한 가져오기/내보내기 도구
SQL Server에서 Babelfish로 마이그레이션하는 기본 도구로 AWS DMS를 사용하는 것이 좋습니다. 그러나 Babelfish는 다음을 포함한 SQL Server 도구를 사용하여 데이터를 마이그레이션하는 여러 다른 방법을 지원합니다.
-
모든 Babelfish 버전을 위한 SQL Server Integration Services(SSIS) 자세한 내용은 SSIS 및 Babelfish를 사용하여 SQL Server에서 Aurora PostgreSQL로 마이그레이션
을 참조하세요. -
Babelfish 버전 2.1.0 이상에서는 SSMS 가져오기/내보내기 마법사를 사용합니다. 이 도구는 SSMS를 통해 사용할 수 있지만, 독립 실행형 도구로도 지원됩니다. 자세한 내용은 Microsoft 설명서의 SQL Server 가져오기 및 내보내기 마법사 소개
를 참조하세요. -
Microsoft 일괄 데이터 복사 프로그램(bcp) 유틸리티를 사용하면 데이터를 Microsoft SQL Server 인스턴스에서 지정한 형식의 데이터 파일로 복사할 수 있습니다. 자세한 내용은 Microsoft 설명서의 bcp 유틸리티
를 참조하세요. 이제 Babelfish는 BCP 클라이언트를 사용한 데이터 마이그레이션을 지원하고, bcp 유틸리티는 -E플래그(ID 열용) 및 -b 플래그(일괄 삽입용)를 지원합니다.-C,-T,-G,-K,-R,-V및-h를 포함한 특정 bcp 옵션은 지원되지 않습니다.
SQL Server Management Studio(SSMS)를 사용하여 Babelfish로 마이그레이션
각 특정 객체 유형별로 별도의 파일을 생성하는 것이 좋습니다. 먼저 각 DDL 문 세트에 대해 SSMS의 스크립트 생성 마법사를 사용한 다음, 객체를 그룹으로 수정하여 평가 중에 발견된 문제를 해결할 수 있습니다.
AWS DMS 또는 다른 데이터 마이그레이션 방법을 사용하여 데이터를 마이그레이션하려면 다음 단계를 수행하십시오. 이러한 생성 스크립트 유형을 먼저 실행하면 Aurora PostgreSQL의 Babelfish 테이블에 데이터를 더 빠르고 효율적으로 로드할 수 있습니다.
-
CREATE SCHEMA문을 실행합니다. -
CREATE TYPE문을 실행하여 사용자 정의 데이터 유형을 생성합니다. -
기본 키 또는 고유한 제약 조건을 사용하여 기본
CREATE TABLE문을 실행합니다.
권장되는 가져오기/내보내기 도구를 사용하여 데이터 로드를 수행합니다. 다음 단계에 대해 수정된 스크립트를 실행하여 나머지 데이터베이스 객체를 추가합니다. 제약 조건, 트리거 및 인덱스를 대상으로 이러한 스크립트를 실행하려면 create table 문이 필요합니다. 스크립트가 생성되면 create table 문을 삭제합니다.
-
검사 제약 조건, 외래 키 제약 조건, 기본 제약 조건을 대상으로
ALTER TABLE문을 실행합니다. -
CREATE TRIGGER문을 실행합니다. -
CREATE INDEX문을 실행합니다. -
CREATE VIEW문을 실행합니다. -
CREATE STORED PROCEDURE문을 실행합니다.
각 객체 유형에 대한 스크립트를 생성하는 방법
다음 단계를 수행하여, SSMS에서 스크립트 생성 마법사를 사용하여 기본 create table 문을 만듭니다. 동일한 단계를 수행하여 다양한 객체 유형에 대한 스크립트를 생성합니다.
-
기존 SQL Server 인스턴스에 연결합니다.
-
데이터베이스 이름의 컨텍스트 메뉴를 엽니다(마우스 오른쪽 버튼 클릭).
-
Tasks(태스크)를 선택한 다음 Generate Scripts...(스크립트 생성)를 선택합니다.
-
객체 선택(Choose Objects) 창에서 특정 데이터베이스 객체 선택(Select specific database objects)을 선택합니다. 테이블(Tables)을 선택하고 모든 테이블을 선택합니다. 다음을 선택하여 계속 진행합니다.
-
스크립팅 옵션 설정(Set Scripting Options) 페이지에서 고급(Advanced)을 선택하여 옵션(Options) 설정을 엽니다. 기본 create table 명령문을 생성하려면 다음 기본값을 변경해야 합니다.
-
Script Defaults(스크립트 기본값)를 False로 변경합니다.
-
Script Extended Properties(스크립트 확장 속성)을 False로 변경합니다. Babelfish는 확장 속성을 지원하지 않습니다.
-
Script Check Constraints(스크립트 확인 제약 조건)를 False로 변경합니다. Foreign Keys(외래 키)를 False로 변경합니다.
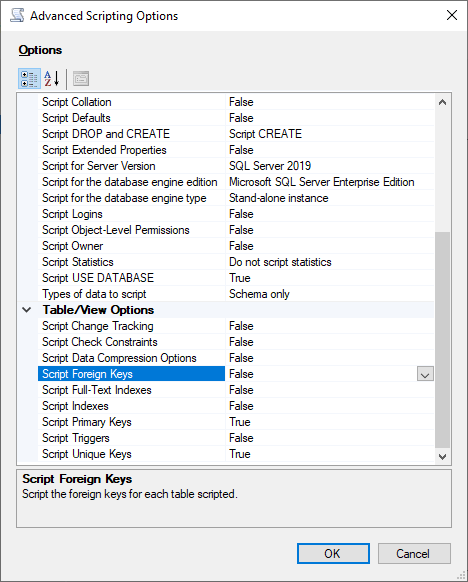
-
-
확인을 선택합니다.
-
Set Scripting Options(스크립팅 옵션 설정)에서 Save as script file(스크립트 파일로 저장)을 선택하고 Single script file(단일 스크립트 파일) 옵션을 선택합니다. File name(파일 이름)을 입력합니다.
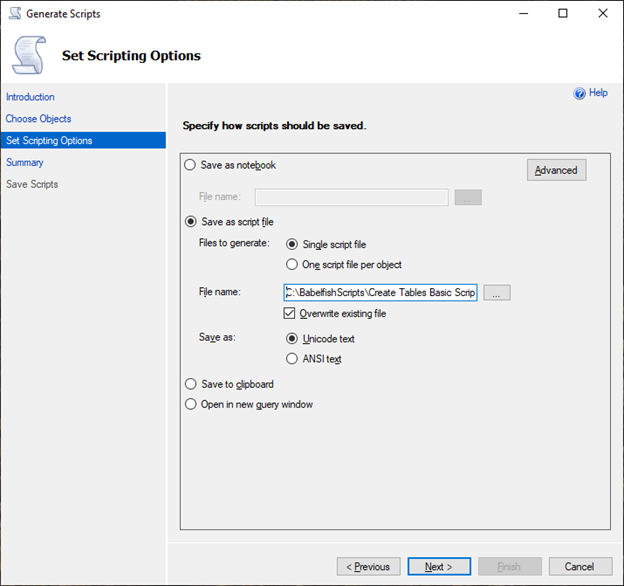
-
Next(다음)를 선택하여 Summary wizard(요약 마법사) 페이지를 확인합니다.
-
Next(다음)를 선택하여 스크립트 생성을 시작합니다.
마법사에서 다른 객체 유형에 대한 스크립트를 계속 생성할 수 있습니다. 파일을 저장되면 Finish(완료)를 선택하는 대신 Previous(이전) 버튼을 세 번 선택하여 Choose Objects(객체 선택) 페이지로 돌아갑니다. 그런 다음 마법사에서 단계를 반복하여 다른 객체 유형에 대한 스크립트를 생성합니다.
