DynamoDB의 구체화된 집계 쿼리에 글로벌 보조 인덱스 사용
빠르게 변화하는 데이터에 대해 근실시간 집계와 주요 지표를 유지하는 것이 빠르게 결정을 내려야 하는 비즈니스에 점점 더 중요해지고 있습니다. 예를 들어, 음악 라이브러리가 가장 많이 다운로드된 노래를 근실시간으로 보여줘야 한다고 가정하겠습니다.
다음과 같은 음악 라이브러리 테이블 레이아웃을 고려하세요.
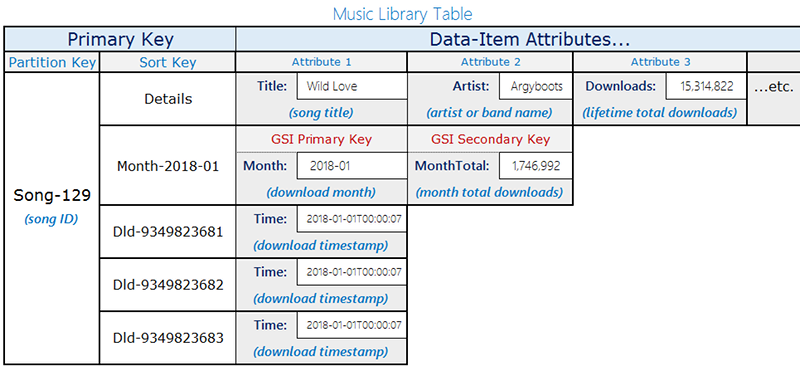
이 예의 테이블은 songID라는 파티션 키로 노래를 저장합니다. 이 테이블에 Amazon DynamoDB Streams를 활성화하고 스트림에 Lambda 함수를 연결하여 각 노래를 다운로드할 때 Partition-Key=SongID 및 Sort-Key=DownloadID로 테이블에 항목을 추가할 수 있습니다. 이런 업데이트를 수행하면 DynamoDB Streams에 Lambda 함수가 트리거됩니다. Lambda 함수는 songID 별로 다운로드를 집계해 그룹화 하고, 최상위 항목, Partition-Key=songID 및 Sort-Key=Month를 업데이트할 수 있습니다. 새 집계된 값을 작성한 직후에 lambda 실행이 실패하면 두 번 이상 다시 시도하고 값을 집계하여 대략적인 값을 제공할 수 있습니다.
한 자리 수 밀리초의 지연 시간으로 근실시간으로 업데이트를 읽으려면, Month=2018-01, ScanIndexForward=False, Limit=1이라는 쿼리 조건으로 글로벌 보조 인덱스를 사용합니다.
여기에서 사용한 또 다른 주요 최적화는 글로벌 보조 인덱스가 희소 인덱스이고, 실시간으로 데이터를 검색하는 쿼리가 필요한 항목에서만 사용할 수 있다는 것입니다. 글로벌 보조 인덱스는 인기가 있는 최상위 10곡이나 해당 월에 다운로드된 노래에 대한 정보가 필요한 또 다른 워크플로우로 기능할 수 있습니다.
