DynamoDB의 시계열 데이터 처리 모범 사례
Amazon DynamoDB의 일반 설계 원칙은 사용할 테이블의 수를 최소한으로 유지할 것을 권장합니다. 대부분의 애플리케이션에서 단 하나의 테이블만 필요합니다. 하지만 시계열 데이터의 경우 기간별로 애플리케이션당 하나의 테이블을 사용하여 처리하는 것이 가장 좋을 수도 있습니다.
시계열 데이터의 설계 패턴
많은 볼륨의 이벤트를 추적하고 싶은 경우에 일반적인 시계열 시나리오를 고려하세요. 쓰기 액세스 패턴은 기록할 모든 이벤트가 오늘 날짜인 패턴입니다. 읽기 액세스 패턴은 오늘 이벤트를 가장 많이, 어제 이벤트는 이보다 적게, 더 오래된 이벤트는 거의 읽지 않는 패턴입니다. 이 문제를 처리하는 한 가지 방법은 현재 데이터와 시간을 기본 키에 빌드하는 것입니다.
이런 종류의 시나리오를 가장 효과적으로 처리할 수 있는 설계 패턴입니다.
-
필요한 읽기 및 쓰기 용량과 필요한 인덱스로 프로비저닝되는 테이블을 기간당 하나씩 생성합니다.
-
각 기간이 끝나기 전에 다음 기간에 대한 테이블을 사전에 빌드합니다. 현재 기간이 끝나면, 이벤트 트래픽을 새 테이블로 보냅니다. 기록 기간이 설명된 테이블에 이름을 지정할 수 있습니다.
-
테이블에 기록이 중지된 즉시 프로비저닝된 쓰기 용량은 더 낮은 값(예: 1WCU)으로 줄이고, 적절한 읽기 용량을 프로비저닝합니다. 시간이 지나면서 이전 테이블에 프로비저닝된 읽기 용량을 줄입니다. 내용이 거의 또는 아예 필요 없다면 테이블을 아카이브하거나 삭제할 수 있습니다.
가장 높은 트래픽 볼륨이 발생하는 현재 기간에 필요한 리소스를 할당하고 적극적으로 사용되지 않는 이전 테이블에 대한 프로비저닝을 축소하여 비용을 절감하는 것이 좋습니다. 비즈니스 요구 사항에 따라 논리적 파티션 키에 트래픽을 균등하게 배포하기 위해 쓰기 샤딩을 고려해야 할 수 있습니다. 자세한 내용은 쓰기 샤딩을 사용해 DynamoDB 테이블에 워크로드를 고르게 배포 섹션을 참조하세요.
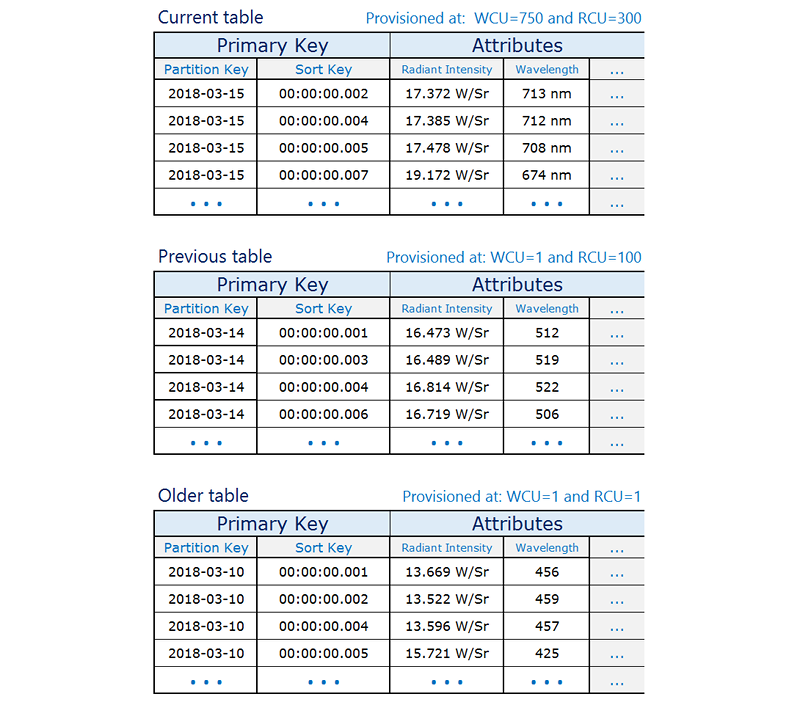
시계열 테이블 예
다음은 현재 테이블은 더 높은 읽기/쓰기 용량으로 프로비저닝되고 이전 테이블은 자주 액세스되지 않으므로 축소되는 시계열 데이터 예입니다.