DynamoDB의 데이터 모델링 기초
이 섹션에서는 단일 테이블과 다중 테이블이라는 두 가지 테이블 설계 유형을 살펴보며 기초 계층을 다룹니다.
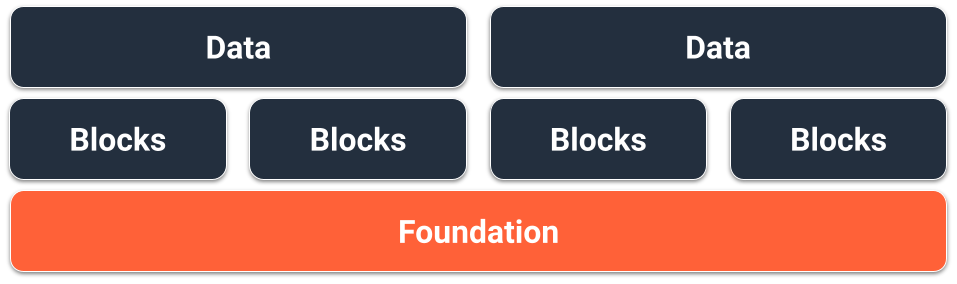
단일 테이블 설계 기초
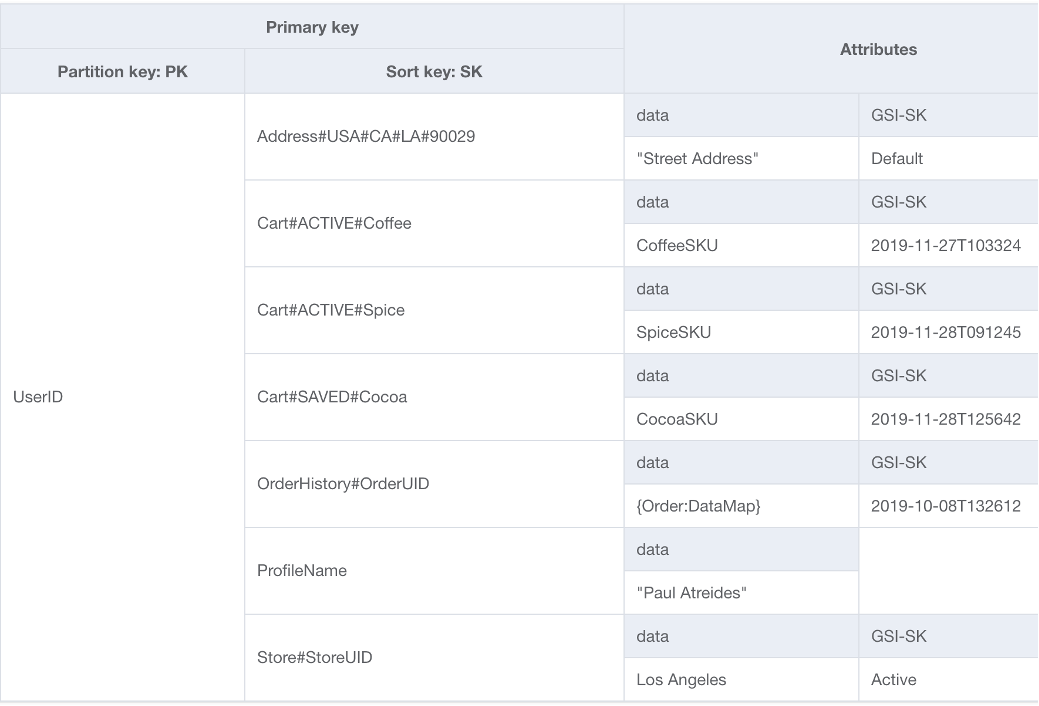
DynamoDB 스키마의 기초를 위한 한 가지 선택은 단일 테이블 설계입니다. 단일 테이블 설계는 단일 DynamoDB 테이블에 여러 유형(엔터티)의 데이터를 저장할 수 있는 패턴입니다. 그 목표는 여러 테이블을 유지 관리할 필요와 테이블 간의 복잡한 관계를 제거함으로써 데이터 액세스 패턴을 최적화하고 성능을 개선하며 비용을 절감하는 것입니다. 이것이 가능한 이유는 DynamoDB가 동일한 파티션 키를 가진 항목들(항목 컬렉션이라고 함)을 서로 동일한 파티션에 저장하기 때문입니다. 이 설계에서는 서로 다른 유형의 데이터가 동일한 테이블에 항목으로 저장되고, 각 항목은 고유한 정렬 키로 식별됩니다.
장점
-
단일 데이터베이스 직접 호출로 여러 엔터티 유형에 대한 쿼리를 지원하는 데이터 로컬리티
-
전체 읽기 비용 및 지연 시간 비용 절감:
-
합계 4KB 미만인 두 항목에 대한 단일 쿼리는 0.5RCU 최종적으로 일관된 읽기입니다.
-
합계 4KB 미만인 두 항목에 대한 두 번의 쿼리는 1RCU 최종적으로 일관된 읽기입니다(각각 0.5 RCU).
-
두 개의 개별 데이터베이스 직접 호출을 반환하는 데 걸리는 시간은 평균적으로 단일 직접 호출보다 깁니다.
-
-
관리할 테이블 수 감소:
-
여러 IAM 역할 또는 정책에서 권한을 유지 관리할 필요가 없습니다.
-
테이블 용량 관리는 모든 엔터티에서 평균화되므로 일반적으로 소비 패턴의 예측 가능성이 높아집니다.
-
모니터링에 필요한 경보 감소
-
고객 관리형 암호화 키는 한 테이블에서만 교체하면 됩니다.
-
-
테이블로 가는 트래픽 평탄화:
-
여러 사용량 패턴을 동일한 테이블에 집계하면 전체 사용량이 더 평탄해지고(주가 지수의 성과가 개별 주식보다 평탄해지는 것처럼), 프로비저닝된 모드 테이블을 사용하면 사용률을 높이는 데 더 효과적입니다.
-
단점
-
관계형 데이터베이스와 비교할 때 역설적인 설계로 인해 학습 곡선이 가팔라질 수 있습니다.
-
모든 엔터티 유형에서 데이터 요구 사항이 일관되어야 합니다.
-
백업은 전부 아니면 전무 방식이므로 업무상 중요하지 않은 데이터가 있다면 별도의 테이블에 보관하는 것이 좋습니다.
-
테이블 암호화가 모든 항목에서 공유됩니다. 개별 테넌트 암호화 요구 사항이 있는 멀티테넌트 애플리케이션의 경우, 클라이언트측 암호화가 필요합니다.
-
기록 데이터와 운영 데이터가 혼합된 테이블에서는 Infrequent Access 스토리지 클래스를 활성화해도 이점이 그리 크지 않습니다. 자세한 내용은 DynamoDB 테이블 클래스 섹션을 참조하세요.
-
-
일부 엔터티만 처리해야 하는 경우에도 변경된 모든 데이터가 DynamoDB Streams로 전파됩니다.
-
Lambda 이벤트 필터 덕분에 Lambda를 사용할 때는 이것이 청구서에 영향을 미치지 않지만 Kinesis Consumer Library를 사용할 때는 추가 비용이 발생합니다.
-
-
GraphQL을 사용할 경우, 단일 테이블 설계를 구현하기가 더 어렵습니다.
-
Java의 DynamoDBMapper 또는 Enhanced Client 같은 상위 수준 SDK 클라이언트를 사용하는 경우, 동일한 응답의 항목들이 서로 다른 클래스에 연결될 수 있으므로 결과를 처리하기가 더 어려울 수 있습니다.
사용해야 하는 경우
단일 테이블 설계는 여러 엔터티 유형을 함께 자주 쿼리하거나 서로 다른 데이터 유형 간의 관계를 유지해야 하는 애플리케이션에 적합합니다. 액세스 패턴이 데이터 지역성의 이점을 얻고 여러 테이블 관리의 오버헤드를 최소화하려는 경우에 특히 효과적입니다.
다중 테이블 설계 기초
DynamoDB 스키마의 기초를 위한 두 번째 선택은 다중 테이블 설계입니다. 다중 테이블 설계는 각 DynamoDB 테이블에 단일 유형(엔터티)의 데이터를 저장하는 기존 데이터베이스 설계와 비슷한 패턴입니다. 각 테이블 내의 데이터는 여전히 파티션 키에 의해 구성되므로 단일 엔터티 유형 내의 성능은 확장성과 성능에 최적화되지만 여러 테이블에 걸친 쿼리는 독립적으로 수행해야 합니다.
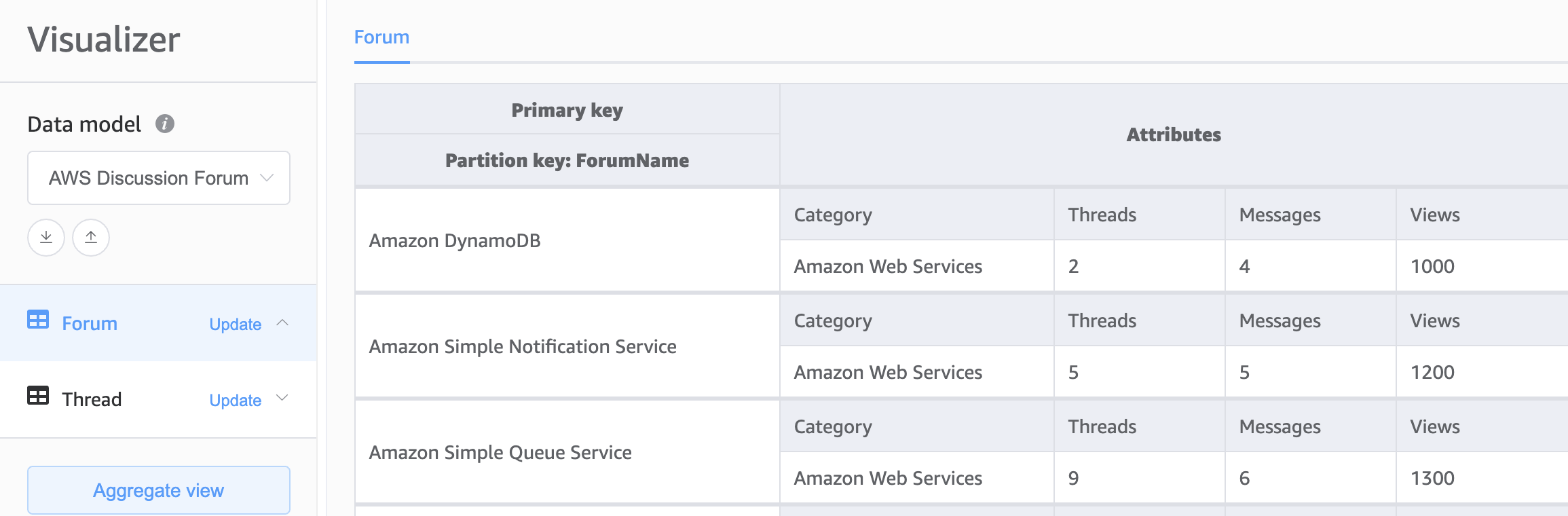
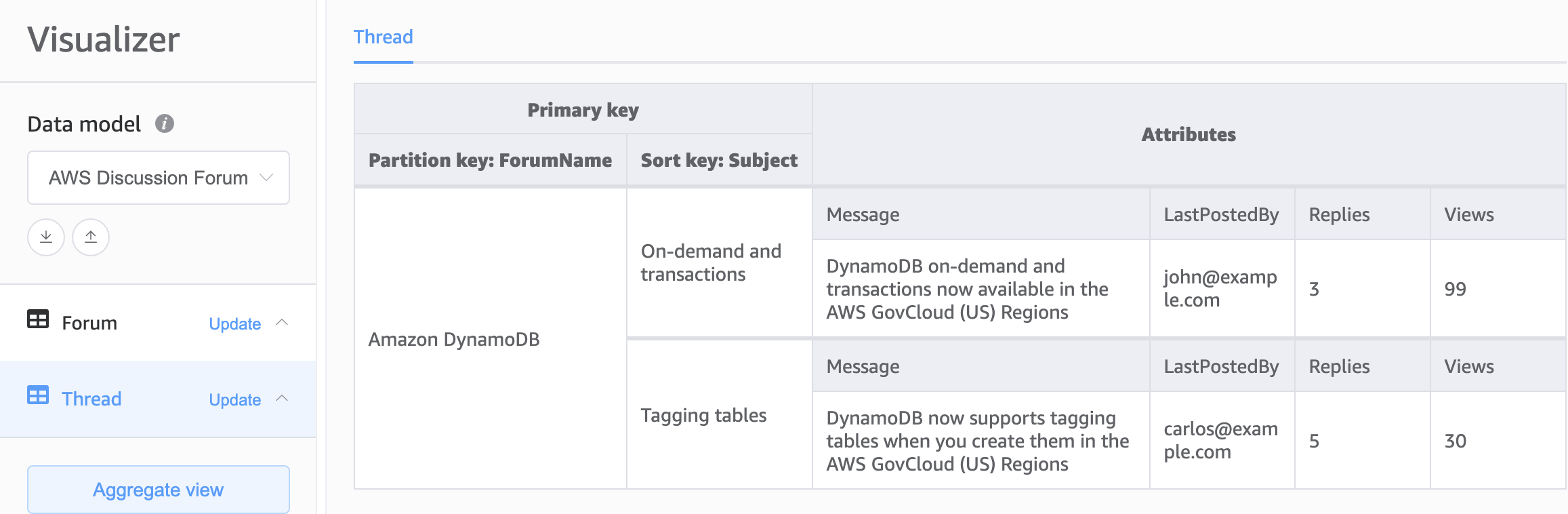
장점
-
단일 테이블 설계에 익숙하지 않은 사용자들이 설계하기에 더 간단합니다.
-
각 리졸버가 단일 엔터티(테이블)에 매핑되므로 GraphQL 리졸버를 더 쉽게 구현할 수 있습니다.
-
다양한 엔터티 유형에서 고유한 데이터 요구 사항 가능:
-
업무상 중요한 개별 테이블을 백업할 수 있습니다.
-
각 테이블의 테이블 암호화를 관리할 수 있습니다. 개별 테넌트 암호화 요구 사항이 있는 멀티테넌트 애플리케이션의 경우, 별도의 테넌트 테이블을 통해 각 고객이 자체 암호화 키를 가질 수 있습니다.
-
기록 데이터가 있는 테이블에서만 Infrequent Access 스토리지 클래스를 활성화하여 비용 절감 효과를 극대화할 수 있습니다. 자세한 내용은 DynamoDB 테이블 클래스 섹션을 참조하세요.
-
-
각 테이블에는 고유한 변경 데이터 스트림이 있으므로 단일 모놀리식 프로세서 대신 각 항목 유형에 맞는 전용 Lambda 함수를 설계할 수 있습니다.
단점
-
여러 테이블의 데이터가 필요한 액세스 패턴의 경우, DynamoDB에서 여러 번 읽어야 하며, 클라이언트 코드에서 데이터를 처리/결합해야 할 수 있습니다.
-
여러 테이블을 운영 및 모니터링하려면 더 많은 CloudWatch 경보가 필요하며, 각 테이블 규모를 독립적으로 조정해야 합니다.
-
각 테이블 권한을 개별적으로 관리해야 합니다. 향후 테이블을 추가하려면 필요한 IAM 역할 또는 정책을 변경해야 합니다.
사용해야 하는 경우
애플리케이션의 액세스 패턴에서 여러 엔터티 또는 테이블을 함께 쿼리할 필요가 없다면 다중 테이블 설계가 좋고 충분한 접근 방식입니다.
