외부 Hive 메타스토어 사용
Apache Hive 메타스토어를 사용하는 Amazon S3에서 데이터 세트를 쿼리하기 위해 외부 Hive 메타스토어에 Amazon Athena 데이터 커넥터를 사용할 수 있습니다. 메타데이터를 AWS Glue Data Catalog로 마이그레이션할 필요가 없습니다. Athena 관리 콘솔에서 프라이빗 VPC에 있는 Hive 메타스토어와 통신하는 Lambda 함수를 구성한 다음 메타스토어에 연결합니다. Lambda에서 Hive 메타스토어로의 연결은 프라이빗 Amazon VPC 채널로 보호되며 퍼블릭 인터넷을 사용하지 않습니다. 자체 Lambda 함수 코드를 제공하거나 외부 Hive 메타스토어에 대한 Athena 데이터 커넥터의 기본 구현을 사용할 수 있습니다.
주제
기능 개요
외부 Hive 메타스토어에 대한 Athena 데이터 커넥터를 사용하여 다음 작업을 수행할 수 있습니다.
-
Athena 콘솔을 사용하여 사용자 지정 카탈로그를 등록하고 사용자 지정 카탈로그를 사용하여 쿼리를 실행합니다.
-
여러 외부 Hive 메타스토어에 대한 Lambda 함수를 정의하고 Athena 쿼리에 조인합니다.
-
동일한 Athena 쿼리에서 외부 Hive 메타스토어 및 AWS Glue Data Catalog를 사용합니다.
-
쿼리 실행 컨텍스트의 카탈로그를 현재 기본 카탈로그로 지정합니다. 이렇게 하면 쿼리의 데이터베이스 이름에 카탈로그 이름을 접두사로 붙일 필요가 없습니다.
catalog.database.tabledatabase.table -
다양한 도구를 사용하여 외부 Hive 메타스토어를 참조하는 쿼리를 실행합니다. Athena 콘솔, AWS CLI, AWS SDK, Athena API, 업데이트된 Athena JDBC 및 ODBC 드라이버를 사용할 수 있습니다. 업데이트된 드라이버는 사용자 지정 카탈로그를 지원합니다.
API 지원
외부 Hive 메타스토어용 Athena 데이터 커넥터에는 카탈로그 등록 API 작업 및 메타데이터 API 작업에 대한 지원이 포함되어 있습니다.
-
카탈로그 등록 – 외부 Hive 메타스토어 및 연합 데이터 원본에 대한 사용자 지정 카탈로그를 등록합니다.
-
메타데이터 - 메타데이터 API를 사용하여 AWS Glue에 대한 데이터베이스 및 테이블 정보와 Athena를 통해 등록한 모든 카탈로그를 제공합니다.
-
Athena JAVA SDK 클라이언트 - 업데이트된 Athena Java SDK 클라이언트에서
StartQueryExecution작업의 카탈로그에 대한 지원, 메타데이터 API 및 카탈로그 등록을 사용합니다.
참조 구현
Athena는 외부 Hive 메타스토어에 연결하는 Lambda 함수에 대한 참조 구현을 제공합니다. 참조 구현은 Athena Hive 메타스토어
참조 구현은 AWS Serverless Application Repository(SAR)에서 다음 두 AWS SAM 애플리케이션으로 사용할 수 있습니다. SAR에서 이러한 애플리케이션 중 하나를 사용하여 Lambda 함수를 직접 만들 수 있습니다.
-
AthenaHiveMetastoreFunction- Uber Lambda 함수.jar파일. "uber" JAR(fat JAR 또는 종속 항목이 있는 JAR이라고도 함)은 하나의 파일에 Java 프로그램과 해당 종속 항목을 모두 포함한.jar파일입니다. -
AthenaHiveMetastoreFunctionWithLayer- Lambda 계층 및 thin Lambda 함수.jar파일.
워크플로
다음 다이어그램은 Athena가 외부 Hive 메타스토어와 상호 작용하는 방식을 보여줍니다.
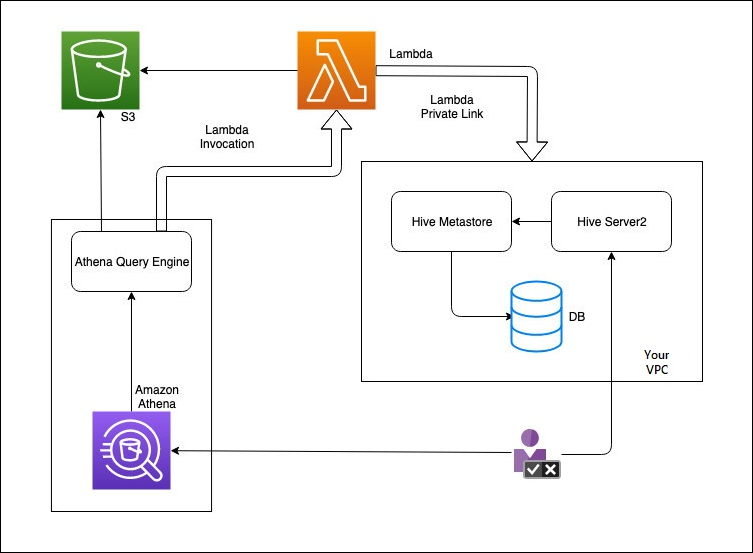
이 워크플로우에서는 데이터베이스에 연결된 Hive 메타스토어가 VPC 내에 있습니다. Hive CLI를 사용하는 Hive 메타스토어를 관리하는 데 Hive Server2를 사용합니다.
Athena의 외부 Hive 메타스토어를 사용하는 워크플로우에는 다음 단계가 포함됩니다.
-
VPC 내에 있는 Hive 메타스토어에 Athena를 연결하는 Lambda 함수를 생성합니다.
-
Hive 메타스토어에 고유한 카탈로그 이름과 계정에 해당 함수 이름을 등록합니다.
-
카탈로그 이름을 사용하는 Athena DML 또는 DDL 쿼리를 실행하면 Athena 쿼리 엔진은 카탈로그 이름과 연결된 Lambda 함수 이름을 호출합니다.
-
Lambda 함수는 AWS PrivateLink를 사용하여 VPC의 외부 Hive 메타스토어와 통신하고 메타데이터 요청에 대한 응답을 수신합니다. Athena는 기본 AWS Glue Data Catalog의 데이데이터를 사용하는 방식과 동일하게 외부 Hive 메타스토어의 메타데이터를 사용합니다.
고려 사항 및 제한
외부 Hive 메타스토어용 Athena 데이터 커넥터를 사용하는 경우 다음 사항을 고려해야 합니다.
-
CTAS를 사용하여 외부 Hive 메타스토어에서 테이블을 생성할 수 있습니다.
-
INSERT INTO를 사용하여 외부 Hive 메타스토어에 데이터를 삽입할 수 있습니다.
-
외부 Hive 메타스토어에 대한 DDL 지원은 다음 문으로 제한됩니다.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
데이터베이스 생성
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
보유할 수 있는 등록된 카탈로그의 최대 수는 1,000개입니다.
-
Hive 메타스토어에 대한 Kerberos 인증은 지원되지 않습니다.
-
JDBC 드라이버와 함께 연합 쿼리나 외부 Hive 메타스토어를 사용하려면 JDBC 연결 문자열에
MetadataRetrievalMethod=ProxyAPI를 포함해야 합니다. JDBC 드라이버에 대한 자세한 내용은 JDBC로 Amazon Athena에 연결 섹션을 참조하세요. -
Hive 숨김 열
$path,$bucket,$file_size,$file_modified_time,$partition,$row_id는 세분화된 액세스 제어 필터링에 사용할 수 없습니다. -
Hive 숨김 시스템 테이블(예:
example_table$partitionsexample_table$properties
권한
사전 구축된 사용자 지정 데이터 커넥터가 올바르게 작동하려면 다음 리소스에 액세스해야 할 수 있습니다. 사용하는 커넥터의 정보를 확인하여 VPC를 올바르게 구성했는지 확인합니다. Athena에서 쿼리를 실행하고 데이터 원본 커넥터를 만드는 데 필요한 IAM 권한에 대한 자세한 내용은 외부 Hive 메타스토어용 Athena 데이터 커넥터에 대한 액세스 허용 및 외부 Hive 메타스토어에 대한 Lambda 함수 액세스 허용 단원을 참조하세요.
-
Amazon S3 – 쿼리 결과를 Amazon S3의 Athena 쿼리 결과 위치에 작성하는 것 외에도 데이터 커넥터는 Amazon S3의 유출 버킷에 작성합니다. 이 Amazon S3 위치에 대한 연결 및 권한이 필요합니다. 자세한 내용은 이 주제의 후반부에서 Amazon S3의 분산 위치 단원을 참조하세요.
-
Athena – 쿼리 상태를 확인하고 오버스캔을 방지하려면 액세스가 필요합니다.
-
AWS Glue - 커넥터가 보충 또는 기본 메타데이터에 AWS Glue를 사용하는 경우 액세스가 필요합니다.
-
AWS Key Management Service
-
정책 - Hive 메타스토어, Athena Query Federation 및 UDF에는 AWS 관리형 정책: AmazonAthenaFullAccess 외의 정책이 필요합니다. 자세한 내용은 Athena의 자격 증명 및 액세스 관리 단원을 참조하세요.
Amazon S3의 분산 위치
Athena 함수 응답 크기에는 제한이 있기 때문에 임계값을 초과하는 응답은 Lambda 함수를 생성할 때 지정한 Amazon S3 위치로 분산됩니다. Athena는 이러한 응답을 Amazon S3로부터 직접 읽습니다.
참고
Athena는 Amazon S3의 응답 파일을 제거하지 않습니다. 응답 파일을 자동으로 삭제하도록 보존 정책을 설정하는 것이 좋습니다.
