기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Chime SDK 데이터 레이크 생성
Amazon Chime SDK 통화 분석 데이터 레이크를 사용하면 Amazon Kinesis Data Stream의 기계 학습 기반 인사이트와 모든 메타데이터를 Amazon S3 버킷으로 스트리밍할 수 있습니다. 예를 들어, 데이터 레이크를 사용하여 레코딩 URL에 액세스할 수 있습니다. 데이터 레이크를 생성하려면 Amazon Chime SDK 콘솔에서 또는를 사용하여 프로그래밍 방식으로 AWS CloudFormation 템플릿 세트를 배포합니다 AWS CLI. 데이터 레이크를 사용하면 Amazon Athena의 AWS Glue 데이터 테이블을 참조하여 통화 메타데이터 및 음성 분석 데이터를 쿼리할 수 있습니다.
사전 조건
Amazon Chime SDK 레이크를 생성하려면 다음 항목이 있어야 합니다.
-
Amazon Kinesis Data Stream. 자세한 내용은 Amazon Kinesis Streams 개발자 안내서의 AWS Management Console을 통한 스트림 생성을 참조하세요.
-
S3 버킷. 자세한 내용은 Amazon S3 사용 설명서의 첫 번째 Amazon S3 버킷 생성을 참조하세요.
데이터 레이크 용어 및 개념
다음 용어와 개념을 사용하여 데이터 레이크의 작동 방식을 이해하세요.
- Amazon Kinesis Data Firehose
-
추출, 전환, 적재(ETL) 서비스로서 스트리밍 데이터를 안정적으로 캡처, 변환하여 데이터 레이크, 데이터 스토어, 분석 서비스로 전달합니다. 자세한 내용은 Amazon Kinesis Data Firehose란 무엇인가요?(What Is Amazon Kinesis Data Firehose?)를 참조하세요.
- Amazon Athena
-
Amazon Athena는 표준 SQL을 사용하여 Amazon S3의 데이터를 분석할 수 있는 대화형 쿼리 서비스입니다. Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불하면 됩니다. Athena를 사용하려면 Amazon S3의 데이터를 가리키고 스키마를 정의한 다음 표준 SQL 쿼리를 사용하세요. 또한 작업 그룹을 사용하여 사용자를 그룹화하고 쿼리를 실행할 때 액세스할 수 있는 리소스를 제어할 수도 있습니다. 작업 그룹을 사용하면 다양한 사용자 및 워크로드 그룹에서 쿼리 동시성을 관리하고 쿼리 실행의 우선순위를 지정할 수 있습니다.
- Glue Data 카탈로그
-
Amazon Athena에서 테이블과 데이터베이스에는 기본 소스 데이터의 스키마를 자세히 설명하는 메타데이터가 포함되어 있습니다. 각 데이터 세트에 대한 테이블이 Athena에 반드시 있어야 합니다. 테이블의 메타데이터는 Athena에게 Amazon S3 버킷의 위치를 알려줍니다. 또한 열 이름, 데이터 유형, 테이블 이름과 같은 데이터 구조를 지정합니다. 데이터베이스에는 데이터 세트의 메타데이터와 스키마 정보만 보관됩니다.
다중 데이터 레이크 생성
고유한 Glue 데이터베이스 이름을 제공하여 통화 인사이트를 저장할 위치를 지정함으로써 여러 데이터 레이크를 생성할 수 있습니다. 특정 AWS 계정의 경우 각각 해당 데이터 레이크가 있는 여러 통화 분석 구성이 있을 수 있습니다. 즉, 보존 정책 사용자 지정 및 데이터 저장 방식에 대한 액세스 정책과 같은 특정 사용 사례에 데이터 분리를 적용할 수 있습니다. 인사이트, 기록, 메타데이터에 대한 액세스에 다양한 보안 정책이 적용될 수 있습니다.
데이터 레이크 리전별 가용성
Amazon Chime SDK 데이터 레이크는 다음 리전에서 사용할 수 있습니다.
리전 |
Glue 테이블 |
QuickSight |
|---|---|---|
us-east-1 |
사용 가능 |
Available |
us-west-2 |
사용 가능 |
Available |
eu-central-1 |
사용 가능 |
Available |
데이터 레이크 아키텍처
다음 다이어그램은 데이터 레이크 아키텍처를 보여줍니다. 그림의 숫자는 아래 번호가 매겨진 텍스트와 일치합니다.
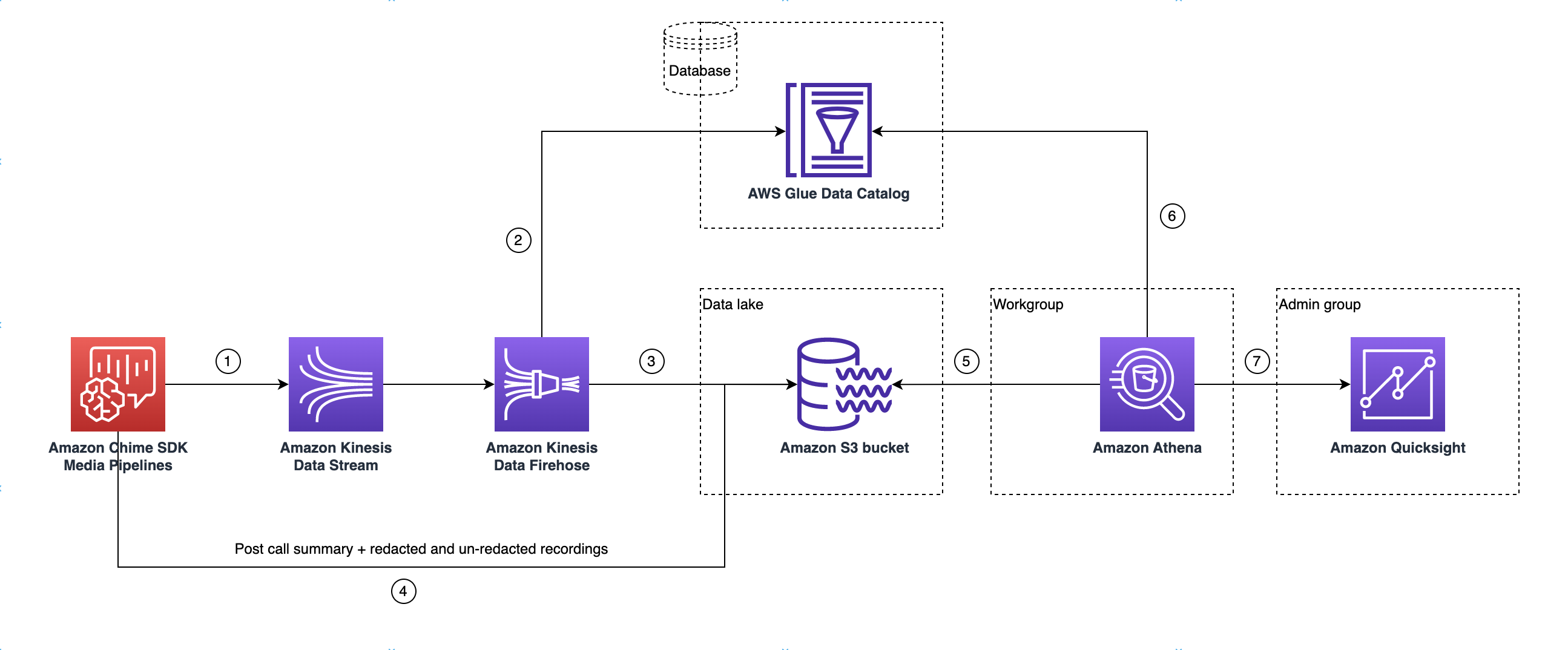
다이어그램에서 AWS 콘솔을 사용하여 미디어 인사이트 파이프라인 구성 설정 워크플로에서 CloudFormation 템플릿을 배포하면 다음 데이터가 Amazon S3 버킷으로 흐릅니다.
-
Amazon Chime SDK 통화 분석은 고객의 Kinesis Data Stream으로 실시간 데이터를 스트리밍하기 시작합니다.
-
Amazon Kinesis Firehose는 누적된 데이터가 128MB 또는 60초 경과 중 빠른 시점이 될 때까지 이 실시간 데이터를 버퍼링합니다. 그런 다음 Firehose는 Glue 데이터 카탈로그에서
amazon_chime_sdk_call_analytics_firehose_schema를 사용하여 데이터를 압축하고 JSON 레코드를 Parquet 파일로 변환합니다. -
Parquet 파일은 Amazon S3 버킷에 파티셔닝된 형식으로 저장됩니다.
-
실시간 데이터 외에도 통화 후 Amazon Transcribe Call Analytics 요약 .wav 파일(구성에 지정된 경우 편집되거나 편집되지 않음) 및 통화 레코딩 .wav 파일도 Amazon S3 버킷으로 전송됩니다.
-
Amazon Athena와 표준 SQL을 사용하여 Amazon S3 버킷에서 데이터를 쿼리할 수 있습니다.
-
또한 CloudFormation 템플릿은 Athena를 통해 이 통화 후 요약 데이터를 쿼리할 수 있는 Glue 데이터 카탈로그를 생성합니다.
-
QuickSight를 사용하여 Amazon S3 버킷의 모든 데이터를 시각화할 수도 있습니다. QuickSight는 Amazon Athena를 사용하여 Amazon S3 버킷과의 연결을 구축합니다.
Amazon Athena 테이블은 다음 기능을 사용하여 쿼리 성능을 최적화합니다.
- 데이터 파티셔닝
-
파티셔닝은 테이블을 여러 부분으로 나누고 날짜, 국가, 리전과 같은 열 값을 기준으로 관련 데이터를 함께 유지합니다. 파티션은 가상 열 역할을 합니다. 이 경우 CloudFormation 템플릿은 테이블 생성 시 파티션을 정의하므로 쿼리당 스캔되는 데이터의 양을 줄이고 성능을 개선하는 데 도움이 됩니다. 파티션별로 필터링하여 쿼리가 검사하는 데이터의 양을 제한할 수도 있습니다. Parquet 데이터를 읽는 데 Athena를 사용하는 방법에 대한 자세한 내용은 Amazon Athena 사용 설명서의 Athena에서 데이터 분할을 참조하세요.
이 예제에서는 날짜가 2023년 1월 1일인 파티션 구조를 보여줍니다.
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
DETAIL_TYPE이 다음 중 하나여야 합니다.-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- 열 기반 데이터 저장소 생성 최적화
-
Apache Parquet은 열 단위 압축, 데이터 유형에 따른 압축, 조건부 푸시다운을 사용하여 데이터를 저장합니다. 압축률이 높거나 데이터 블록을 건너뛰면 Amazon S3 버킷에서 읽는 바이트 수가 줄어듭니다. 따라서 쿼리 성능이 향상되고 비용이 절감됩니다. 이러한 최적화를 위해 Amazon Kinesis Data Firehose에서 JSON에서 parquet 데이터로의 데이터 변환이 활성화되어 있습니다.
- 파티션 프로젝션
-
이 Athena 기능은 날짜별 파티션을 자동으로 생성하여 날짜 기반 쿼리 성능을 향상시킵니다.
데이터 레이크 설정
Amazon Chime SDK 콘솔을 사용하여 다음 단계를 완료하세요.
-
Amazon Chime SDK 콘솔( https://console.aws.amazon.com/chime-sdk/home
)을 시작하고 탐색 창의 통화 분석 아래에서 구성을 선택합니다. -
1단계를 완료하고 다음을 선택한 후 2단계 페이지에서 음성 분석 확인란을 선택합니다.
-
출력 세부 정보에서 기록 분석을 수행하기 위한 데이터 웨어하우스 확인란을 선택한 다음 CloudFormation 스택 배포 링크를 선택합니다.
시스템이 CloudFormation 콘솔의 빠른 스택 생성 페이지로 이동합니다.
-
스택 이름을 입력한 후 다음 파라미터를 입력합니다.
-
DataLakeType- 통화 분석 데이터 레이크 생성을 선택합니다. -
KinesisDataStreamName- 스트림을 선택합니다. 통화 분석 스트리밍에 사용되는 스트림이어야 합니다. -
S3BucketURI- Amazon S3 버킷을 선택합니다. URI에는 접두사s3://가 있어야 합니다.bucket-name -
GlueDatabaseName- 고유한 AWS Glue 데이터베이스 이름을 선택합니다. AWS 계정에 있는 기존 데이터베이스는 재사용할 수 없습니다.
-
-
승인 체크박스를 선택한 다음 데이터 레이크 생성을 선택합니다. 시스템에서 레이크를 생성하는 데 10분 정도 걸릴 수 있습니다.
를 사용한 데이터 레이크 설정 AWS CLI
AWS CLI 를 사용하여 CloudFormation의 생성 스택을 호출할 권한이 있는 역할을 생성합니다. 아래 절차에 따라 IAM 역할을 생성하고 설정하세요. 자세한 내용을 알아보려면AWS CloudFormation 사용 설명서의 스택 생성을 참조하세요.
-
AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role이라는 역할을 생성하고 CloudFormation이 역할을 맡도록 허용하는 역할에 신뢰 정책을 연결합니다.
-
다음 템플릿을 사용하여 IAM 신뢰 정책을 생성하고 파일을.json 형식으로 저장합니다.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
aws iam create-role 명령을 실행하고 신뢰 정책을 파라미터로 전달합니다.
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
응답에서 반환된 role arn을 기록해 둡니다. 다음 단계에서 role arn이 필요합니다.
-
-
CloudFormation 스택을 생성할 수 있는 권한이 있는 정책을 생성합니다.
-
다음 템플릿을 사용하여 IAM 정책을 생성하고 파일을 .json 형식으로 저장합니다. 이 파일은 create-policy를 호출할 때 필요합니다.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
aws iam create-policy를 실행하고 스택 정책 생성을 파라미터로 전달합니다.
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
응답에서 반환된 role arn을 기록해 둡니다. 다음 단계에서 role arn이 필요합니다.
-
-
aws iam attach-role-policy 정책을 역할에 연결합니다.
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
CloudFormation 스택을 생성하고 필수 파라미터 aws cloudformation create-stack을 입력합니다.
ParameterValue를 사용하여 각 ParameterKey에 대한 파라미터 값을 제공합니다.
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
데이터 레이크 설정으로 생성된 리소스
다음 표에는 데이터 레이크를 생성할 때 생성되는 리소스가 나열되어 있습니다.
리소스 유형 |
리소스 이름 및 설명 |
서비스 이름 |
|---|---|---|
AWS Glue 데이터 카탈로그 데이터베이스 |
GlueDatabaseName - 통화 인사이트 및 음성 분석에 속하는 모든 AWS Glue 데이터 테이블을 논리적으로 그룹화합니다. |
통화 분석, 음성 분석 |
|
AWS Glue 데이터 카탈로그 테이블 |
amazon_chime_sdk_call_analytics_firehose_schema - Kinesis Firehose에 제공되는 통화 분석 음성 분석을 위한 통합 스키마입니다. |
통화 분석, 음성 분석 |
call_analytics_metadata - 통화 분석 메타데이터를 위한 스키마입니다. SIPmetadata 및 OneTimeMetadata가 포함되어 있습니다. |
통화 분석 |
|
| call_analytics_recording_metadata – 녹음 및 음성 향상 메타데이터에 대한 스키마 | 통화 분석, 음성 분석 | |
transcribe_call_analytics - TranscribeCallAnalytics 페이로드 ‘utteranceEvent’의 스키마 |
통화 분석 |
|
transcribe_call_analytics_category_events – TranscribeCallAnalytics 페이로드 ‘categoryEvent’의 스키마 |
통화 분석 |
|
transcribe_call_analytics_post_call - 통화 후 트랜스크립션 콜 분석 요약 페이로드에 대한 스키마 |
통화 분석 |
|
transcribe - Transcribe 페이로드 스키마 |
통화 분석 |
|
voice_analytics_status – 음성 분석 준비 이벤트를 위한 스키마 |
음성 분석 |
|
speaker_search_status – 식별 매치를 위한 스키마 |
음성 분석 |
|
voice_tone_analysis_status – 음성 톤 분석 이벤트를 위한 스키마 |
음성 분석 |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-call-analytics- |
통화 분석, 음성 분석 |
Amazon Athena 작업 그룹 |
GlueDatabaseName-AmazonChimeSDKDataAnalytics – 쿼리를 실행할 때 액세스할 수 있는 리소스를 제어하는 논리적 사용자 그룹입니다. |
통화 분석, 음성 분석 |
