기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS Clean Rooms ML의 사용자 지정 모델링
기술적 관점에서 다음 다이어그램은 AWS Clean Rooms ML에서 사용자 지정 ML 모델링이 작동하는 방식을 설명합니다.
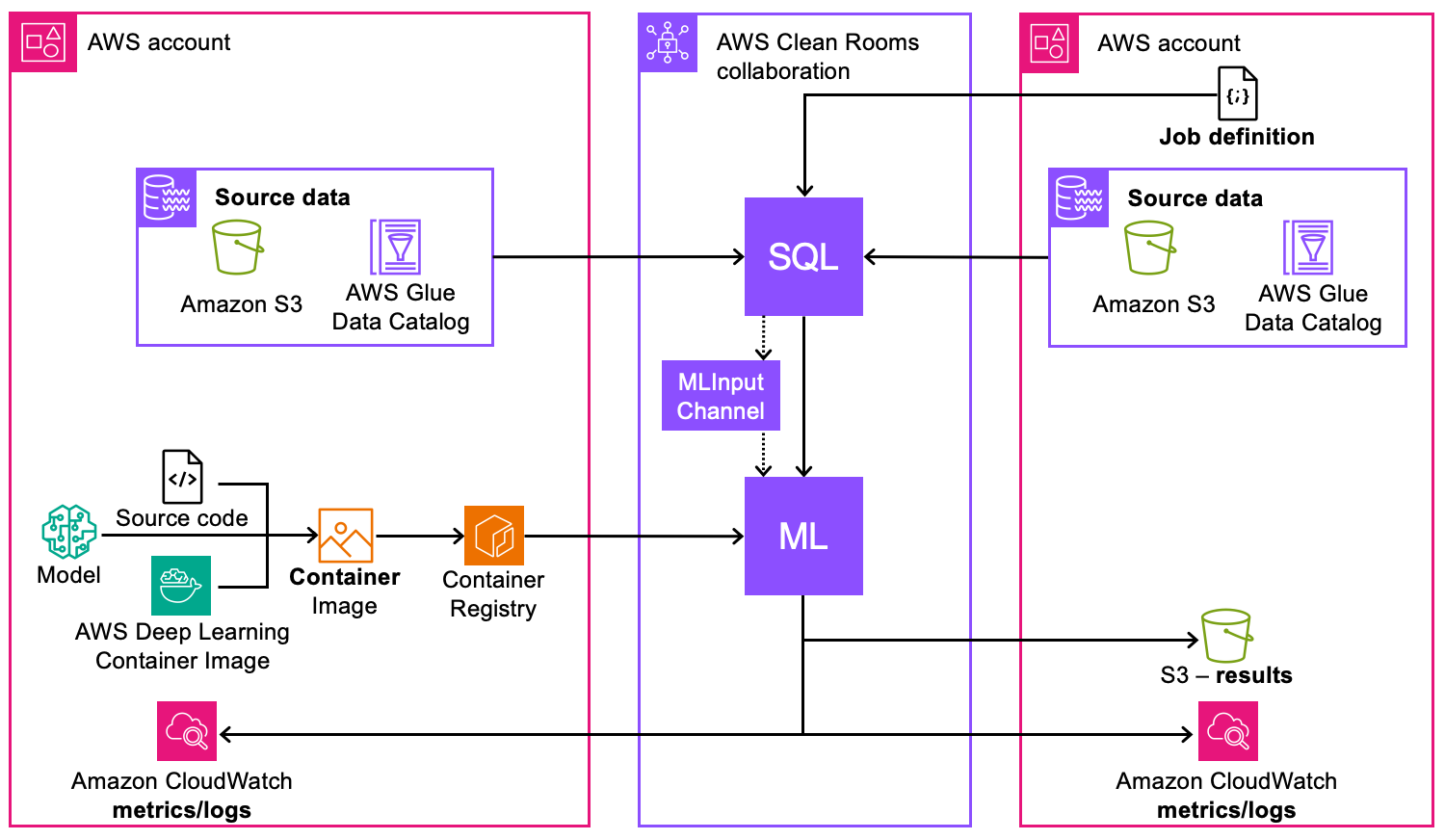
다음은 Clean Rooms ML에서 사용자 지정 ML 모델링이 작동하는 방식입니다.
-
데이터 소스 구성
-
소스 데이터는 Amazon S3 카탈로그, AWS Glue Data Catalog또는 Snowflake에 저장할 수 있습니다.
-
AWS Glue Data Catalog 는 구성 및 카탈로그 작성에 사용됩니다.
-
여러의 데이터를 동일한 공동 작업 내에서 사용할 AWS 계정 수 있습니다.
-
-
SQL 쿼리 및 데이터 처리
-
SQL 쿼리는 소스 데이터에 액세스하고 처리하는 데 사용됩니다.
-
쿼리는 AWS Clean Rooms 공동 작업 경계 내에서 실행됩니다.
-
모델 훈련을 위해 ML 입력 채널로 데이터 피드 처리
-
-
ML 모델 개발
-
AWS 딥 러닝 컨테이너 이미지를 사용하여 모델의 소스 코드를 개발할 수 있습니다.
-
사용자 지정 컨테이너 이미지를 생성하여 Amazon Elastic Container Registry에 저장해야 합니다.
-
-
인프라 구성 요소
-
Amazon Elastic Container Registry는 ML 모델 컨테이너를 저장하고 관리합니다.
-
ML 처리는 보안 AWS Clean Rooms 협업 환경 내에서 이루어집니다.
-
-
모니터링 및 로깅
-
Amazon CloudWatch는 두 공동 작업에 지표와 로그를 제공합니다.
-
공동 작업에 AWS 계정 관련된에서 모니터링을 사용할 수 있습니다.
-
관련 당사자가 성능 지표 및 운영 로그에 액세스할 수 있음
-
-
결과 관리
-
결과에 대한 액세스는 공동 작업 권한에 따라 제어됩니다.
-
시작하기 전에 사용자 지정 ML 모델링 사전 조건 및 훈련 컨테이너에 대한 모델 작성 지침에서 자세한 내용을 참조하세요.
주제
