기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
대상 감성
대상 감성은 입력 문서에 있는 특정 개체(예: 브랜드 또는 제품)와 관련된 감성을 세밀하게 이해할 수 있게 합니다.
대상 감성과 감성의 차이는 출력 데이터의 세분화 수준입니다. 감성 분석은 각 입력 문서에 대한 지배적인 감성을 결정하지만 추가 분석을 위한 데이터는 제공하지 않습니다. 대상 감성 분석은 각 입력 문서의 특정 개체에 대한 개체 수준의 감성을 결정합니다. 결과 데이터를 분석하여 긍정적이거나 부정적인 피드백을 받는 특정 제품 및 서비스를 확인할 수 있습니다.
예를 들어, 일련의 레스토랑 리뷰에서 고객은 “타코가 맛있었고 직원들도 친절했습니다”라는 리뷰를 제공합니다. 이 리뷰를 분석한 결과 다음과 같은 결과가 나옵니다.
감성 분석은 각 레스토랑 리뷰의 전반적인 감성이 긍정적인지, 부정적인지, 중립적인지, 또는 복합적인 것인지 여부를 결정합니다. 이 예시에서는 전반적인 감성이 긍정적입니다.
대상 감성 분석은 고객이 리뷰에서 언급한 레스토랑의 항목 및 속성에 대한 감성을 결정합니다. 이 예시에서 고객은 “타코”와 “직원”에 대해 긍정적인 의견을 남겼습니다.
대상 감성은 각 분석 작업에 대해 다음과 같은 결과를 제공합니다.
문서에 언급된 개체의 ID.
-
각 개체 멘션에 대한 개체 유형 분류.
각 개체 멘션에 대한 감성 및 감성 점수.
단일 항목에 해당하는 멘션 그룹(공동 참조 그룹).
콘솔 또는 API를 사용하여 대상 감성 분석을 실행할 수 있습니다. 콘솔과 API는 대상 감성에 대한 실시간 분석 및 비동기 분석을 지원합니다.
Amazon Comprehend는 영어로 작성된 문서에 대한 대상 감성을 지원합니다.
자습서를 포함하여 대상 감성에 대한 자세한 내용은 AWS 기계 학습 블로그의 Amazon Comprehend 대상 감성을 사용하여 텍스트로 세분화된 감성 추출
개체 유형
대상 감성은 다음 개체 유형을 식별합니다. 개체가 다른 범주에 속하지 않는 경우 개체 유형을 기타로 지정합니다. 출력 파일에 언급된 각 개체에는 "Type": "PERSON" 같은 개체 유형이 포함됩니다.
| 개체 유형 | 정의 |
|---|---|
| 개인 | 개인, 사람 그룹, 별명, 가상 인물, 동물 이름 등을 예로 들 수 있습니다. |
| 위치 | 국가, 도시, 주, 주소, 지질 구조, 수역, 자연 명소, 천문학적 위치 등의 지리적 위치입니다. |
| 조직 | 예로는 정부, 기업, 스포츠 팀, 종교 등이 있습니다. |
| 시설 | 건물, 공항, 고속도로, 교량 및 기타 영구적인 인공 구조물 및 부동산 개선입니다. |
| 브랜드 | 특정 상업용 품목 또는 제품 라인의 조직, 그룹 또는 생산자입니다. |
| 상업_품목 | 차량 및 단 하나의 품목만 생산된 대형 상품을 포함한 모든 비제네릭 구매 또는 구매 가능 품목입니다. |
| 영화 | 영화 또는 TV 프로그램입니다. 개체는 전체 이름, 닉네임 또는 자막일 수 있습니다. |
| 음악 | 노래 전체 또는 일부입니다. 또한 앨범이나 앤솔로지와 같은 개별 음악 창작물의 컬렉션도 포함됩니다. |
| 도서 | 전문적으로 출판되거나 자체 출판된 책입니다. |
| 소프트웨어 | 공식적으로 출시된 소프트웨어 제품입니다. |
| 게임 | 비디오 게임, 보드 게임, 일반 게임 또는 스포츠와 같은 게임입니다. |
| 개인_호칭 | 공식 직함 및 경칭(예: 사장, 박사, 의사)입니다. |
| 이벤트 | 예로는 축제, 콘서트, 선거, 전쟁, 컨퍼런스, 홍보 행사 등이 있습니다. |
| 날짜 | 구체적이든, 일반적이든, 절대적이든, 상대적이든 관계없이 날짜 또는 시간에 대한 모든 참조입니다. |
| 수량 | 모든 측정값과 단위(통화, 백분율, 숫자, 바이트 등)입니다. |
| 속성 | 제품의 “품질”, 휴대폰의 “가격” 또는 CPU의 “속도”와 같은 개체의 속성, 특징 또는 특성입니다. |
| 기타 | 다른 범주에 속하지 않는 개체입니다. |
공동 참조 그룹
대상 감성은 각 입력 문서에서 상호 참조 그룹을 식별합니다. 공동 참조 그룹은 문서 내 하나의 실제 개체에 해당하는 멘션 그룹입니다.
다음 고객 리뷰 예제에서 “spa”는 FACILITY 개체 유형을 가진 개체입니다. 개체에는 대명사(“it”)로 두 개의 추가 멘션이 있습니다.

출력 파일 구성
대상 감성 분석 작업은 JSON 텍스트 출력 파일을 생성합니다. 파일에는 각 입력 문서에 대해 하나의 JSON 객체가 포함되어 있습니다. 각 JSON 객체는 다음 필드를 포함합니다.
-
개체 — 문서에 있는 개체의 배열입니다.
-
파일 — 입력 문서의 파일 이름입니다.
-
줄 — 입력 파일이 한 줄에 한 문서인 경우, 개체에는 파일에 있는 문서의 줄 번호가 포함됩니다.
참고
대상 감성이 입력 텍스트의 어떤 항목도 식별하지 못하는 경우 개체 결과로 빈 배열을 반환합니다.
다음 예제는 3줄의 입력이 포함된 입력 파일의 개체를 보여줍니다. 입력 형식은 ONE_DOC_PER_LINE이므로 각 입력 줄은 문서입니다.
{ "Entities":[
{entityA},
{entityB},
{entityC}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{ "Entities": [
{entityD},
{entityE}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{ "Entities": [
{entityF},
{entityG}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}개체 배열의 개체에는 문서에서 감지된 개체 멘션의 논리적 그룹(상호 참조 그룹이라고 함)이 포함됩니다. 각 개체의 전체 구조는 다음과 같습니다.
{"DescriptiveMentionIndex": [0],
"Mentions": [
{mentionD},
{mentionE}
]
} 개체에는 다음과 같은 필드가 있습니다.
-
멘션 — 문서에 있는 개체에 대한 멘션 배열입니다. 배열은 상호 참조 그룹을 나타냅니다. 예제는 공동 참조 그룹 단원을 참조하세요. 멘션 배열의 멘션 순서는 문서 내 위치(오프셋)의 순서입니다. 각 멘션에는 해당 멘션의 감성 점수와 그룹 점수가 포함됩니다. 그룹 점수는 이러한 멘션이 동일한 개체에 속한다는 신뢰도를 나타냅니다.
-
DescriptiveMentionIndex — 개체 그룹에 가장 적합한 이름을 제공하는 멘션 배열에 있는 하나 이상의 인덱스입니다. 예를 들어, 개체에는 텍스트 값이 "ABC Hotel," “ABC Hotel,” 및 “it”인 멘션이 세 개 있을 수 있습니다. 가장 좋은 이름은 DescriptiveMentionIndex 값이 [0,1]인 “ABC Hotel”입니다.
각 멘션에는 다음 필드가 포함됩니다.
-
시작오프셋 — 멘션이 시작되는 문서 텍스트의 오프셋입니다.
-
종료오프셋 — 문서 텍스트에서 멘션이 끝나는 지점의 오프셋입니다.
그룹점수 — 그룹에 언급된 모든 개체가 동일한 개체와 관련되어 있다는 신뢰도입니다.
텍스트 — 개체를 식별하는 문서 내의 텍스트입니다.
유형 – 개체의 유형입니다. Amazon Comprehend는 다양한 개체 유형을 지원합니다.
점수 — 개체가 관련성이 있다는 신뢰도를 모델링합니다. 값 범위는 0에서 1까지입니다. 여기서 1은 가장 높은 신뢰도입니다.
멘션감성 — 멘션에 대한 감성 및 감성 점수를 포함합니다.
감성 — 멘션의 감성입니다. 값에는 긍정적, 중립적, 부정적, 혼합이 포함됩니다.
감성점수 — 가능한 각 감성에 대한 모델 신뢰도를 제공합니다. 값 범위는 0에서 1까지입니다. 여기서 1은 가장 높은 신뢰도입니다.
감성 값의 의미는 다음과 같습니다.
-
긍정적 — 개체 멘션이 긍정적인 감성을 표현합니다.
-
부정적 — 개체 멘션이 부정적인 감성을 표현합니다.
-
혼합 — 개체 멘션이 긍정적인 감성과 부정적인 감성을 모두 표현합니다.
-
중립 — 개체 멘션이 긍정적이거나 부정적인 감성을 표현하지 않습니다.
다음 예제에서는 입력 문서에서 개체의 멘션이 하나뿐이므로 DescriptiveMentionIndex는 0(멘션 배열의 첫 번째 멘션)이 됩니다. 식별된 개체는 이름이 “I”인 PERSON입니다. 감성 점수는 중립입니다.
{"Entities":[ { "DescriptiveMentionIndex": [0], "Mentions": [ { "BeginOffset": 0, "EndOffset": 1, "Score": 0.999997, "GroupScore": 1, "Text": "I", "Type": "PERSON", "MentionSentiment": { "Sentiment": "NEUTRAL", "SentimentScore": { "Mixed": 0, "Negative": 0, "Neutral": 1, "Positive": 0 } } } ] } ], "File": "Input.txt", "Line": 0 }
콘솔을 사용한 실시간 분석
Amazon Comprehend 콘솔을 사용하여 실시간으로 대상 감성을 실행할 수 있습니다. 샘플 텍스트를 사용하거나 직접 입력한 텍스트를 입력 텍스트 상자에 붙여넣은 다음 분석을 선택합니다.
인사이트 패널의 콘솔에는 대상 감성 분석의 세 가지 보기가 표시됩니다.
-
분석된 텍스트 — 분석된 텍스트를 표시하고 각 항목에 밑줄을 긋습니다. 밑줄 색상은 분석에서 개체에 할당한 감성 값(긍정적, 중립적, 부정적 또는 혼합)을 나타냅니다. 콘솔에서 분석되는 텍스트 상자 오른쪽 위 모서리에 색상 매핑을 표시합니다. 개체 위에 커서를 놓으면 콘솔에 해당 개체에 대한 분석 값(개체 유형, 감성 점수)이 포함된 팝업 패널이 표시됩니다.
-
결과 — 텍스트에서 식별된 각 개체 멘션의 행이 포함된 표를 표시합니다. 표에는 각 개체에 대해 개체 및 개체 점수가 표시됩니다. 이 행에는 기본 감성과 각 감성 값의 점수도 포함됩니다. 공동 참조 그룹으로 알려진 동일한 개체에 대한 멘션이 여러 개 있는 경우 표에는 이러한 멘션이 기본 개체와 관련된 축소 가능한 행 집합으로 표시됩니다.
결과 표의 개체 행을 마우스로 가리키면 콘솔이 분석된 텍스트 패널에서 해당 개체 멘션을 강조 표시합니다.
-
애플리케이션 통합 — API 요청의 파라미터 값과 API 응답에서 반환된 JSON 객체의 구조를 표시합니다. JSON 객체의 필드에 대한 설명은 출력 파일 구성을 참조하세요.
콘솔 실시간 분석 예제
이 예제에서는 콘솔에서 제공하는 기본 입력 텍스트인 다음 텍스트를 입력으로 사용합니다.
Hello Zhang Wei, I am John. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000. Customer feedback for Sunshine Spa, 123 Main St, Anywhere. Send comments to Alice at sunspa@mail.com. I enjoyed visiting the spa. It was very comfortable but it was also very expensive. The amenities were ok but the service made the spa a great experience.
분석된 텍스트 패널에는 이 예제에 대한 다음 출력이 표시됩니다. 텍스트를 마우스로 Zhang Wei 텍스트를 가리키면 이 개체에 대한 팝업 패널이 표시됩니다.
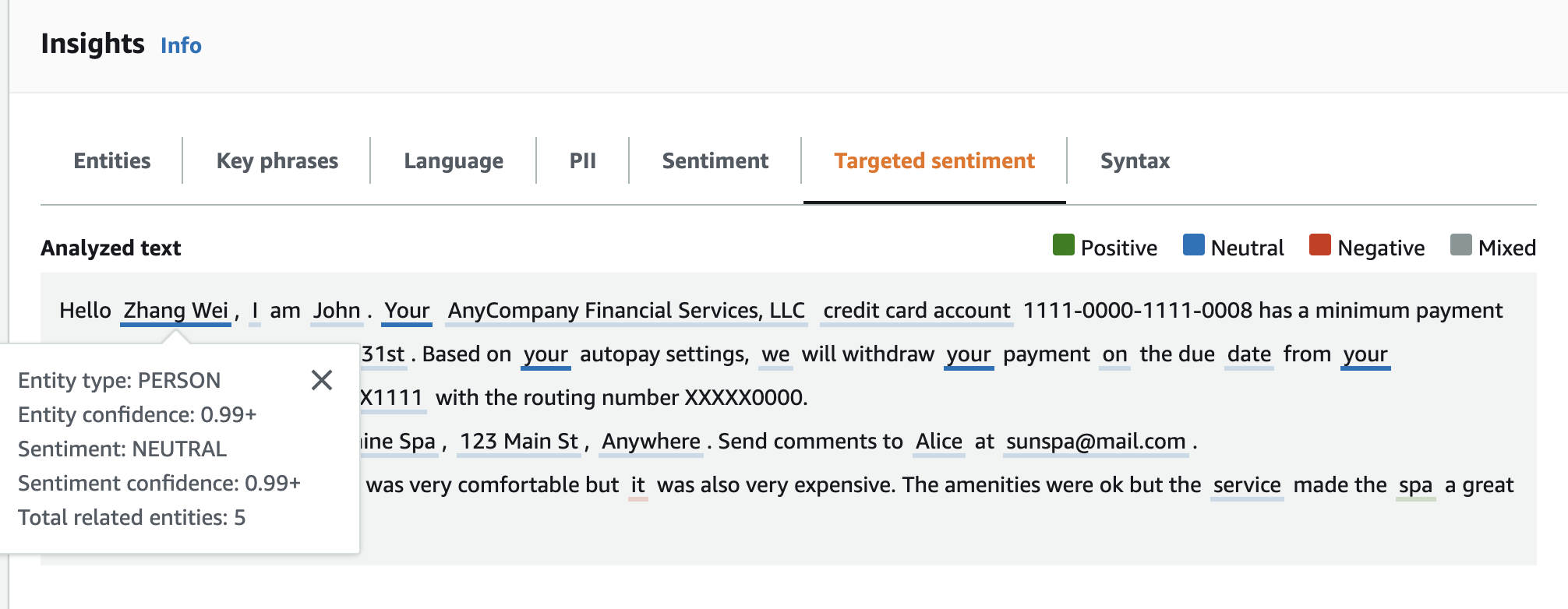
결과 표는 개체 점수, 기본 감성, 각 감성 점수를 포함하여 각 항목에 대한 추가 세부 정보를 제공합니다.
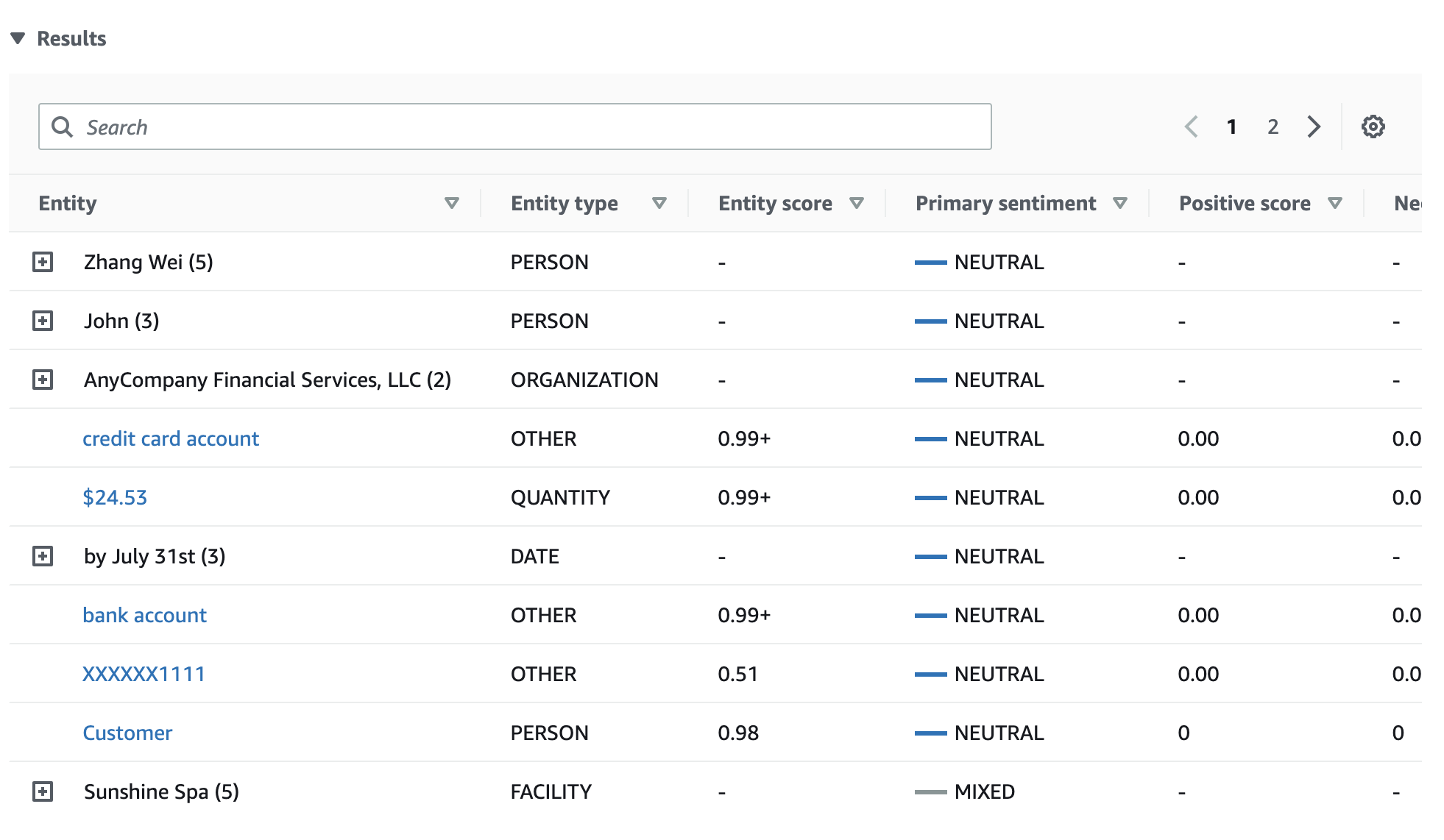
이 예제에서 대상 감성 분석은 입력 텍스트의 your라는 각 멘션이 Zhang Wei라는 개인 개체를 언급하는 것임을 인식합니다. 콘솔은 이러한 멘션을 기본 개체와 관련된 접을 수 있는 행 집합으로 표시합니다.

애플리케이션 통합 패널에는 DetectTargetedSentiment API가 생성하는 JSON 객체가 표시됩니다. 자세한 예는 다음 섹션을 참조하세요.
대상 감성 출력 예제
다음 예제에서는 대상 감성 분석 작업의 출력 파일을 보여줍니다. 입력 파일은 세 개의 간단한 문서로 구성되어 있습니다.
The burger was very flavorful and the burger bun was excellent. However, customer service was slow. My burger was good, and it was warm. The burger had plenty of toppings. The burger was cooked perfectly but it was cold. The service was OK.
이 입력 파일의 대상 감성 분석은 다음과 같은 결과를 생성합니다.
{"Entities":[
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 0.999991,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0,
"Positive": 1
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 38,
"EndOffset": 44,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000005,
"Negative": 0.000005,
"Neutral": 0.999591,
"Positive": 0.000398
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 45,
"EndOffset": 48,
"Score": 0.961575,
"GroupScore": 1,
"Text": "bun",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000327,
"Negative": 0.000286,
"Neutral": 0.050269,
"Positive": 0.949118
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 73,
"EndOffset": 89,
"Score": 0.999988,
"GroupScore": 1,
"Text": "customer service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0.000001,
"Negative": 0.999976,
"Neutral": 0.000017,
"Positive": 0.000006
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.99995,
"GroupScore": 1,
"Text": "My",
"Type": "PERSON",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0,
2
],
"Mentions": [
{
"BeginOffset": 3,
"EndOffset": 9,
"Score": 0.999999,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000002,
"Negative": 0.000001,
"Neutral": 0.000003,
"Positive": 0.999994
}
}
},
{
"BeginOffset": 24,
"EndOffset": 26,
"Score": 0.999756,
"GroupScore": 0.999314,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.000003,
"Neutral": 0.000006,
"Positive": 0.999991
}
}
},
{
"BeginOffset": 41,
"EndOffset": 47,
"Score": 1,
"GroupScore": 0.531342,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000215,
"Negative": 0.000094,
"Neutral": 0.00008,
"Positive": 0.999611
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 52,
"EndOffset": 58,
"Score": 0.965462,
"GroupScore": 1,
"Text": "plenty",
"Type": "QUANTITY",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 62,
"EndOffset": 70,
"Score": 0.998353,
"GroupScore": 1,
"Text": "toppings",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0.999964,
"Positive": 0.000036
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.001515,
"Negative": 0.000822,
"Neutral": 0.000243,
"Positive": 0.99742
}
}
},
{
"BeginOffset": 36,
"EndOffset": 38,
"Score": 0.999843,
"GroupScore": 0.999661,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.999996,
"Neutral": 0.000004,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 53,
"EndOffset": 60,
"Score": 1,
"GroupScore": 1,
"Text": "service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000033,
"Negative": 0.000089,
"Neutral": 0.993325,
"Positive": 0.006553
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}
}