기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
사후 대응 인사이트 보기
인사이트 내에서 Amazon RDS 리소스의 이상 현상을 확인할 수 있습니다. 사후 대응 인사이트 페이지의 집계된 지표 섹션에서 해당 타임라인과 함께 이상 항목 목록을 볼 수 있습니다. 이상 항목과 관련된 로그 그룹 및 이벤트에 대한 정보를 표시하는 섹션도 있습니다. 사후 대응 인사이트의 인과 변칙 각각에는 이상 항목에 대한 세부 정보가 포함된 해당 페이지가 있습니다.
RDS 사후 대응 이상 항목에 대한 세부 분석 보기
이 단계에서는 이상 항목을 자세히 분석하여 Amazon RDS DB 인스턴스에 대한 자세한 분석 및 권장 사항을 확인하십시오.
세부 분석은 성능 개선 도우미가 활성화된 Amazon RDS DB 인스턴스에서만 사용할 수 있습니다.
이상 항목 세부 정보 페이지를 자세히 살펴보려면
-
인사이트 페이지에서 리소스 유형이 AWS/RDS로 집계된 지표 찾으십시오.
-
세부 정보 보기를 선택합니다.
이상 항목의 세부 정보 페이지가 나타납니다. 제목은 데이터베이스 성능 이상 현상으로 시작하며 리소스 이름이 나타납니다. 콘솔은 이상 항목 발생 시기에 관계없이 심각도가 가장 높은 이상 항목을 기본값으로 설정합니다.
-
(선택 사항) 여러 리소스가 영향을 받는 경우 페이지 상단의 목록에서 다른 리소스를 선택합니다.
다음에서 세부 정보 페이지의 구성 요소에 대한 설명을 확인할 수 있습니다.
리소스 개요
세부정보 페이지의 상단 섹션은 리소스 개요입니다. 이 섹션에서는 Amazon RDS DB 인스턴스에서 발생하는 성능 이상에 대해 요약합니다.
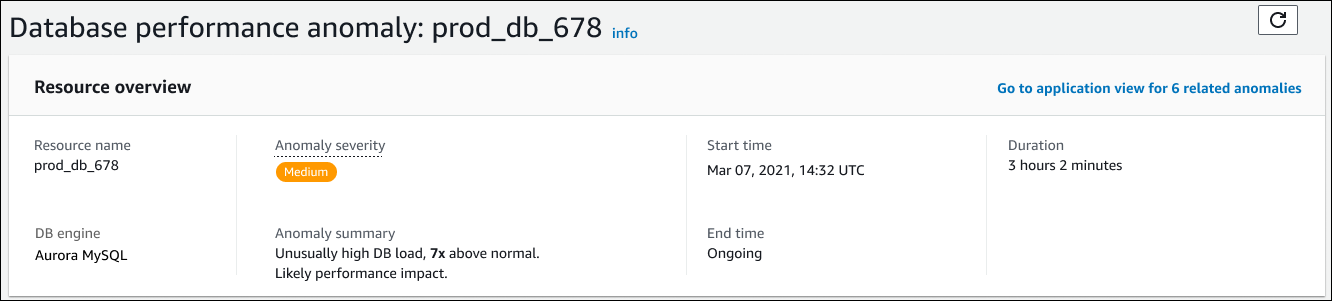
이 섹션은 다음 필드를 포함합니다.
-
리소스 이름 - 이상 현상이 발생한 DB 인스턴스의 이름입니다. 이 예시에서 리소스의 이름은 prod_db_678입니다.
-
DB 엔진 - 이상 현상이 발생한 DB 인스턴스의 이름입니다. 이 예시에서 엔진은 Aurora MySQL입니다.
-
이상 심각도 - 이상 징후가 인스턴스에 미치는 부정적인 영향을 측정한 것입니다. 가능한 심각도는 높음, 보통 및 낮음입니다.
-
이상 항목 요약 - 문제에 대한 간략한 요약입니다. 일반적인 요약은 비정상적으로 높은 DB 로드입니다.
-
시작 시간 및 종료 시간 - 이상 현상이 시작되고 종료된 시간입니다. 종료 시간이 진행 중이면, 이상 현상이 계속 발생하고 있는 것입니다.
-
지속 시간 - 이상 동작의 지속 시간입니다. 이 예시에서는 이상 현상이 진행 중이며 3시간 2분 동안 발생했습니다.
기본 지표
기본 지표 섹션에는 인사이트 내의 최상위 이상 항목인 인과적 이상 항목이 요약되어 있습니다. 인과적 이상은 DB 인스턴스에서 발생하는 일반적인 문제라고 생각하면 됩니다.
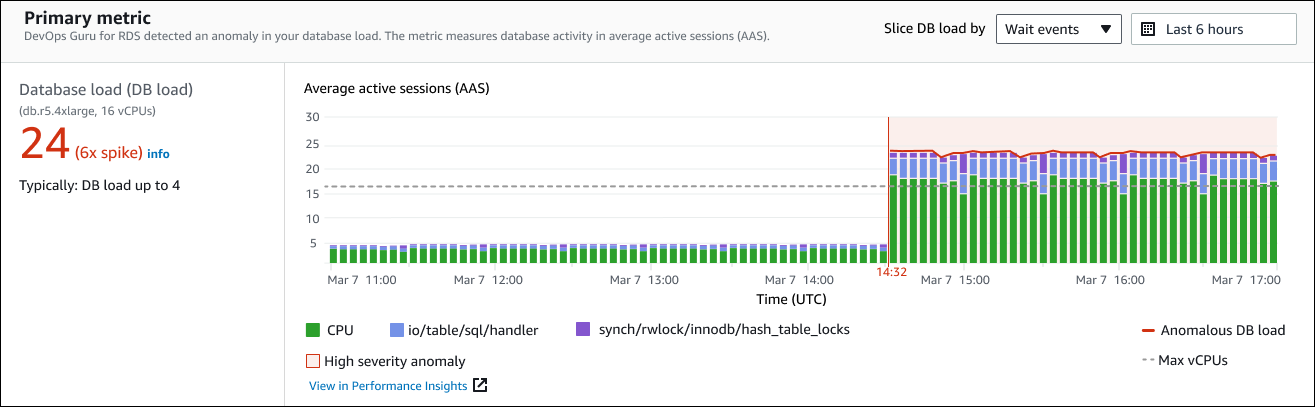
왼쪽 패널은 이 문제에 대한 자세한 내용을 제공합니다. 이 예시의 요약에는 다음 정보가 포함됩니다.
-
데이터베이스 로드(DB 로드) - 이상 현상을 데이터베이스 로드 문제로 분류한 것입니다. 성능 개선 도우미의 해당 지표는
DBLoad입니다. 이 지표는 Amazon CloudWatch에도 게시됩니다. -
db.r5.4xlarge - DB 인스턴스 클래스입니다. vCPU 수(이 예시에서는 16개)는 평균 활성 세션(AAS) 차트의 점선에 해당합니다.
-
24(6x 스파이크) - 인사이트에 보고된 시간 간격 동안 평균 활성 세션(AAS)으로 측정한 DB 부하입니다. 따라서 이상 현상이 발생한 기간 중 특정 시점에 데이터베이스에서 평균 24개의 세션이 활성 상태였습니다. 이 인스턴스의 DB 로드는 일반 DB 로드의 6배입니다.
-
일반적으로 DB 로드 최대 4개 - 일반적인 워크로드 중 DB 부하의 기준선(AAS로 측정됨)입니다. 값 4는 정상 운영 중에 데이터베이스에서 특정 시점에 활성 상태인 세션이 평균 4개 이하임을 의미합니다.
로드 차트는 기본적으로 대기 이벤트를 기준으로 분할됩니다. 즉, 차트의 각 막대에서 가장 큰 색상 영역은 전체 DB 로드에 가장 많이 기여하는 대기 이벤트를 나타냅니다. 차트에는 문제가 시작된 시간(빨간색)이 표시됩니다. 막대에서 가장 많은 공간을 차지하는 대기 이벤트에 주의를 기울이십시오.
-
CPU -
IO:wait/io/sql/table/handler
이 Aurora MySQL 데이터베이스에서 이전 대기 이벤트가 정상보다 많이 나타납니다. Amazon Aurora의 대기 이벤트를 사용해 성능을 조정하는 자세한 방법은 Amazon Aurora 사용 설명서의 Aurora MySQL 대기 이벤트를 사용한 튜닝과 Aurora PostgreSQL 대기 이벤트를 사용한 튜닝을 참조하십시오. RDS for PostgreSQL에서 대기 이벤트를 사용하여 성능을 조정하는 방법을 알아보려면 Amazon RDS 사용 설명서의 RDS for PostgreSQL의 대기 이벤트를 사용한 튜닝을 참조하십시오.
관련 지표
관련 지표 섹션에는 인과적 이상 항목 내에서 구체적으로 발견된 문맥적 이상이 나열되어 있습니다. 이러한 결과는 성능 문제에 대한 추가 정보를 제공합니다.
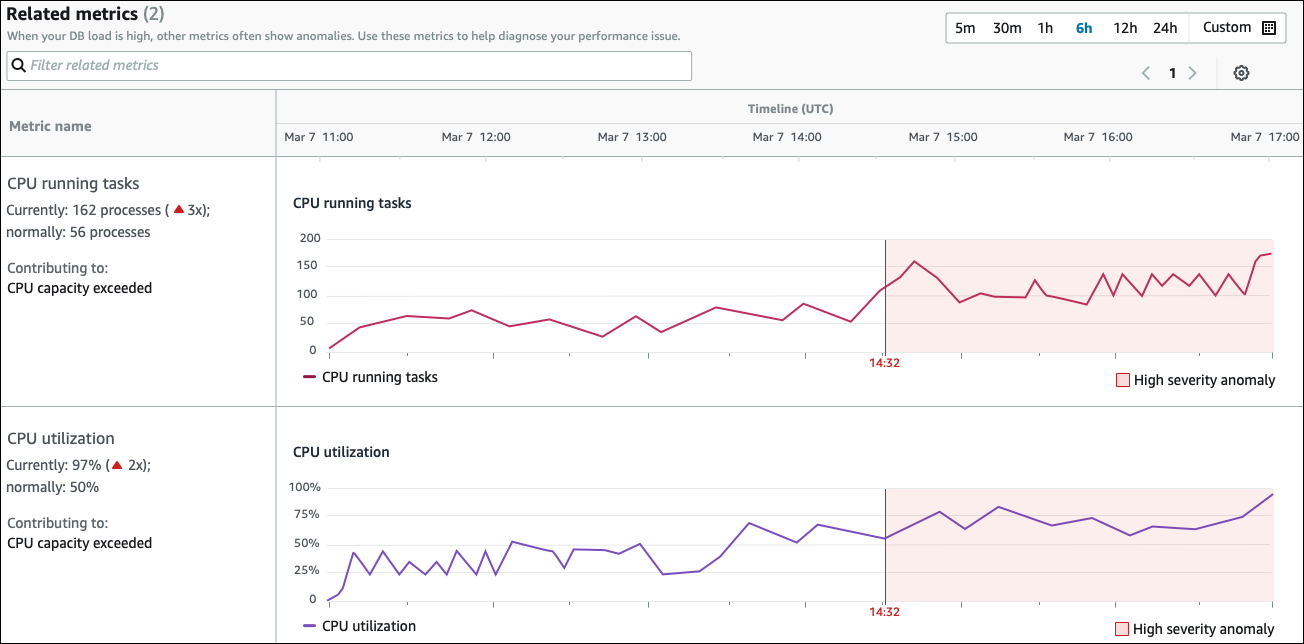
관련 지표 테이블에는 다음 두 개의 열이 있습니다: 지표 이름 및 타임라인 (UTC). 테이블의 모든 행은 특정 지표에 해당합니다.
모든 행의 첫 번째 열에는 다음과 같은 정보가 있습니다.
-
이름– 지표의 이름입니다. 첫 번째 행은 지표를 CPU 실행 작업으로 식별합니다. -
현재 - 지표의 현재 값입니다. 첫 번째 행의 현재 값은 162개 프로세스(3x) 입니다.
-
일반적 - 이 데이터베이스가 정상적으로 작동할 때 적용되는 이 지표의 기준입니다. DevOps Guru for RDS는 1주일 동안의 95번째 백분위 값으로 기준선을 계산합니다. 첫 번째 행은 CPU에서 일반적으로 56개의 프로세스가 실행되고 있음을 나타냅니다.
-
기여 - 이 지표와 관련된 조사 결과입니다. 첫 번째 행에서 CPU 실행 중인 작업 지표는 CPU 용량 초과 이상과 연관되어 있습니다.
타임라인 열에는 지표의 선형 차트가 표시됩니다. 음영 영역은 DevOps Guru for RDS가 해당 결과의 심각도를 높음으로 지정한 시간 간격을 나타냅니다.
분석 및 권장 사항
인과적 이상은 전체 문제를 설명하는 반면, 문맥적 이상은 조사가 필요한 특정 결과를 설명합니다. 각 조사 결과는 일련의 관련 지표에 해당합니다.
분석 및 권장 사항 섹션의 다음 예시에서는 DB 로드가 높은 이상 현상에 대한 두 가지 결과가 있습니다.
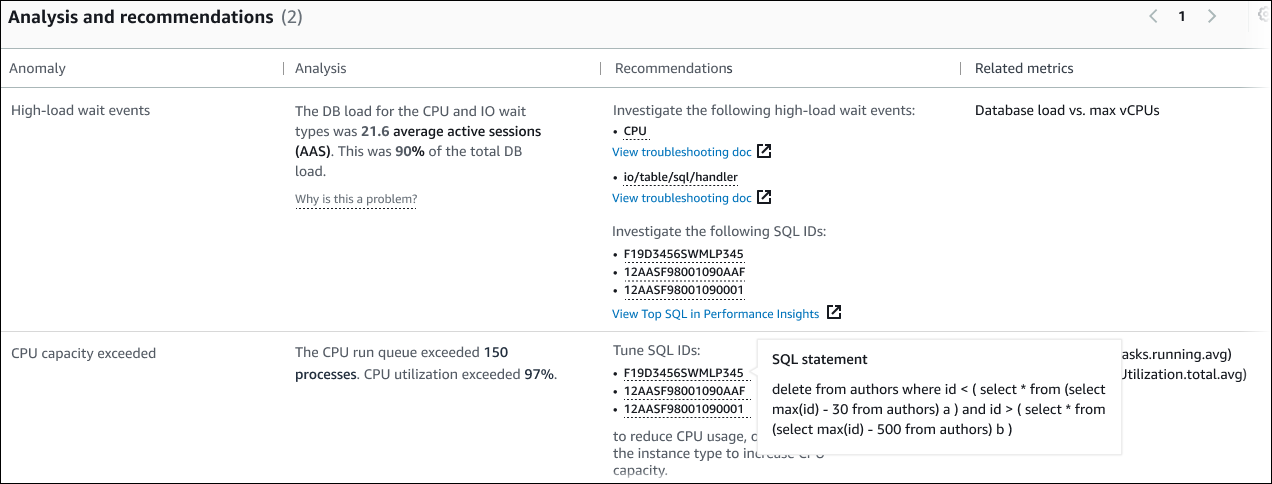
이 표에는 다음과 같은 열이 있습니다.
-
이상 항목 - 이 문맥적 이상 현상에 대한 일반적인 설명입니다. 이 예시에서 첫 번째 이상은 로드가 높은 대기 이벤트이고, 두 번째 이상은 CPU 용량 초과입니다.
-
분석 - 이상 현상에 대한 자세한 설명입니다.
첫 번째 이상 사례에서는 세 가지 대기 유형이 DB 로드의 90%를 차지합니다. 두 번째 이상 사례에서는 CPU 실행 대기열이 150을 초과했습니다. 즉, 주어진 시간에 150개 이상의 세션이 CPU 시간을 기다리고 있다는 말입니다. CPU 사용률이 97%를 넘었다는 것은, 문제가 발생한 기간 동안 CPU가 사용 중인 시간의 97%를 초과했음을 의미합니다. 따라서 평균 150개의 세션이 CPU에서 실행되기를 기다리는 동안 CPU는 거의 계속 점유되고 있었습니다.
-
권장 사항 - 이상 현상에 대한 권장 사용자 대응입니다.
첫 번째 이상 현상에서 DevOps Guru for RDS는 대기 이벤트
cpu및io/table/sql/handler조사를 권장합니다. 이러한 이벤트를 기반으로 데이터베이스 성능을 조정하는 방법을 알아보려면 Amazon Aurora 사용 설명서의 cpu 및 io/table/sql/handler를 참조하십시오.두 번째 이상 현상에서 DevOps Guru for RDS는 세 개의 SQL 명령문을 조정하여 CPU 사용량을 줄일 것을 권장합니다. 링크 위로 마우스를 가져가면 SQL 텍스트를 볼 수 있습니다.
-
관련 지표 - 이상 현상에 대한 구체적인 측정치를 제공하는 지표입니다. 이러한 지표에 대한 자세한 내용은 Amazon Aurora 사용 설명서의 Amazon Aurora 지표 참조 또는 Amazon RDS 사용 설명서의 Amazon RDS 지표 참조를 확인하십시오.
첫 번째 이상 상황에서 DevOps Guru for RDS는 DB 로드를 인스턴스의 최대 CPU와 비교할 것을 권장합니다. 두 번째 이상 상황의 경우 CPU 실행 대기열, CPU 사용률, SQL 실행 속도를 살펴보는 것이 좋습니다.
