기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon DocumentDB에 복제본 세트로 연결
Amazon DocumentDB(MongoDB 호환)를 사용하여 개발할 때는 클러스터를 복제본 세트로 연결하고 드라이버의 내장된 읽기 환경설정 기능을 사용하여 복제본 인스턴스에 읽기를 배포하는 것이 좋습니다. 이 섹션에서는 이것이 의미하는 바에 대해 자세히 설명하고, Python용 SDK를 예로 들어 복제본 세트로 Amazon DocumentDB 클러스터에 연결하는 방법을 설명합니다.
Amazon DocumentDB에는 클러스터에 연결하는 데 사용할 수 있는 세 가지 엔드포인트가 있습니다:
-
클러스터 엔드포인트
-
리더 엔드포인트
-
인스턴스 엔드포인트
대부분의 경우 Amazon DocumentDB에 연결할 때 클러스터 엔드포인트을 사용하는 것이 좋습니다. 이는 다음 다이어그램과 같이 클러스터의 기본 인스턴스를 가리키는 CNAME입니다.
SSH 터널을 사용하는 경우 클러스터 엔드포인트를 사용하여 클러스터에 연결하고, 오류가 발생하므로 복제본 집합 모드(예: 연결 문자열에 replicaSet=rs0 지정)로 연결을 시도하지 않는 것이 좋습니다.
참고
Amazon DocumentDB 엔드포인트에 대한 자세한 내용은 Amazon DocumentDB 엔드포인트 섹션을 참조하세요.
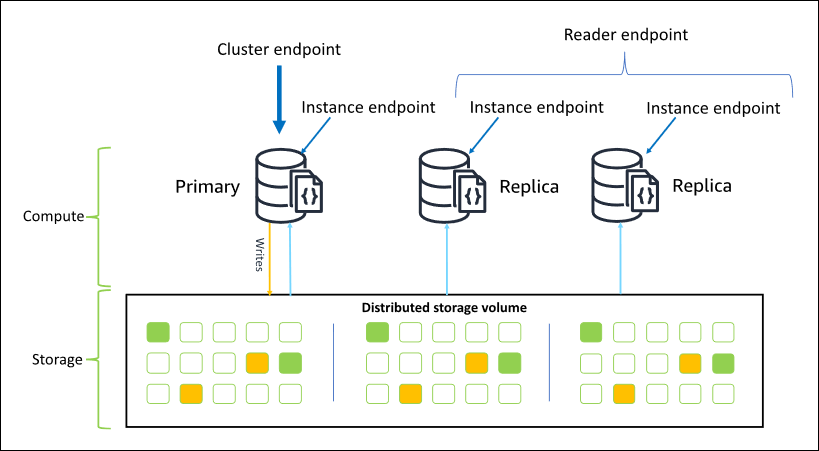
클러스터 엔드포인트를 사용하여 복제본 세트 모드에서 클러스터에 연결할 수 있습니다. 그런 다음 내장된 읽기 기본 설정 드라이버 기능을 사용할 수 있습니다. 다음 예제에서 /?replicaSet=rs0을 지정하면 복제본 세트로 연결하려는 SDK를 나타냅니다. /?replicaSet=rs0'을 생략하면 클라이언트는 모든 요청을 클러스터 엔드포인트, 즉 기본 인스턴스로 라우팅합니다.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
복제본 세트로 연결하면 클러스터에서 인스턴스를 추가하거나 제거할 때를 포함하여 SDK가 클러스터 지형을 자동으로 검색할 수 있다는 장점이 있습니다. 그런 다음 읽기 요청을 복제본 인스턴스로 라우팅하여 클러스터를 보다 효율적으로 사용할 수 있습니다.
복제본 세트로 연결할 때 연결을 위해 readPreference를 지정할 수 있습니다. secondaryPreferred의 읽기 기본 설정을 지정하면 클라이언트는 읽기 쿼리를 복제본에 라우팅하고 쿼리를 기본 인스턴스에 씁니다(다음 다이어그램 참조). 이것은 클러스터 리소스를 더 잘 사용하는 것입니다. 자세한 내용은 읽기 기본 설정 옵션 섹션을 참조하십시오.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
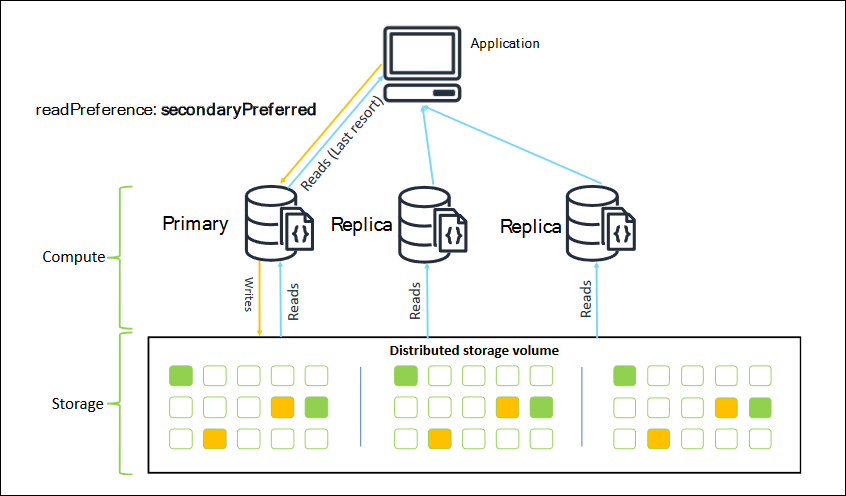
Amazon DocumentDB 복제본의 읽기는 결국 일치합니다. 기본 데이터에 기록된 순서와 동일한 순서로 데이터를 반환하며 50ms 미만의 복제 지연이 있는 경우가 많습니다. Amazon CloudWatch 지표 DBInstanceReplicaLag및 DBClusterReplicaLagMaximum를 사용하여 클러스터의 복제 지연을 모니터링할 수 있습니다. 자세한 내용은 CloudWatch를 사용하여 Amazon DocumentDB 모니터링 섹션을 참조하십시오.
기존의 단일 데이터베이스 아키텍처와 달리 Amazon DocumentDB는 스토리지와 컴퓨팅을 분리합니다. 이러한 최신 아키텍처를 고려할 때, 복제본 인스턴스에서 읽기 확장을 권장합니다. 복제본 인스턴스에 대한 읽기는 기본 인스턴스에서 복제되는 쓰기를 차단하지 않습니다. 클러스터에 최대 15개의 읽기 전용 복제본 인스턴스를 추가하고 초당 수백만 건의 읽기로 스케일 아웃할 수 있습니다.
복제본 세트로 연결하고 복제본에 읽기를 배포할 때 얻을 수 있는 주요 이점은 클러스터에서 애플리케이션에 사용할 수 있는 전체 리소스가 늘어난다는 것입니다. 모범 사례로 복제본 세트로 연결하는 것을 권장합니다. 또한 다음 시나리오에서 가장 일반적으로 권장됩니다:
-
기본에서 거의 100% CPU를 사용하고 있습니다.
-
버퍼 캐시 적중률이 거의 0입니다.
-
개별 인스턴스의 연결 또는 커서 한계에 도달합니다.
클러스터 인스턴스 크기를 확장하는 것은 옵션이며 경우에 따라 클러스터를 확장하는 가장 좋은 방법일 수 있습니다. 그러나 이미 클러스터에 있는 복제본을 더 잘 사용하는 방법도 고려해야 합니다. 이를 통해 더 큰 인스턴스 유형을 사용하는 비용을 늘리지 않고도 규모를 조정할 수 있습니다. 또한 CloudWatch 알람을 사용하여 이러한 제한(즉, CPUUtilization, DatabaseConnections, 및 BufferCacheHitRatio)을 모니터링하고 경고하여 리소스가 많이 사용되는 시기를 파악하는 것이 좋습니다.
자세한 내용은 다음 주제를 참조하세요.
클러스터 연결 사용
클러스터에서 모든 연결을 사용하는 시나리오를 고려하세요. 예를 들어, r5.2xlarge 인스턴스에는 4,500개의 연결(및 450개의 열려 있는 커서) 제한이 있습니다. 3-인스턴스 Amazon DocumentDB 클러스터를 생성하고 클러스터 끝점을 사용하여 기본 인스턴스에만 연결하는 경우 열린 연결 및 커서에 대한 클러스터 제한은 각각 4,500 및 450입니다. 컨테이너에서 작성하는 많은 작업자를 사용하는 애플리케이션을 작성하는 경우 이러한 제한에 도달할 수 있습니다. 컨테이너는 한 번에 많은 연결을 열고 클러스터를 포화시킵니다.
대신 복제본 세트로 Amazon DocumentDB 클러스터에 연결하고 읽기를 복제본 인스턴스에 분배할 수 있습니다. 그런 다음 클러스터에서 사용 가능한 연결 및 커서 수를 각각 13,500 및 1,350으로 세 배로 늘릴 수 있습니다. 클러스터에 인스턴스를 더 추가하면 읽기 워크로드에 대한 연결 및 커서 수가 증가합니다. 클러스터에 쓰기 위해 연결 수를 늘려야 하는 경우 인스턴스 크기를 늘리는 것이 좋습니다.
참고
large, xlarge 및 2xlarge 인스턴스에 대한 연결 수는 인스턴스 크기가 4,500개가 될 때까지 증가합니다. 4xlarge 인스턴스 이상의 경우 인스턴스당 최대 연결 수는 4,500개입니다. 인스턴스 유형별 제한에 대한 자세한 내용은 인스턴스 제한 섹션을 참조하세요.
일반적으로 secondary 읽기 환경 설정을 사용하여 클러스터에 연결하지 않는 것이 좋습니다. 클러스터에 복제본 인스턴스가 없으면 읽기가 실패하기 때문입니다. 예를 들어, 기본 복제본과 복제본이 하나인 두 개의 인스턴스 Amazon DocumentDB 클러스터가 있다고 가정합니다. 복제본에 문제가 있으면 secondary로 설정된 연결 풀의 읽기 요청은 실패합니다. secondaryPreferred는 클라이언트가 연결하기에 적합한 복제본 인스턴스를 찾을 수 없는 경우 기본 인스턴스로 돌아가서 읽을 수 있다는 장점이 있습니다.
다중 연결 풀
일부 시나리오에서는 애플리케이션의 읽기가 쓰기 후 읽기 일관성을 가져야 하며, 이는 Amazon DocumentDB의 기본 인스턴스에서만 제공될 수 있습니다. 이러한 시나리오에서는 두 개의 클라이언트 연결 풀을 작성할 수 있습니다. 하나는 쓰기용이고 다른 하나는 쓰기 후 읽기 일관성이 필요한 읽기용입니다. 이를 위한 코드는 다음과 같을 것입니다.
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
다른 옵션은 단일 연결 풀을 작성하고 주어진 컬렉션에 대한 읽기 환경 설정을 덮어쓰는 것입니다.
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
요약
클러스터의 리소스를 더 잘 사용하려면 복제본 세트 모드를 사용하여 클러스터에 연결하는 것이 좋습니다. 애플리케이션에 적합한 경우 읽기를 복제본 인스턴스에 분배하여 애플리케이션 읽기를 확장할 수 있습니다.
