기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon EMR on EC2 - 사용자 지정 지표 및 로그를 사용한 CloudWatch로 향상된 모니터링
개요
Amazon EMR은 강력하고 비용 효율적인 빅 데이터 처리 기능을 제공합니다. 성능 및 리소스 사용률을 극대화하려면 효과적인 모니터링이 필수적입니다. Amazon CloudWatch는 EMR 클러스터에 대한 포괄적인 관찰성을 제공하므로 지표와 로그를 실시간으로 추적할 수 있습니다. 이 문서에서는 다음을 수행하는 방법을 간략하게 설명합니다.
-
EMR on EC2 로그를 CloudWatch로 전송하도록 CloudWatch 에이전트 구성
-
분류를 통해 사용자 지정 하둡, YARN 및 HBase 지표 추가
-
기본 제공 대시보드를 통해 지표 모니터링
-
CloudWatch 로그 그룹을 통해 클러스터 로그 추적
사전 조건 및 배경
기본적으로 Amazon EMR은 추가 비용 없이 5분마다 CloudWatch에 기본 지표를 전송합니다. EMR 릴리스 7.0 이상에서는 CloudWatch 에이전트를 다음에 배포할 수 있습니다.
-
1분 간격으로 34개의 추가 세부 지표 수집(추가 요금 적용)
-
모든 클러스터 노드에서 지표 수집
-
CloudWatch로 전송하기 전에 프라이머리 노드의 데이터 집계
-
EMR 콘솔의 모니터링 탭 또는 CloudWatch 콘솔을 통해 지표에 액세스
EMR 7.1은 이러한 기능을 확장하므로 하둡, YARN 및 HBase 구성 요소에서 특수 지표를 캡처하도록 에이전트를 구성할 수 있습니다. Prometheus를 사용하는 환경의 경우 지표를 Amazon Managed Service for Prometheus로 전달할 수 있습니다.
로그에 대한 CloudWatch 에이전트 구성
CloudWatch에서 EMR 로그를 캡처하려면 수집할 로그 파일을 정의하는 cloudwatch-config.json 파일을 생성합니다.
cloudwatch-config.json
{ "agent": {"metrics_collection_interval":60,"logfile":"/var/log/emr-cluster-metrics/amazon-cloudwatch-agent/amazon-cloudwatch-agent.log","run_as_user":"****","omit_hostname":true}, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/mnt/var/log/hadoop-yarn/hadoop-yarn-resourcemanager-*", "log_group_name": "/emr/yarn/resourcemnger", "log_stream_name": "{instance_id}", "publish_multi_logs" : true }, { "file_path": "/var/log/hadoop-hdfs/hadoop-hdfs-namenode-*", "log_group_name": "/emr/hdfs/namenode", "log_stream_name": "{instance_id}", "publish_multi_logs" : true } ] } } } }
CloudWatch 에이전트 구성을 위한 부트스트랩 스크립트
사용자 지정 CloudWatch 구성을 EMR 노드에 적용하려면 설정으로 CloudWatch 에이전트를 다시 시작하는 부트스트랩 스크립트를 생성합니다. 이 스크립트는 클러스터 프로비저닝 후 에이전트가 특정 로그 수집 파라미터로 실행되도록 합니다.
부트스트랩 스크립트 생성
다음 콘텐츠를 사용하여 cloudwatch-agent-bootstrap.sh 파일을 생성합니다.
#!/bin/bash set -xe EMR_SECONDARY_BA_SCRIPT=$(cat << 'EOF' while true; do NODEPROVISIONSTATE=$(sed -n '/localInstance [{]/,/[}]/ {/nodeProvisionCheckinRecord [{]/,/[}]/ {/status:/ p}}' /emr/instance-controller/lib/info/job-flow-state.txt | awk '{ print $2 }') if [ "$NODEPROVISIONSTATE" == "SUCCESSFUL" ]; then sleep 10 echo "Running my post provision bootstrap" NODETYPE=$(cat /mnt/var/lib/instance-controller/extraInstanceData.json | jq -r '.instanceRole' | awk '{print tolower($0)}') # Copy config file on the instance sudo aws s3 cp s3://amzn-s3-demo-bucket1>/cloudwatch-config.json /etc/emr-cluster-metrics/amazon-cloudwatch-agent/conf/emr-amazon-cloudwatch-agent.json # Stop the current agent sudo /usr/bin/amazon-cloudwatch-agent-ctl -a stop # Start the agent with the created config file sudo /usr/bin/amazon-cloudwatch-agent-ctl -a fetch-config -s -m ec2 -c file:/etc/emr-cluster-metrics/amazon-cloudwatch-agent/conf/emr-amazon-cloudwatch-agent.json # Status CW Agent echo "Status CW Agent" sudo /usr/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status exit fi sleep 10 done EOF ) echo "${EMR_SECONDARY_BA_SCRIPT}" | tee -a /tmp/emr-secondary-ba.sh chmod u+x /tmp/emr-secondary-ba.sh /tmp/emr-secondary-ba.sh > /tmp/emr-secondary-ba.log 2>&1 & exit 0
중요 구성 참고 사항
중요
스크립트를 업로드하기 전에 <amzn-s3-demo-bucket1>를 이전 단계의 cloudwatch-config.json 파일을 저장한 S3 버킷의 실제 이름으로 바꿉니다. 이렇게 하면 부트스트랩 스크립트가 클러스터 초기화 중에 구성 파일을 검색할 수 있습니다.
이 부트스트랩 스크립트는 다음을 수행합니다.
-
노드 프로비저닝이 완료될 때까지 기다립니다.
-
사용자 지정 CloudWatch 구성 다운로드
-
실행 중인 CloudWatch 에이전트 중지
-
특정 구성으로 에이전트를 다시 시작합니다.
-
문제 해결을 위해 에이전트의 상태 로깅
하둡, YARN 및 HBase에 대한 사용자 지정 지표 분류
기본 CloudWatch 지표 외에도 EMR 클러스터 구성 요소에 대한 사용자 지정 애플리케이션별 지표를 구성하여 모니터링 기능을 향상시킬 수 있습니다. Amazon EMR의 구성 API는 수집하려는 지표를 정확하게 정의하는 유연한 방법을 제공합니다.
사용자 지정 지표 구성
다음 두 가지 방법으로 사용자 지정 지표 컬렉션을 구현할 수 있습니다.
-
새 클러스터에 대한 클러스터 생성 중
-
EMR 콘솔을 통한 기존 클러스터의 재구성
분류 파일 생성
분류 파일은 클러스터에서 수집해야 하는 특정 구성 요소 지표를 정의합니다. 다음은 사용자 지정 하둡 지표를 수집하기 위한 샘플 구조입니다.
[ { "Classification": "emr-metrics", "Configurations": [ { "Classification": "emr-hadoop-hdfs-datanode-metrics", "Properties": { "Hadoop:service=DataNode,name=DataNodeActivity-*": "DatanodeNetworkErrors,TotalReadTime,TotalWriteTime,BytesRead,BytesWritten,RemoteBytesRead,RemoteBytesWritten,ReadBlockOpNumOps,ReadBlockOpAvgTime,WriteBlockOpNumOps,WriteBlockOpAvgTime", "otel.metric.export.interval": "30000" } }, { "Classification": "emr-hadoop-yarn-nodemanager-metrics", "Properties": { "Hadoop:service=NodeManager,name=JvmMetrics": "MemNonHeapUsedM,MemNonHeapCommittedM,MemNonHeapMaxM,MemHeapUsedM,MemHeapCommittedM,MemHeapMaxM,MemMaxM", "Hadoop:service=NodeManager,name=NodeManagerMetrics": "ContainerCpuUtilization,NodeCpuUtilization,ContainersCompleted,ContainersFailed,ContainersKilled,ContainersLaunched,ContainersRolledBackOnFailure,ContainersRunning,ContainerUsedMemGB,ContainerUsedVMemGB,ContainerLaunchDurationNumOps,ContainerLaunchDurationAvgTime", "otel.metric.export.interval": "20000" } } ], "Properties": {} } ]
구현 단계
-
원하는 지표 분류를 사용하여 JSON 파일을 생성합니다.
-
모니터링 요구 사항에 따라 지표를 사용자 지정합니다.
-
파일을 저장하고 S3 버킷에 업로드합니다.
-
새 클러스터를 생성하거나 기존 클러스터를 재구성할 때이 파일을 참조하세요.
모범 사례
-
워크로드에 대한 의미 있는 인사이트를 제공하는 지표만 수집합니다.
-
모니터링 요구 사항에 따라 지표 수집 간격을 고려합니다.
-
각 구성 요소에 사용 가능한 지표의 전체 목록은 AWS 설명서를 검토하세요.
-
더 나은 조직을 위해 동일한 분류 내에서 관련 지표를 그룹화합니다.
이 접근 방식을 사용하면 특정 EMR 애플리케이션의 가장 중요한 지표에 모니터링을 집중할 수 있으므로 클러스터 성능에 대한 심층적인 가시성을 확보할 수 있습니다.
CloudWatch 통합을 사용하여 EMR 클러스터 배포
다음 단계에 따라 로그 및 사용자 지정 지표를 CloudWatch로 자동으로 전송하는 Amazon EMR 클러스터를 생성합니다.
1단계: CloudWatch 에이전트 활성화
AWS 관리 콘솔을 통해 EMR 클러스터를 생성하는 경우:
-
클러스터 생성 중에 애플리케이션 섹션으로 이동합니다.
-
기본 애플리케이션(하둡, Spark 등)의 확인란을 선택합니다.
-
스크롤하여 Amazon CloudWatch Agent 옵션을 찾아 선택합니다.
-
이렇게 하면 향상된 지표 및 로그를 수집하는 데 필수적인 클러스터의 에이전트가 활성화됩니다.
CloudWatch 에이전트는 클러스터의 모든 노드에 설치되므로 구성된 간격으로 시스템 및 애플리케이션 지표를 수집할 수 있습니다.
이름 및 애플리케이션
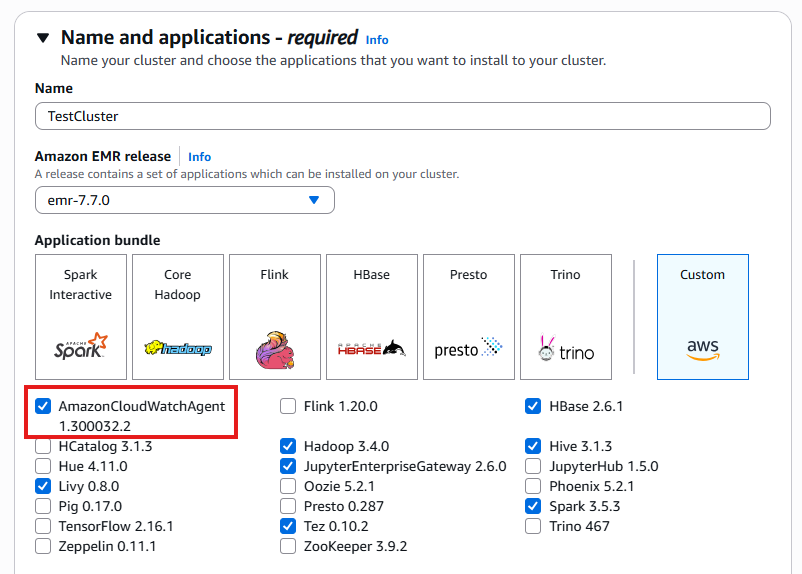
클러스터 생성 및 사용 가능한 번들 표시.
참고
CloudWatch 에이전트는 EMR 릴리스 7.0 이상에서 사용할 수 있습니다. 이 구성 요소를 활성화하려면이 가이드에 설명된 사용자 지정 지표 수집 및 로그 전달이 필요합니다.
2단계: 로그 수집을 위한 부트스트랩 작업 추가
특정 로그 파일을 수집하여 CloudWatch에 전달하도록 CloudWatch 에이전트를 구성하려면
-
EMR 클러스터 생성 마법사에서 부트스트랩 작업 섹션으로 이동합니다.
-
부트스트랩 작업 추가를 클릭합니다.
-
드롭다운 메뉴에서 사용자 지정 작업을 선택합니다.
-
부트스트랩 작업의 이름을 입력합니다(예: CloudWatch 에이전트 구성).
-
스크립트 위치 필드에 cloudwatch-agent-bootstrap.sh 스크립트의 S3 경로(예: s3://your-bucket-name/cloudwatch-agent-bootstrap.sh)를 입력합니다.
-
추가를 클릭하여 부트스트랩 작업을 저장합니다.
이 부트스트랩 작업은 클러스터 시작 중에 실행되어 CloudWatchagent가 구성 파일에 지정된 로그 파일을 수집하고 전달하도록 사용자 지정 설정으로 올바르게 구성되어 있는지 확인합니다.
노드가 프로비저닝되면 에이전트가 자동으로 로그 수집을 시작하여 CloudWatch Logs를 통해 클러스터 작업에 대한 실시간에 가까운 가시성을 제공합니다.
Bootstrap actions(부트스트랩 작업)
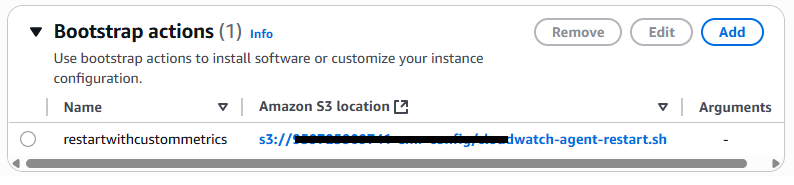
부트스트랩 작업 사용.
3단계: 사용자 지정 지표 수집 구성
기본 세트를 초과하는 사용자 지정 하둡, YARN 또는 HBase 지표의 수집을 활성화하려면:
-
EMR 클러스터 생성 마법사에서 구성 섹션으로 이동합니다.
-
구성 편집 버튼을 클릭하여 구성 옵션을 확장합니다.
-
구성 방법 드롭다운에서 Amazon S3에서 JSON 로드 옵션을 선택합니다.
-
사용자 지정 지표 분류 파일의 S3 URI 경로(예: s3://amzn-s3-demo-bucket1/emr-metrics-classification.json)를 입력합니다.
-
로드를 클릭하여 구성을 구문 분석합니다.
-
구성이 콘솔 인터페이스에 올바르게 나타나는지 확인합니다.
-
변경 사항 저장을 클릭하여 이러한 지표 구성을 클러스터에 적용합니다.
이 단계는 CloudWatch 에이전트에게 분류 파일에 정의된 특정 구성 요소 지표를 수집하도록 지시합니다. 지표는 구성에 지정된 간격으로 수집되어 CloudWatch에 게시되며, 여기에서 시각화하고 분석할 수 있습니다.
사용자 지정 지표는 클러스터의 성능 특성에 대한 심층적인 인사이트를 제공하므로 EMR 애플리케이션을 보다 정밀하게 모니터링하고 문제를 해결할 수 있습니다.
소프트웨어 설정
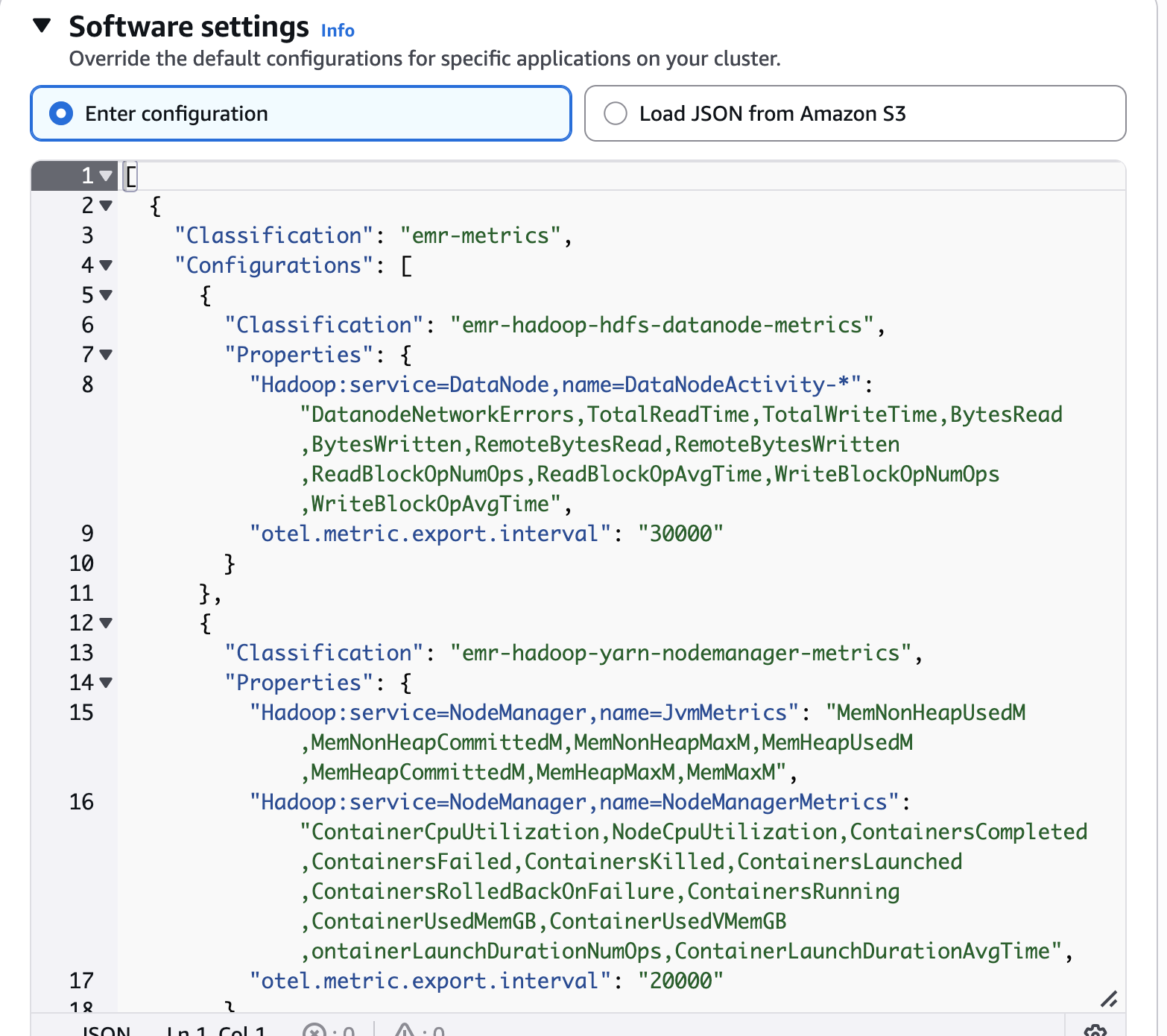
기본 구성을 재정의합니다.
클러스터 실행을 위한 지표 구성 업데이트
다음 단계에 따라 작업을 중단하지 않고 기존 EMR 클러스터에 대한 지표 수집 설정을 수정할 수 있습니다.
-
AWS 관리 콘솔에서 활성 EMR 클러스터로 이동합니다.
-
클러스터 세부 정보 보기에서 구성 탭을 선택합니다.
-
인스턴스 그룹 구성 섹션을 찾습니다.
-
재구성 버튼을 클릭하여 설정을 수정합니다.
-
Amazon S3에서 JSON 로드를 선택하거나 구성을 직접 편집합니다.
-
업데이트된 지표 분류 파일 위치를 입력하거나 편집기에서 변경합니다.
-
변경 사항을 적용하여 지표 수집 동작을 업데이트합니다.
이 재구성 기능을 사용하면 워크로드 요구 사항이 발전함에 따라 모니터링 접근 방식을 미세 조정할 수 있습니다. CloudWatch 에이전트는 클러스터를 다시 시작하거나 가동 중지하지 않고도 업데이트된 지표 세트를 수집하여 새 구성에 자동으로 적응합니다.
중요
구성 변경이 클러스터의 모든 노드에 전파되는 데 몇 분 정도 걸릴 수 있습니다. CloudWatch 대시보드를 계속 모니터링하여 새 지표가 예상대로 표시되는지 확인합니다.
클러스터 구성
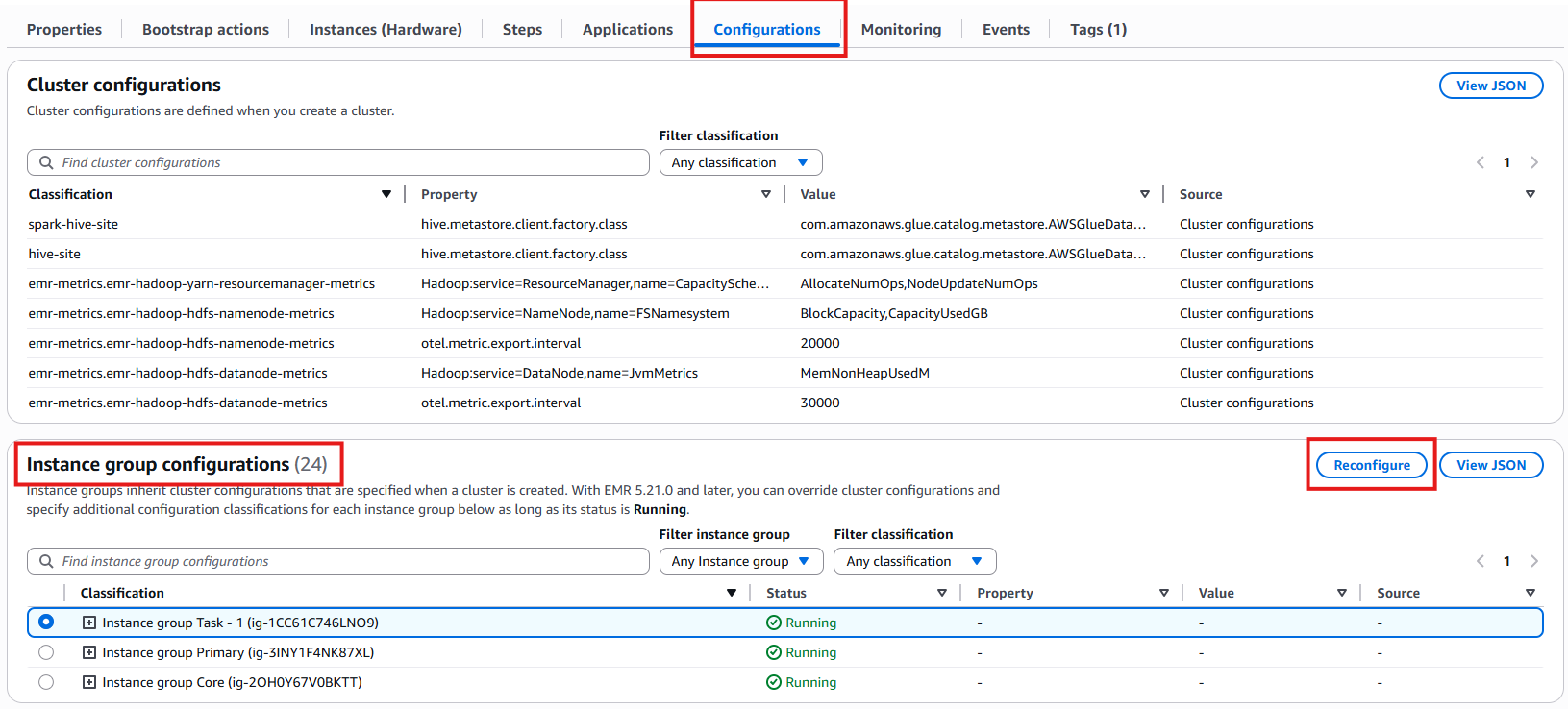
인스턴스 그룹 구성.
CloudWatch 통합 검증
구성 단계를 완료한 후에는 모니터링 설정이 올바르게 작동하는지 확인해야 합니다.
1단계: EMR 클러스터 배포
-
모든 구성 설정이 정확한지 검토합니다.
-
부트스트랩 작업 및 분류 파일이 올바르게 참조되는지 확인합니다.
-
클러스터 생성을 클릭하여 EMR 환경을 시작합니다.
-
클러스터가 실행 중 상태에 도달할 때까지 기다립니다(일반적으로 5~15분).
2단계: 테스트 애플리케이션 실행
여러 테스트 Spark 애플리케이션을 제출하여 의미 있는 지표를 생성합니다.
-
샘플 데이터를 처리하는 간단한 Spark 작업을 실행합니다.
-
더 오래 실행되는 분석 작업을 실행하여 리소스 사용률을 관찰합니다.
-
다양한 애플리케이션 구성을 테스트하여 성능 지표를 비교합니다.
애플리케이션이 완료된 후(또는 애플리케이션이 실행되는 동안):
-
CloudWatch 콘솔로 이동합니다.
-
구성된 로그 그룹에서 애플리케이션 로그를 확인합니다.
-
지표 대시보드를 검사하여 CPU, 메모리 및 애플리케이션별 지표를 관찰합니다.
-
분류 파일에 정의된 사용자 지정 지표가 CloudWatch에 나타나는지 확인합니다.
이 검증 프로세스는 CloudWatch 통합이 로그와 지표를 모두 올바르게 캡처하고 있는지 확인하여 EMR 클러스터의 성능 및 애플리케이션 동작에 대한 포괄적인 가시성을 제공합니다.
CloudWatch 로그 그룹의 EMR 로그 액세스
EMR 클러스터가 실행되고 CloudWatch 에이전트가 올바르게 구성되면 CloudWatch Logs에서 애플리케이션 및 시스템 로그를 사용할 수 있습니다. 다음 단계에 따라 액세스하고 분석합니다.
로그 그룹 보기
-
AWS 관리 콘솔에서 CloudWatch 콘솔로 이동합니다.
-
왼쪽 탐색 창에서 로그 그룹을 선택합니다.
-
다음과 같이 구성에 의해 생성된 로그 그룹을 찾습니다.
-
YARN ResourceManager 로그에 대한 /emr/yarn/resourcemnger.
-
HDFS emr/hdfs/namenodeNameNode.
-
구성 파일에 지정된 추가 로그 그룹입니다.
-
각 로그 그룹에는 인스턴스 ID별로 구성된 로그 스트림이 포함되어 있으므로 클러스터의 특정 노드에 대한 로그를 추적할 수 있습니다.
로그 데이터 작업
-
로그 데이터 검색: CloudWatch Logs Insights를 사용하여 로그 그룹 전체에서 구조화된 쿼리를 수행합니다.
-
지표 생성: 로그 패턴에서 지표를 추출하여 사용자 지정 CloudWatch 지표를 생성합니다.
-
알림 설정: 특정 오류 패턴 또는 로그 빈도를 기반으로 경보를 구성합니다.
-
로그 내보내기: 오프라인 분석 또는 아카이빙을 위한 로그를 다운로드합니다.
로그 보존
참고
기본적으로 로그는 30일 동안 보존됩니다. 규정 준수 또는 분석 목적으로 필요한 경우 각 로그 그룹의 보존 정책을 수정하여 로그를 더 오랜 기간 동안 유지할 수 있습니다.
CloudWatch Logs는 모든 EMR 로그 데이터에 대한 중앙 위치를 제공하므로 문제를 해결하거나 애플리케이션 동작을 분석하기 위해 개별 클러스터 노드로 SSH할 필요가 없습니다.
EMR 모니터링 대시보드에서 사용자 지정 지표 보기
EMR 클러스터를 CloudWatch 에이전트 및 사용자 지정 지표 구성으로 실행한 후 EMR 콘솔에서 직접 이러한 지표를 쉽게 모니터링할 수 있습니다.
사용자 지정 지표에 액세스
-
AWS 관리 콘솔에서 EMR 클러스터로 이동합니다.
-
클러스터 세부 정보 페이지에서 모니터링 탭을 선택합니다.
-
모니터링 대시보드 상단 근처에서 지표 분류 필터링 드롭다운을 찾습니다.
-
이 필터를 사용하여 특정 지표 범주를 선택합니다.
-
HDFS를 선택하여 NameNode 및 DataNode 지표를 봅니다.
-
YARN을 선택하여 ResourceManager 및 컨테이너 지표를 확인합니다.
-
HBase별 성능 데이터로 HBase를 선택합니다.
-
정의한 사용자 지정 지표 분류를 선택합니다.
-
대시보드는 선택한 지표에 대한 그래프를 표시하도록 동적으로 업데이트되어 시간 경과에 따른 성능 추세를 보여줍니다.
지표 시각화 작업
-
시간 범위 조정: 최근 활동 또는 과거 추세를 보려면 기간을 변경합니다.
-
지표 비교: 상관관계 분석을 위해 여러 관련 지표side-by-side 표시합니다.
-
확대/축소 기능: 이상 또는 패턴이 나타나는 특정 기간에 초점을 맞춥니다.
-
데이터 새로 고침: 거의 실시간으로 최신 지표 데이터로 시각화를 업데이트합니다.
이 통합 모니터링 접근 방식을 사용하면 통합 대시보드에서 표준 EMR 지표와 사용자 지정 지표를 모두 추적할 수 있으므로 EMR 콘솔을 벗어나지 않고도 성능 문제, 리소스 제약 또는 애플리케이션 병목 현상을 더 쉽게 식별할 수 있습니다.
CloudWatch 지표
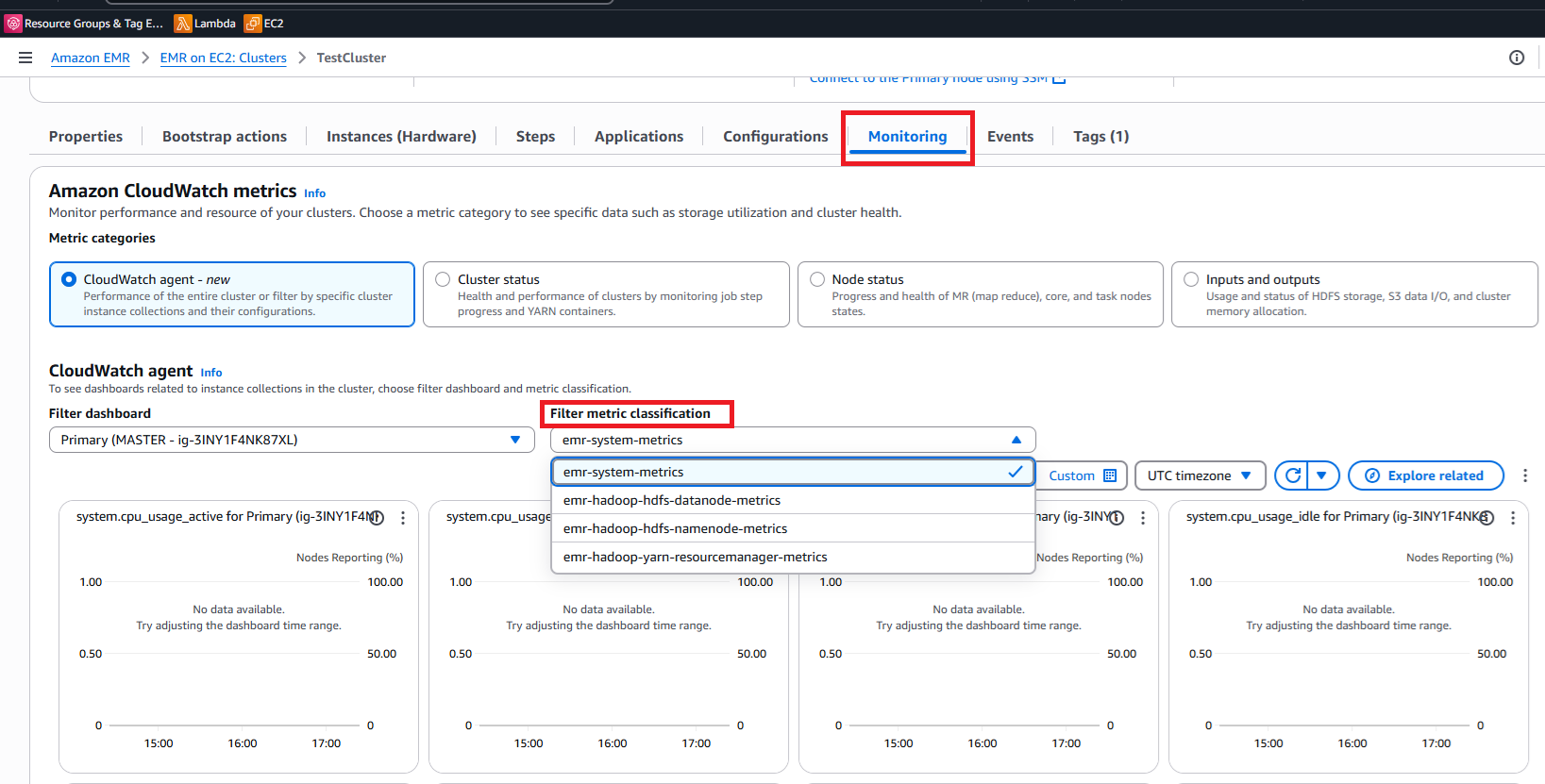
지표 분류 필터링.
