크롤러를 사용하여 데이터 카탈로그 채우기
AWS Glue 크롤러를 사용하면 데이터베이스 및 테이블을 사용하여 AWS Glue Data Catalog를 채울 수 있습니다. 대부분의 AWS Glue 사용자가 사용하는 기본적인 방법입니다. 크롤러는 단일 실행으로 여러 데이터 스토어를 크롤할 수 있습니다. 완료 시 크롤러는 데이터 카탈로그에서 하나 이상의 테이블을 생성하거나 업데이트합니다. AWS Glue에서 정의한 추출, 변환, 로드 작업은 이러한 데이터 카탈로그 테이블을 원본 및 대상으로 사용합니다. ETL 작업은 원본 및 대상 데이터 카탈로그 테이블에 지정된 데이터 스토어에서 읽기와 쓰기를 수행합니다.
워크플로
다음 워크플로 다이어그램은 AWS Glue 크롤러가 데이터 스토어와 다른 요소와 상호 작용하여 Data Catalog를 채우는 방법을 보여줍니다.
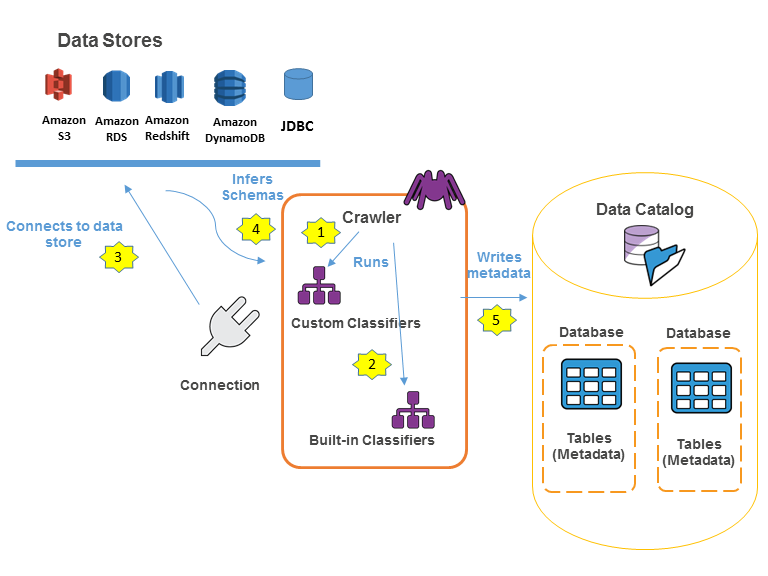
다음은 크롤러가 AWS Glue Data Catalog을 채우는 방법에 대한 일반적인 워크플로입니다.
-
크롤러는 선택한 사용자 지정 분류자를 실행하여 데이터의 형식 및 스키마를 추론합니다. 사용자 지정 분류자에 대한 코드를 제공하면 지정한 순서대로 실행됩니다.
첫 번째 사용자 분류자가 데이터 구조를 성공적으로 인식하는 과정은 테이블의 스키마를 생성하는 데 사용됩니다. 하위 목록에 있는 사용자 분류자는 건너뜁니다.
-
어떠한 사용자 지정 분류자도 데이터 스키마와 일치하지 않는다면 기본 설정 분류자는 데이터 스키마를 인식할 시도를 합니다. 기본 설정 분류자의 예는 JSON을 인식하는 분류자입니다.
-
크롤러를 데이터 스토어로 연결합니다. 어떤 데이터 스토어는 크롤러 액세스 연결 속성을 요구합니다.
-
추론된 스키마는 데이터 때문에 생성됩니다.
-
크롤러는 메타데이터를 Data Catalog로 작성합니다. 테이블 정의는 데이터 스토어의 데이터에 대한 메타데이터를 포함합니다. 테이블은 Data Catalog에서 테이블 컨테이너인 데이터베이스에 작성됩니다. 테이블 속성은 테이블 스키마를 추론한 분류자에 의해 생성된 라벨인 분류자를 포함합니다.
주제
크롤러 작동 방식
크롤러가 실행되면 데이터 스토어에서 정보를 얻기 위한 다음 작업을 실행합니다.
-
데이터를 분류하여 원시 데이터의 포맷, 스키마 및 관련 속성 결정 - 분류 결과는 사용자 정의 분류자를 생성하여 구성할 수 있습니다.
-
데이터를 테이블 혹은 파티션으로 분류합니다. – 데이터는 크롤러 발견을 기반으로 분류합니다.
-
메타데이터를 데이터 카탈로그에 작성합니다 – 크롤러가 어떻게 테이블과 파티션을 추가하고 업데이트, 삭제하는지 구성합니다.
크롤러를 정의할 때 스키마를 추론할 수 있도록 데이터 포맷을 평가하는 하나 이상의 분류자를 선택합니다. 크롤러가 실행되면 목록의 첫 번째 분류자가 성공적으로 데이터 스토어를 인식하고 테이블의 스키마를 생성합니다. 기본 제공 분류자를 사용하거나 사용자가 직접 정의할 수 있습니다. 크롤러를 정의하기 전에 별도의 작업에서 사용자 지정 분류자를 정의합니다. AWS Glue는 기본 제공 분류자를 제공하여 일반 파일에서 JSON, CSV 및 Apache Avro를 포함하는 포맷으로 스키마를 추론합니다. AWS Glue의 기본 제공 분류자의 현재 목록은 기본 제공 분류자 섹션을 참조하세요.
크롤러가 생성하는 메타데이터는 크롤러를 정의할 때 데이터베이스에 포함됩니다. 크롤러가 데이터베이스를 지정하지 않으면 테이블은 기본 데이터베이스로 배치합니다. 또한, 각 테이블은 처음으로 데이터 스토어를 성공적으로 인식하는 분류자로 채워진 분류 열이 있습니다.
크롤된 파일이 압축되면 크롤러는 반드시 다운로드하고 실행해야 합니다. 크롤러가 실행되면 크롤러는 파일 정보를 얻어 파일 포맷 및 압축 유형을 결정하고 파일 속성을 데이터 카탈로그에 작성합니다. Apache Parquet과 같은 일부 파일 형식은 파일이 작성한 대로 파일 일부를 압축할 수 있습니다. 이런 파일의 압축 데이터는 파일의 내부 구성 요소이고, AWS Glue는 데이터 카탈로그에 테이블을 쓸 때 compressionType 속성을 채우지 않습니다. 반대로 전체 파일이 gzip처럼 압축 알고리즘을 통해 압축된 후 compressionType 속성은 테이블이 데이터 카탈로그에 작성될 때 채워집니다.
크롤러는 생성하는 테이블 이름을 만듭니다. AWS Glue Data Catalog에 저장된 테이블 이름은 다음 규칙을 따릅니다.
-
영숫자와 밑줄(
_)만 허용됩니다. -
사용자 지정 접두사는 64자보다 길 수 없습니다.
-
이름 최대 길이는 128자보다 길 수 없습니다. 크롤러는 이름이 제한 범위 내에 있도록 이름을 줄입니다.
-
테이블 이름이 복제된다면 크롤러는 이름에 해시 문자열 접미사를 추가합니다.
크롤러가 일정에 따라 한 번을 초과하여 실행된다면 데이터 스토어에서 새로운 또는 변화된 파일 혹은 테이블을 찾습니다. 크롤러 출력값은 과거 실행에서 찾은 새로운 테이블과 파티션을 포함합니다.
크롤러는 파티션 생성 시기를 어떻게 결정하나요?
AWS Glue 크롤러가 Amazon S3 데이터 stpre를 스캔하고 버킷에서 여러 폴더를 발견하면 폴더 구조의 테이블 루트 및 테이블의 파티션에 해당하는 폴더를 결정합니다. Amazon S3 접두사 또는 폴더 이름을 기반의 테이블 이름. 크롤할 폴더 수준을 가리키는 [추가 경로]를 제공합니다. 폴더 수준의 다수 스키마가 유사한 경우, 크롤러는 개별 테이블 대신 테이블 파티션을 생성합니다. 크롤러가 개별 테이블에 영향을 주는 방법은 크롤러를 정의할 때 각 테이블의 루트 폴더를 데이터 스토어로 추가하는 것입니다.
예를 들어 다음과 같은 Amazon S3 폴더 구조를 고려합니다.
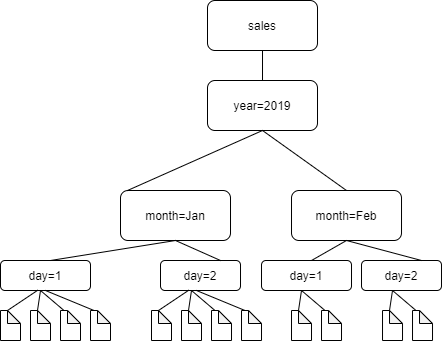
4개의 최하위 수준 폴더에 대한 경로는 다음과 같습니다.
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
크롤러 대상이 Sales로 설정되고 day=n 폴더의 모든 파일이 동일한 포맷(예: JSON, 암호화되지 않음)이고 동일하거나 매우 유사한 스키마를 갖는다고 가정합니다. 크롤러는 파티션 키가 year, month 및 day인 4개의 파티션이 있는 단일 테이블을 생성합니다.
다음 예에서는 다음과 같은 Amazon S3 구조를 고려합니다.
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
table1과 table2 아래의 파일 스키마가 유사하고 [포함 경로(Include path)]가 s3://bucket01/folder1/인 크롤러에 데이터 스토어 1개가 정의된 경우, 크롤러는 파티션 키 열 2개로 테이블 하나를 생성합니다. 첫 번째 파티션 키 열에는 table1과 table2기 포함되고 두 번째 파티션 키 열에는 table1 파티션의 경우 partition1~partition3, table2 파티션의 경우 partition4 및 partition5가 포함됩니다. 두 데이터 스토어로 크롤러를 정의하여 두 개별 테이블을 생성합니다. 이 예제에서는 첫 번째 Include path(추가 경로)를 s3://bucket01/folder1/table1/로 두 번째는 s3://bucket01/folder1/table2로 정의합니다.
참고
Amazon Athena에서 각 테이블은 모든 객체가 들어 있는 Amazon S3 접두사에 해당합니다. 객체들이 다른 스키마를 가지고 있으면 Athena는 동일한 접두사 내 다른 객체를 다른 테이블로 인식하지 못합니다. 크롤러가 동일한 Amazon S3 접두사의 여러 테이블을 생성하면 이와 같은 현상이 발생할 수 있습니다. 이는 어떤 결과 없이 Athena의 쿼리로 이끕니다. Athena가 테이블을 올바르게 인식하고 쿼리할 수 있도록 Amazon S3 폴더 구조에서 서로 다른 테이블 스키마마다 별도의 [포함 경로(Include path)]를 사용하여 크롤러를 생성합니다. 자세한 내용은 AWS Glue와 함께 Athena를 사용할 때의 모범 사례와 이 AWS 지식 센터 문서
