AWS Glue 개념
AWS Glue은(는) 완전 관리형 ETL(추출, 변환, 로드) 서비스로서 다양한 데이터 소스 및 타겟 간에 데이터를 쉽게 이동할 수 있습니다. 주요 구성 요소는 다음과 같습니다.
-
데이터 카탈로그: ETL 워크플로를 위한 테이블 정의, 작업 정의 및 기타 제어 정보가 포함되어 있는 메타데이터 저장소입니다.
-
크롤러: 데이터 소스에 연결하고, 데이터 스키마를 추론하고, 데이터 카탈로그에서 메타데이터 테이블 정의를 만드는 프로그램입니다.
-
ETL 작업: 소스에서 데이터를 추출하고, Apache Spark 스크립트를 사용하여 데이터를 변환하고, 타겟에 로드하는 비즈니스 로직입니다.
-
트리거: 일정이나 이벤트를 기반으로 작업 실행을 시작하는 메커니즘.
일반적인 워크플로에는 다음 사항이 포함됩니다.
-
데이터 카탈로그에서 데이터 소스 및 타겟을 정의합니다.
-
크롤러를 사용하여 데이터 소스의 테이블 메타데이터로 데이터 카탈로그를 채웁니다.
-
변환 스크립트로 ETL 작업을 정의하여 데이터를 이동하고 처리합니다.
-
온디맨드 또는 트리거를 기반으로 작업을 실행합니다.
-
대시보드를 사용하여 작업 성과를 모니터링합니다.
다음 다이어그램은 AWS Glue 환경의 아키텍처를 나타냅니다.
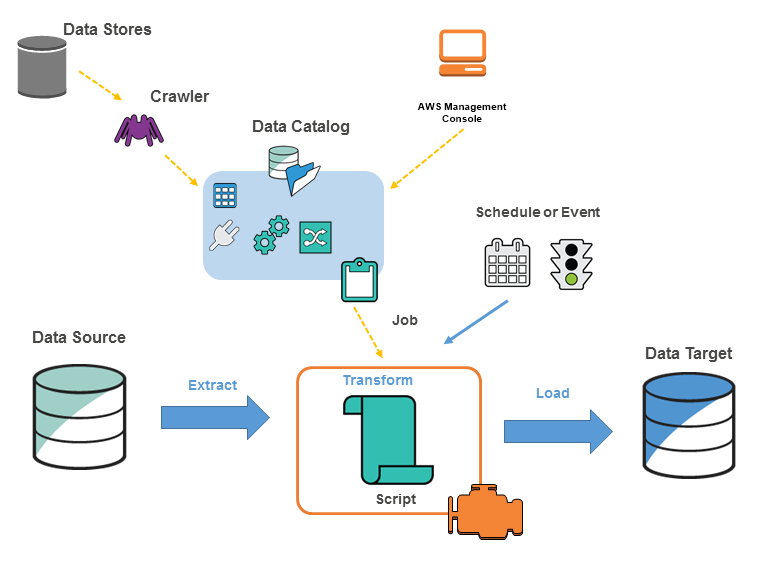
AWS Glue에서 작업을 정의하여 데이터 원본에서 데이터 대상으로 데이터를 추출, 변환, 로드하는 데 필요한 작업을 수행합니다. 일반적으로 다음 작업을 수행할 수 있습니다.
-
데이터 스토어 소스의 경우 크롤러를 정의하여 메타데이터 테이블 정의로 AWS Glue Data Catalog를 채웁니다. 데이터 스토어에서 크롤러를 포인트하면 크롤러는 Data Catalog에서 테이블 정의를 생성합니다. 스트리밍 소스의 경우 Data Catalog 테이블을 수동으로 정의하고 데이터 스트림 속성을 지정합니다.
테이블 정의에 관련해 추가하자면 AWS Glue Data Catalog는 다른 필수 메타데이터를 포함하여 ETL 작업을 정의합니다. 작업을 정의하여 데이터를 변환할 경우 이 메타데이터를 사용합니다.
AWS Glue는 스크립트를 생성하여 데이터를 변환할 있습니다. 또는 스크립트를 AWS Glue 콘솔이나 API에 제공합니다.
-
필요시 작업하거나 지정된 trigger가 발생하면 작업을 설정하여 시작할 수 있습니다. 트리거는 시간 기반 스케줄이나 이벤트일 수 있습니다.
작업이 진행되면 스크립트는 데이터 원본에서 데이터를 추출하고 데이터를 변환한 다음 데이터 대상으로 로드합니다. 스크립트는 AWS Glue의 Apache Spark 환경에서 실행됩니다.
중요
AWS Glue에 있는 테이블과 데이터베이스는 AWS Glue Data Catalog의 객체입니다. 이 객체들은 메타데이터를 포함하지만 데이터 스토어의 데이터는 포함하지 않습니다.
|
CSV와 같은 텍스트 기반 데이터를 처리하려면 AWS Glue용으로 |
AWS Glue 용어
AWS Glue에서는 여러 구성 요소의 상호 작용에 의존하여 추출, 전환, 적재(ETL) 워크플로를 생성하고 관리합니다.
AWS Glue Data Catalog
AWS Glue의 영구적 메타데이터 스토어입니다. 테이블 정의, 작업 정의 및 기타 관리 정보를 포함하여 AWS Glue 환경을 관리합니다. 각 AWS 계정에는 리전당 AWS Glue Data Catalog 하나가 있습니다.
분류자
데이터 스키마를 결정합니다. AWS Glue는 CSV, JSON, AVRO, XML 등과 같은 일반 파일 형식에 대한 분류자를 제공합니다. JDBC 연결을 사용한 일반 관계형 데이터베이스 관리 시스템을 위한 분류자를 제공합니다. a grok 패턴을 사용하거나 XML 문서에 행 태그를 지정하여 자체 분류자를 작성할 수 있습니다.
연결
특정 데이터 스토어에 연결하는 데 필요한 속성을 포함하는 Data Catalog 객체입니다.
크롤러
데이터 스토어(소스 또는 대상)에 연결하는 프로그램은 분류자의 우선 순위 지정 목록을 통해 데이터의 스키마를 결정한 다음 AWS Glue Data Catalog에 메타데이터 테이블을 생성합니다.
데이터베이스
논리 그룹으로 구성된 일련의 연결된 Data Catalog 테이블 정의입니다.
데이터 스토어, 데이터 원본, 데이터 대상
데이터 스토어는 데이터를 영구적으로 저장하기 위한 리포지토리입니다. 예를 들면 Amazon S3 버킷과 관계형 데이터베이스가 있습니다. 데이터 원본은 프로세스 또는 변환의 입력값으로 사용되는 데이터 스토어입니다. 데이터 대상은 프로세스 또는 변환에서 쓰기를 수행하는 대상 데이터 스토어입니다.
개발 엔드포인트
AWS Glue ETL 스크립트를 개발하고 테스트하는 데 사용할 수 있는 환경입니다.
동적 프레임
구조 및 배열과 같은 중첩 데이터를 지원하는 분산 테이블입니다. 각 레코드는 자기 설명적이며 반정형 데이터가 있는 스키마 유연성을 위해 설계되었습니다. 각 레코드에는 데이터와 해당 데이터를 설명하는 스키마가 모두 포함되어 있습니다. ETL 스크립트에서 동적 프레임과 Apache Spark DataFrame을 모두 사용하여 이 두 프레임 간에 변환할 수 있습니다. 동적 프레임은 데이터 정리 및 ETL에 필요한 고급 변환 세트를 지원합니다.
작업
작업은 ETL 작업을 수행하는 데 필요한 비즈니스 로직입니다. 변환 스크립트, 데이터 원본 및 데이터 대상으로 구성됩니다. 작업은 트리거에 의해 시작되고, 트리거는 예약되거나 이벤트 기반으로 작동할 수 있습니다.
작업 성능 대시보드
AWS Glue는 ETL 작업에 대한 포괄적인 실행 대시보드를 제공합니다. 대시보드에는 특정 기간의 작업 실행에 대한 정보가 표시됩니다.
노트북 인터페이스
간편한 작업 작성 및 데이터 탐색을 위해 원클릭 설정으로 향상된 노트북 환경. 노트북과 연결이 자동으로 구성됩니다. Jupyter Notebook 기반의 노트북 인터페이스를 통해 AWS Glue 서버리스 Apache Spark ETL 인프라를 사용하여 스크립트와 워크플로를 대화형으로 개발, 디버깅, 배포할 수 있습니다. 노트북 환경에서 임시 쿼리, 데이터 분석, 시각화(예: 테이블 및 그래프)를 수행할 수도 있습니다.
Script
소스에서 데이터를 추출하고 변환하고 대상으로 로드하는 코드입니다. AWS Glue는 PySpark 또는 Scala 스크립트를 생성합니다.
표
데이터를 나타내는 메타데이터 정의입니다. 데이터가 Amazon Simple Storage Service(Amazon S3) 파일, Amazon Relational Database Service(Amazon RDS) 테이블 또는 다른 데이터 집합에 있는지에 관계없이 테이블은 데이터의 스키마를 정의합니다. AWS Glue Data Catalog의 테이블은 열 이름, 데이터 유형 정의, 파티션 정보 및 베이스 데이터 세트에 대한 기타 메타데이터로 구성됩니다. 데이터의 스키마는 AWS Glue 테이블 정의에 나타납니다. 실제 데이터는 파일 혹은 관계형 데이터베이스 테이블 어디에 있든지 기존 데이터 스토어에 남겨집니다. AWS Glue는 파일과 관계형 데이터베이스 테이블 목록을 AWS Glue Data Catalog에 작성합니다. ETL 작업을 생성할 경우 소스와 대상로써 사용됩니다.
변환
다른 포맷으로 데이터를 바꾸는 코드 로직.
트리거
ETL 작업 시작. 트리거는 정해진 시간 혹은 이벤트 기반으로 정의할 수 있습니다.
시각적 작업 편집기
시각적 작업 편집기는 AWS Glue에서 추출, 전환, 적재(ETL) 작업을 쉽게 생성, 실행, 모니터링할 수 있게 해주는 그래픽 인터페이스입니다. 데이터 변환 워크플로를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 원활하게 실행하며 작업의 각 단계에서 스키마와 데이터 결과를 검사할 수 있습니다.
작업자
AWS Glue를 사용하면 ETL 작업을 실행하는 데 걸리는 시간 요금만 결제하면 됩니다. 관리할 리소스와 사전 투자 비용이 없으며 시작 시간 또는 종료 시간에 대한 요금이 부과되지 않습니다. ETL 작업을 실행하는 데 사용된 데이터 처리 단위(DPU) 수에 따라 시간당 요금이 청구됩니다. 단일 데이터 처리 단위(DPU)를 작업자라고도 합니다. AWS Glue에는 작업 대기 시간 및 비용 요구 사항을 충족하는 구성을 선택하는 데 도움이 되는 여러 작업자 유형이 있습니다. 작업자는 표준, G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, G.025X 및 메모리 최적화 R.1X, R.2X, R.4X, R.8X 구성으로 제공됩니다.
