기계 학습 변환 작업
AWS Glue를 사용하여 데이터를 정리하는 데 사용할 수 있는 사용자 지정 기계 학습 변환을 생성할 수 있습니다. AWS Glue 콘솔에서 작업을 생성할 때 이러한 변환을 사용할 수 있습니다.
기계 학습 변환을 생성하는 방법에 대한 자세한 내용은 AWS Lake Formation FindMatches로 레코드 매칭 단원을 참조하십시오.
변환 속성
기존 기계 학습 변환을 보려면 AWS Management Console에 로그인하고 https://console.aws.amazon.com/glue/
각 변환의 속성:
- 변환 이름
-
생성할 때 변환에 부여한 고유 이름입니다.
- ID
-
변환의 고유 식별자입니다.
- 레이블 수
-
변환 학습에 도움이 되도록 지정된 레이블 지정 파일의 레이블 수입니다.
- 상태 표시기
-
변환이 [준비(Ready)] 상태인지 또는 [훈련 필요(Needs training)] 상태인지를 나타냅니다. 작업에서 기계 학습 변환을 성공적으로 실행하려면 변환이 [준비(Ready)] 상태여야 합니다.
- Created
-
변환이 생성된 날짜입니다.
- 수정됨
-
변환이 마지막으로 업데이트된 날짜입니다.
- 설명
-
변환에 대해 제공된 설명(제공된 경우)입니다.
- AWS Glue 버전
-
사용된 AWS Glue 버전입니다.
- 실행 ID
-
생성할 때 변환에 부여한 고유 이름입니다.
- 작업 유형
-
기계 학습 변환의 유형입니다. 예: Find matching records(일치하는 레코드 찾기)
- 상태 표시기
-
작업 실행 상태를 나타냅니다. 가능한 상태는 다음과 같습니다.
-
Starting(시작 중)
-
실행 중
-
Stopping(중지 중)
-
Stopped(중지됨)
-
Succeeded(성공)
-
Failed(실패)
-
제한 시간
-
- 오류
-
상태가 실패인 경우 실패의 원인을 설명하는 오류 메시지가 표시됩니다.
기계 학습 변환 추가 및 편집
AWS Glue 콘솔에서 변환을 보기, 삭제, 설정 및 교육 또는 튜닝할 수 있습니다. 목록에서 변환 옆의 확인란을 선택하고, Action(작업)을 선택한 다음, 수행할 작업을 선택합니다.
새 ML 변환 생성
새 기계 학습 변환을 추가하려면 변환 생성을 선택합니다. 크롤로 추가 마법사의 지시에 따릅니다. 자세한 내용은 AWS Lake Formation FindMatches로 레코드 매칭 섹션을 참조하세요.
1단계. 변환 속성을 설정합니다.
-
이름 및 설명(선택 사항)을 입력합니다.
-
선택적으로 보안 구성을 설정합니다. 기계 학습 변환에 데이터 암호화 사용을(를) 참조하세요.
-
선택적으로 작업 실행 설정을 설정합니다. 작업 실행 설정을 통해 작업 실행 방식을 사용자 지정할 수 있습니다. 작업자 유형, 작업자 수, 작업 제한 시간(분), 재시도 횟수, AWS Glue 버전을 선택합니다.
-
선택적으로 태그를 설정합니다. 태그는 AWS 리소스에 할당할 수 있는 레이블입니다. 각 태그는 키와 값(선택사항)으로 구성됩니다. 태그를 사용하여 리소스를 검색 및 필터링하거나 AWS 비용을 추적할 수 있습니다.
2단계. 테이블과 프라이머리 키를 선택합니다.
-
AWS Glue 카탈로그 데이터베이스 및 테이블을 선택합니다.
-
선택한 테이블에서 프라이머리 키를 선택합니다. 프라이머리 키 열에는 일반적으로 데이터 소스의 모든 레코드에 대한 고유 식별자가 포함됩니다.
3단계. 튜닝 옵션을 선택합니다.
-
재현율 대 정밀도의 경우 튜닝 값을 선택하여 재현율 또는 정밀도에 유리하도록 변환을 튜닝합니다. 기본적으로 균형이 선택되지만 재현율에 유리하거나 정밀도에 유리하도록 선택할 수 있습니다. 또는 사용자 지정을 선택하고 0.0에서 1.0(포함) 사이의 값을 입력할 수 있습니다.
-
낮은 비용 및 정확도의 경우 낮은 비용에 유리하거나 정확도에 유리하도록 튜닝 값을 선택합니다. 또는 사용자 지정을 선택하고 0.0에서 1.0(포함) 사이의 값을 입력합니다.
-
일치 적용의 경우 사용하는 레이블과 일치하도록 강제 출력함으로서 ML 변환을 학습시키려면 레이블과 일치하도록 강제 출력을 선택합니다.
4단계. 검토 및 생성.
-
1~3단계의 옵션을 검토합니다.
-
수정이 필요한 모든 단계에서 편집을 선택합니다. 변환 생성을 선택하여 변환 생성 마법사를 완료합니다.
기계 학습 변환에 데이터 암호화 사용
기계 학습 변환을 AWS Glue에 추가할 때 데이터 원본 또는 데이터 대상과 연결된 보안 구성을 선택적으로 지정할 수 있습니다. 데이터를 저장하는 데 사용된 Amazon S3 버킷이 보안 구성으로 암호화된 경우 변환을 생성할 때 동일한 보안 구성을 지정합니다.
또한 AWS KMS(SSE-KMS)로 서버 측 암호화를 사용하여 모델과 레이블을 암호화하여 권한이 없는 사람이 모델을 검사하지 못하도록 할 수 있습니다. 이 옵션을 선택하면 이름으로 AWS KMS key를 선택하라는 메시지가 나타나거나 [키 ARN 입력(Enter a key ARN)]을 선택할 수 있습니다. KMS 키에 대한 ARN을 입력하도록 선택하면 KMS 키 ARN을 입력할 수 있는 두 번째 필드가 나타납니다.
참고
현재 사용자 지정 암호화 키를 사용하는 ML 변환은 다음 리전에서 지원되지 않습니다.
-
아시아 태평양(오사카) -
ap-northeast-3
변환 세부 정보 보기
변환 속성 보기
변환 속성 페이지에는 변환 속성이 포함되어 있습니다. 이 탭은 다음을 포함하여 변환 정의에 대한 세부 정보를 보여 줍니다.
-
Transform name(변환 이름)은 변환의 이름을 보여 줍니다.
-
Type(유형)에는 변환의 유형이 나열됩니다.
-
Status(상태)는 변환이 스크립트 또는 작업에 사용할 준비가 되었는지 여부를 표시합니다.
-
Force output to match labels(레이블과 일치하도록 출력 강제)는 변환이 사용자가 제공한 레이블과 일치하도록 출력을 강제하는지 여부를 표시합니다.
-
[Spark 버전(Spark version)]은 변환을 추가할 때 [태스크 실행 속성(Task run properties)]에서 선택한 AWS Glue 버전과 관련이 있습니다. AWS Glue 1.0 및 Spark 2.4는 대부분의 고객에게 권장됩니다. 자세한 내용은 AWS Glue 버전을 참조하세요.
기록, 품질 예측 및 태그 탭
변환 세부 정보에는 변환을 생성할 때 정의한 정보가 포함되어 있습니다. 변환에 대한 세부 정보를 보려면 Machine learning transforms(기계 학습 변환) 목록에서 변환을 선택하고 다음 탭에서 정보를 검토합니다.
-
기록
-
품질 예측
-
Tags
기록
History(기록) 탭에는 변환 작업 실행 기록이 표시됩니다. 변환을 교육하기 위해 여러 유형의 작업이 실행됩니다. 각 작업에 대한 실행 지표에는 다음이 포함됩니다.
-
Run ID(실행 ID)는 이 작업의 각 실행에 대해 AWS Glue에서 생성된 식별자입니다.
-
Task type(작업 유형)은 작업 실행의 유형을 보여 줍니다.
-
Run status(실행 상태)에는 맨 위에 가장 최근 실행부터 순서대로 나열된 각 작업의 성공 여부를 보여 줍니다.
-
오류는 성공적이지 못한 실행의 결과로서 오류 메시지의 세부 정보를 보여줍니다.
-
Start time(시작 시간)은 작업이 시작된 날짜와 시간(로컬 시간)을 보여줍니다.
-
종료 시간은 작업이 종료되는 날짜와 시간(로컬 시간)을 보여줍니다.
-
Logs(로그)는 이 작업을 실행할 때
stdout에 작성되는 로그와 연결됩니다.[로그(Logs)] 링크를 클릭하면 Amazon CloudWatch Logs로 이동됩니다. 그곳에서는 AWS Glue Data Catalog에서 생성된 테이블 및 발생한 오류에 대한 모든 세부 정보를 볼 수 있습니다. CloudWatch 콘솔에서 로그 보존 기간을 관리할 수 있습니다. 기본 로그 보관은
Never Expire. 보존 기간 변경 방법에 대한 자세한 내용은 Amazon CloudWatch Logs User Guide의 Change Log Data Retention in CloudWatch Logs를 참조하세요. -
레이블 파일은 Amazon S3에 대한 생성된 레이블 지정 파일의 링크를 보여줍니다.
품질 예측
Estimate quality(예상 품질) 탭은 변환의 품질을 측정하는 데 사용할 수 있는 지표를 보여 줍니다. 추정치는 레이블 지정 데이터의 하위 세트를 사용하는 변환 일치 예측과 사용자가 제공한 레이블을 비교해서 계산합니다. 이 추정치는 근사값입니다. 이 탭에서 Estimate quality(예상 품질) 작업 실행을 호출할 수 있습니다.
Estimate quality(예상 품질) 탭에는 다음 속성이 포함된 마지막 Estimate quality(예상 품질) 실행의 지표가 표시됩니다.
-
Area under the Precision-Recall curve(정밀도-재현율 곡선 아래 면적)는 전체적 변환 품질의 상한값을 예측하는 단일 숫자입니다. 이 항목은 정밀도-재현율 파라미터에 대해 수행한 선택과 무관합니다. 값이 높을수록 더 매력적인 정밀도-재현율 트레이드오프가 있음을 나타냅니다.
-
Precision(정밀도)은 변환이 일치를 정확하게 예측하는 빈도를 예측치로 표시합니다.
-
Recall upper limit(재현율 상한)는 실제 일치에 대해 변환이 일치를 예측하는 빈도를 예측치로 표시합니다.
-
F1은 0~1의 범위에서 변환의 정확도를 예측합니다. 여기서 1은 최상의 정확도입니다. 자세한 내용은 Wikipedia의 F1 점수
를 참조하십시오. -
[열 중요도(Column importance)] 테이블에는 각 열의 열 이름과 중요도 점수가 표시됩니다. 열 중요도는 일치 작업을 수행하는 데 가장 많이 사용되는 레코드의 열을 식별하여 열이 모델에 기여하는 방식을 이해하는 데 도움이 됩니다. 이 데이터는 열 중요도를 높이거나 낮추기 위해 레이블 집합을 추가하거나 변경하라는 메시지를 표시할 수 있습니다.
중요도 열은 1.0 이하의 십진수로 각 열에 대한 숫자 점수를 제공합니다.
품질 예측과 실제 품질 비교 이해에 대한 자세한 내용은 품질 예측과 엔드 투 엔드(실제) 품질 비교 단원을 참조하십시오.
변환 튜닝에 대한 자세한 내용은 AWS Glue에서 기계 학습 변환 튜닝 단원을 참조하십시오.
품질 예측과 엔드 투 엔드(실제) 품질 비교
AWS Glue에서는 사용자가 일치하는 레이블을 제공했지만 이전에 모델에서는 본 적이 없는 수많은 레코드 페어로 기계 학습된 내부 모델을 제시하여 변환의 품질을 예측합니다. 이러한 품질 예측은 기계 학습된 모델의 품질 함수입니다(변환을 “교육”하기 위해 레이블 지정하는 수많은 레코드의 영향을 받음). 엔드 투 엔드 또는 실제 재현율(ML transform으로 자동 계산되지 않음)은 있을 수 있는 다양한 일치 항목을 기계 학습된 모델에 제안하는 ML transform 필터링 메커니즘의 영향도 받습니다.
주로 낮은 비용 대비 정확도 튜닝 값을 사용하여 이 필터링 방법을 튜닝할 수 있습니다. 튜닝 값이 정확도 쪽으로 이동할수록 시스템은 일치 항목일 수 있는 레코드 페어에 대해 더 철저하고 비용이 많이 드는 검색을 수행합니다. 더 많은 레코드 페어가 기계 학습된 모델에 공급되며, ML transform의 엔드 투 엔드 또는 실제 재현율은 예상된 재현율 지표에 더 가깝게 접근합니다. 그 결과 일치 항목에 대한 비용/정확성 트레이드오프 변화에 따른 일치 항목의 엔드 투 엔드 품질 변화는 일반적으로 품질 예측치에 반영되지 않습니다.
Tags
태그는 AWS 리소스에 할당할 수 있는 레이블입니다. 각 태그는 키와 값(선택사항)으로 구성됩니다. 태그를 사용하여 리소스를 검색 및 필터링하거나 AWS 비용을 추적할 수 있습니다.
레이블을 사용하여 변환 학습
ML 변환 세부 정보 페이지에서 변환 학습을 선택하여 레이블(예제)을 사용한 ML 변환을 학습할 수 있습니다. 예제(레이블이라고도 함)를 제공하여 기계 학습 알고리즘을 학습할 때 사용할 기존 레이블을 선택하거나 레이블 지정 파일을 생성할 수 있습니다.
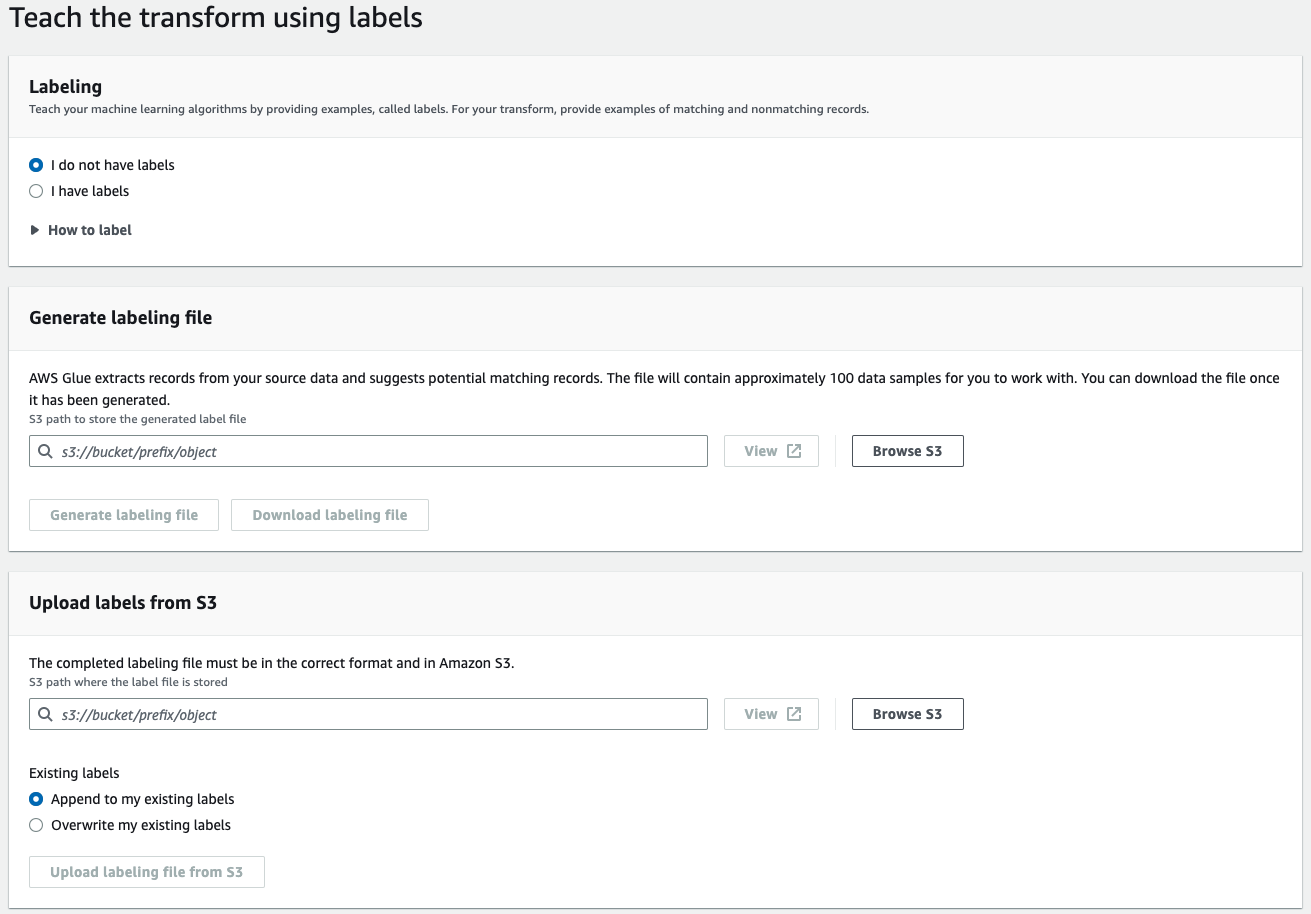
-
레이블 지정 - 레이블이 있는 경우 레이블 있음을 선택합니다. 레이블이 없으면 레이블 지정 파일을 생성하는 다음 단계를 계속할 수 있습니다.
-
레이블 지정 파일 생성 - AWS Glue는 소스 데이터에서 레코드를 추출하고 일치 가능성이 있는 레코드를 제안합니다. 생성된 레이블 파일을 저장할 Amazon S3 버킷을 선택합니다. 레이블 지정 파일 생성을 선택하여 프로세스를 시작합니다. 완료되면 레이블 지정 파일 다운로드를 선택합니다. 다운로드한 파일에는 레이블에 입력할 수 있는 레이블 열이 있습니다.
-
Amazon S3에서 레이블 업로드 - 레이블 파일이 저장되어 있는 Amazon S3 버킷에서 완성된 레이블 지정 파일을 선택합니다. 그런 다음 기존 레이블에 레이블을 추가하거나 기존 레이블을 덮어쓸지 선택합니다. Amazon S3에서 레이블 지정 파일 업로드를 선택합니다.
