기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS Glue 콘솔에서 테이블 관련 작업
AWS Glue Data Catalog에서 테이블은 데이터 스토어의 데이터를 표현하는 메타데이터 정의입니다. 크롤러를 실행하여 테이블을 생성하거나 AWS Glue 콘솔을 사용하여 수동으로 테이블을 생성할 수 있습니다. AWS Glue 콘솔의 [테이블(Tables)] 목록에는 테이블의 메타데이터 값이 표시됩니다. ETL(Extract, Transform, and Load) 작업을 생성할 시 테이블 정의를 사용하여 소스 및 타켓을 명시합니다.
참고
AWS Management Console이 최근에 변경되었으므로 SearchTables 권한을 가지려면 기존 IAM 역할을 수정해야 할 수 있습니다. 새 역할 생성을 위해 SearchTables API 권한이 이미 기본값으로 추가되었습니다.
시작하려면 AWS Management Console에 로그인하고 https://console.aws.amazon.com/glue/
콘솔에서 테이블 추가
크롤러를 사용하여 테이블을 추가하려면 [Add tables]에서 [Add tables using a crawler]를 선택합니다. 다음, [Add crawler] 마법사 지시에 따릅니다. 크롤러가 실행되면 테이블은 AWS Glue Data Catalog에 추가됩니다. 자세한 설명은 AWS Glue에서 크롤러 정의 섹션을 참조하세요.
요구되는 속성을 알면 테이블 마법사를 통해 Data Catalog에 Amazon Simple Storage Service(Amazon S3) 테이블 정의를 생성할 수 있습니다. [Add tables]에서 [Add table manually]를 선택하고 [Add table] 마법사 지시를 따릅니다.
수동으로 콘솔을 통해 테이블을 추가할 때는 다음을 참조하세요.
-
Amazon Athena에서 테이블에 액세스하고자 할 경우, 공급자 이름을 영숫자 문자와 밑줄 표시로 생성합니다. 자세한 내용은 Athena 이름을 참조하세요.
-
원본 데이터의 위치는 Amazon S3 경로여야 합니다.
-
데이터의 데이터 형식은 마법사의 형식과 일치해야 합니다. 해당 분류 SerDe, 및 기타 테이블 속성은 선택한 형식에 따라 자동으로 채워집니다. 다음 형식을 사용하여 테이블을 정의할 수 있습니다.
- Avro
-
아파치 아브로 JSON 이진 형식
- CSV
-
값 분리 가치. 콤마 혹은 파이프, 세미콜론, 탭, Ctrl+A의 구획 문자를 명시합니다.
- JSON
-
JavaScript 객체 표기법.
- XML
-
확장형 마크업 언어 형식 데이터에서 열을 정의하는 XML 태그를 명시합니다. 컬럼은 열 태그들 내에서 정의합니다.
- PARQUET
-
Apache Parquet 컬럼 방식 스토리지
- ORC
-
Optimized Row Columnar(ORC) 파일 형식입니다. Hive 데이터를 효율적으로 저장하도록 설계된 형식입니다.
-
테이블의 파티션 키를 정의할 수 있습니다.
-
현재, 콘솔을 사용하여 생성한 파티션된 테이블은 ETL 작업 시 사용할 수 없습니다.
테이블 속성
다음은 테이블이 갖는 몇 가지 중요한 특징입니다.
- 명칭
-
테이블 생성 시 이름이 결정되고 변경할 수 없습니다. 테이블 이름은 많은 AWS Glue 작업을 참조하십시오.
- 데이터베이스
-
컨테이너 객체는 테이블이 위치한 곳입니다. 이 객체는 AWS Glue Data Catalog 내 존재하는 테이블 조직을 포함하고 데이터 스토어의 조직과 다를 수 있습니다. 데이터베이스를 삭제하면 데이터베이스에 포함된 모든 테이블도 Data Catalog에서 삭제됩니다.
- 설명
-
테이블에 대한 설명입니다. 테이블 내용을 이해할 수 있도록 설명을 적을 수 있습니다.
- 테이블 형식
-
표준 AWS Glue 테이블 또는 Apache Iceberg 형식의 테이블 생성을 지정합니다.
- 압축 활성화
-
테이블에 있는 작은 Amazon S3 객체를 더 큰 객체로 압축하려면 압축 활성화를 선택합니다.
- IAM 역할
압축을 실행하기 위해 서비스는 사용자를 대신하여 IAM 역할을 맡습니다. 드롭다운을 사용하여 IAM 역할을 선택할 수 있습니다. 압축 기능을 활성화하는 데 필요한 권한이 역할에 있는지 확인합니다.
IAM 역할에 필요한 권한에 대해 알아보려면 테이블 최적화 필수 조건 섹션을 참조하십시오.
- 위치
-
이 테이블 정의는 데이터 스토어의 데이터 위치를 표현하는 포인터를 표시합니다.
- 분류
-
테이블 생성 시 분류 값이 제공됩니다. 일반적으로 크롤러가 소스 데이터 형식을 실행하고 명시하면 이것이 적힙니다.
- 최종 업데이트 날짜
-
Data Catalog에 이 테이블이 업데이트된 시간 및 날짜(UTC).
- 데이터 추가됨
-
Data Catalog에 이 테이블이 추가된 시간 및 날짜(UTC).
- Deprecated
-
기존 데이터 스토어에 Data Catalog의 테이블이 존재하지 않고 AWS Glue가 이를 인식하면 데이터 카탈로그에 이 테이블을 사용 중단 상태로 표시합니다. 사용 중단된 테이블을 참조하는 작업을 실행하면 그 작업은 실행되지 않을 수 있습니다. 사용 중단된 테이블을 참조하는 작업을 편집하여 소스와 타켓으로써 제거합니다. 더 이상 필요하지 않은 사용 중단된 테이블은 삭제하는 것이 좋습니다.
- 연결
-
AWS Glue가 데이터 스토어에 연결하고자 할 경우, 연결 이름은 테이블과 관련이 있습니다.
테이블 세부 정보 보기 및 편집
목록에서 테이블 이름을 선택하고 [Action, View details]를 선택하여 존재하는 테이블의 세부 정보를 열람합니다.
테이블 세부 정보는 테이블 속성과 스키마를 포함합니다. 이 화면은 테이블을 정의하기 위한 열 이름, 데이터 유형, 파티션 키 열 등을 포함한 테이블 스키마를 표시합니다. 복잡한 유형의 열은 [속성 보기(View properties)]를 선택하여 다음 예처럼 필드 구조의 세부 사항을 표시합니다.
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
이러한 속성에 대한 StorageDescriptor와 같은 자세한 내용은 StorageDescriptor 구조를 참조하십시오.
[Edit schema]를 선택하여 열을 추가 및 제거하고 열 이름과 데이터 유형을 바꿔 테이블 스키마를 바꿀 수 있습니다.
스키마를 포함하여 테이블의 여러 버전을 비교하려면 버전 비교를 선택하여 테이블에 대한 두 버전의 스키마를 side-by-side 비교한 내용을 확인하십시오. 자세한 설명은 테이블 스키마 버전 비교 섹션을 참조하세요.
Amazon S3 파티션을 구성하는 파일을 표시하려면 [파티션 보기(View partition)]를 선택합니다. Amazon S3 테이블의 [키(Key)] 열은 원본 데이터 스토어 테이블의 파티션에 사용된 파티션 키를 표시합니다. 파티셔닝은 날짜, 위치, 출발점과 같이 키 열 값을 기준으로 테이블을 관련 부분으로 나눕니다. 파티션에 대한 보다 자세한 내용은 "hive partitioning"으로 웹서치를 하시기 바랍니다.
참고
테이블 세부 정보를 보는 step-by-step 방법에 대한 지침을 보려면 콘솔의 Explore 테이블 자습서를 참조하십시오.
테이블 스키마 버전 비교
두 버전의 테이블 스키마를 비교할 때 중첩된 행을 확장 및 축소하여 중첩 행 변경 내용을 비교하고, 두 버전의 side-by-side 스키마를 비교하고, 테이블 속성을 볼 수 있습니다. side-by-side
버전을 비교하려면
-
AWS Glue Console에서 테이블, 작업을 선택한 다음 버전 비교를 선택합니다.
-
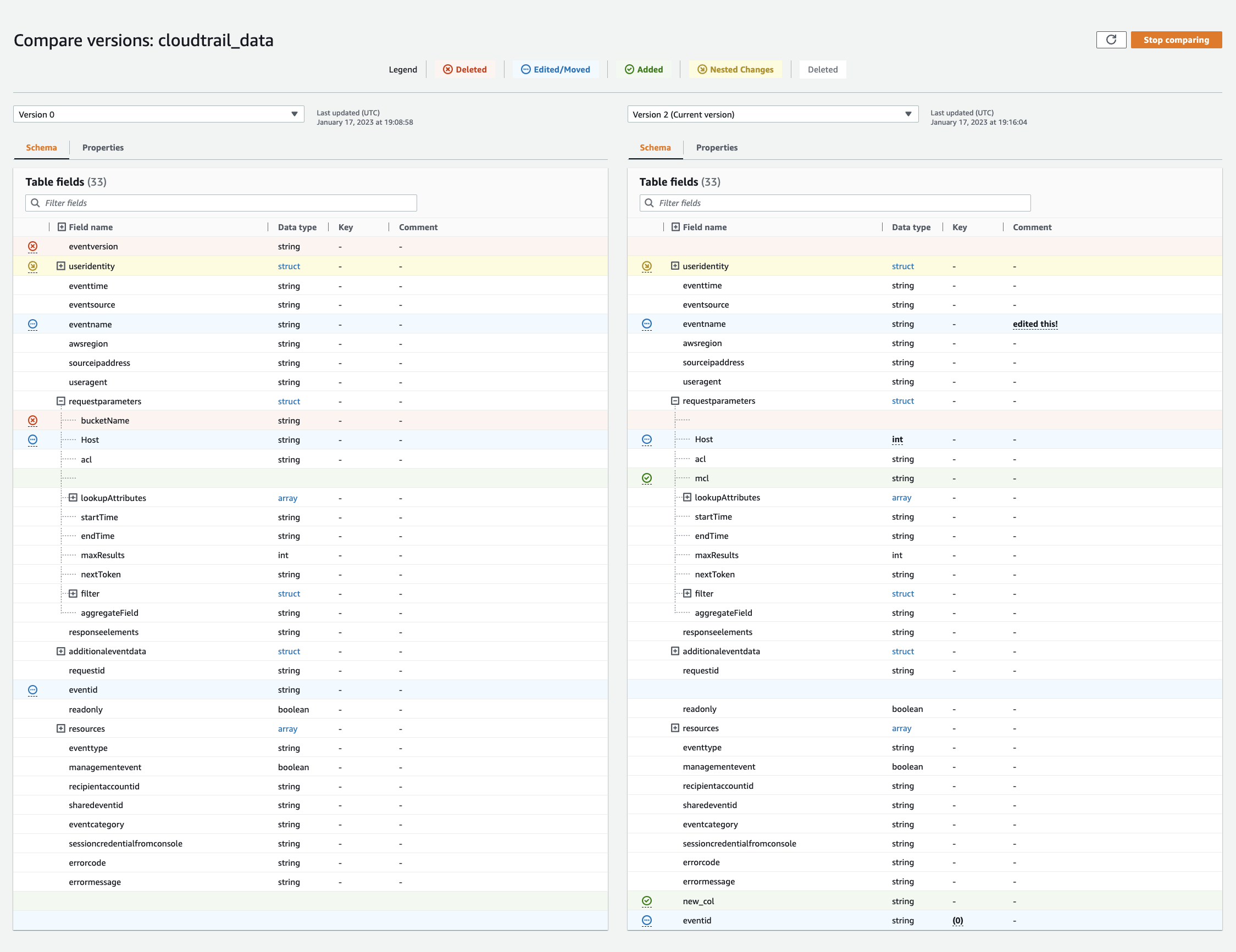
버전 드롭다운 메뉴를 선택하여 비교할 버전을 선택합니다. 스키마를 비교할 때 스키마 탭은 주황색으로 강조 표시됩니다.
-
두 버전 간에 테이블을 비교하면 화면 왼쪽과 오른쪽에 테이블 스키마가 표시됩니다. 이렇게 하면 열 이름, 데이터 유형, 키 및 설명 필드를 비교하여 변경 내용을 시각적으로 확인할 수 있습니다. side-by-side 변경 사항이 있을 경우 색상 아이콘에 적용된 변경 유형이 표시됩니다.
-
삭제됨 - 빨간색 아이콘으로 표시되면 이전 버전의 테이블 스키마에서 해당 열이 제거된 위치를 나타냅니다.
-
편집됨 또는 이동됨 - 파란색 아이콘으로 표시되면 새 버전의 테이블 스키마에서 열이 수정 또는 이동된 위치를 나타냅니다.
-
추가됨 - 녹색 아이콘으로 표시되면 해당 열이 새 버전의 테이블 스키마에 추가된 위치를 나타냅니다.
-
중첩된 변경 내용 - 노란색 아이콘으로 표시되면 중첩된 열에 변경 내용이 포함된 위치를 나타냅니다. 확장할 열을 선택하면 삭제, 편집, 이동 또는 추가된 열이 표시됩니다.
-
-
필터 필드 검색 창을 사용하면 여기에 입력한 문자를 기반으로 필드를 표시할 수 있습니다. 테이블 버전 중 하나에 열 이름을 입력하면 필터링된 필드가 두 테이블 버전 모두에 표시되어 변경 사항이 발생한 위치를 보여 줍니다.
-
속성을 비교하려면 속성 탭을 선택합니다.
-
버전 비교를 중지하려면 비교 중지를 선택하여 테이블 목록으로 돌아갑니다.
Iceberg 테이블 최적화
Apache Iceberg와 같은 오픈 테이블 형식을 사용하는 Amazon S3 데이터 레이크는 데이터를 Amazon S3 객체로 저장합니다. 데이터 레이크 테이블에 수천 개의 작은 Amazon S3 객체가 있으면 Iceberg 테이블의 메타데이터 오버헤드가 증가하고 읽기 성능에 영향을 줍니다. Amazon Athena, Amazon EMR, AWS Glue ETL 작업과 같은 AWS 분석 서비스를 통한 읽기 성능 향상을 위해 AWS Glue Data Catalog은 Data Catalog의 Iceberg 테이블에 대한 관리형 압축(작은 Amazon S3 객체를 더 큰 객체로 압축하는 프로세스)을 제공합니다. AWS Glue 콘솔, Lake Formation 콘솔. AWS CLI 또는 AWS API를 사용하여 데이터 카탈로그에 있는 개별 Iceberg 테이블에 대한 압축을 활성화하거나 비활성화할 수 있습니다.
테이블 옵티마이저는 테이블 파티션을 지속적으로 모니터링하여 파일 수 및 파일 크기가 임곗값을 초과할 경우 압축 프로세스를 시작합니다. 데이터 카탈로그에서 압축 시작을 위한 기본 임곗값은 384MB로 설정되어 있는 반면, Iceberg 라이브러리에서는 압축 임곗값이 대상 파일 크기의 최대 75% 입니다. 데이터 카탈로그는 동시 쿼리를 방해하지 않고 압축을 수행합니다. 데이터 카탈로그는 Parquet 형식의 테이블에 대해서만 데이터 압축을 지원합니다.
테이블 최적화 필수 조건
테이블 최적화 프로그램은 테이블에 압축 기능을 사용할 때 사용자가 지정하는 AWS Identity and Access Management (IAM) 역할의 권한을 갖습니다. IAM 역할에는 데이터 카탈로그의 데이터를 읽고 메타데이터를 업데이트할 수 있는 권한이 있어야 합니다. IAM 역할을 생성하여 다음 인라인 정책을 연결할 수 있습니다.
-
Lake Formation에 등록되지 않은 데이터에 대한 위치에 대한 Amazon S3 읽기/쓰기 권한을 부여하는 다음 인라인 정책을 추가하세요. 이 정책에는 데이터 카탈로그의 테이블을 업데이트하고 AWS Glue에게 Amazon CloudWatch 로그에 로그를 추가하고 지표를 게시할 수 있는 권한도 포함되어 있습니다. Lake Formation에 등록되지 않은 Amazon S3의 원본 데이터는 액세스 권한이 Amazon S3 및 AWS Glue 작업에 대한 IAM 권한 정책에 의해 결정됩니다.
다음 인라인 정책에서는 Amazon S3 버킷 이름이 있는
bucket-name,aws-account-id,region을 데이터 카탈로그의 유효한 AWS 계정 번호, 리전,database_name을 데이터베이스 이름으로,table_name은 테이블 이름으로 대체하십시오.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<bucket-name>/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<bucket-name>" ] }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<database-name>/<table-name>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] } -
Lake Formation에 등록된 데이터에 대해 압축을 활성화하려면 다음 정책을 사용하십시오.
Amazon S3 버킷을 Lake Formation에 등록하는 방법에 대한 자세한 내용은 위치 등록에 사용되는 역할 요구 사항을 참조하십시오.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lakeformation:GetDataAccess" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<databaseName>/<tableName>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] }압축 역할에 테이블에 부여된
IAM_ALLOWED_PRINCIPALS그룹 권한이 없는 경우 해당 역할에는 테이블에 대한 Lake Formation ALTER, DESCRIBE, INSERT 및 DELETE 권한이 필요합니다. -
(선택 사항) 서버 측 암호화를 사용하여 암호화된 Amazon S3 버킷의 데이터로 Iceberg 테이블을 압축하려면 압축 역할에 Amazon S3 객체를 해독하고 암호화된 버킷에 객체를 쓰기 위한 새 데이터 키를 생성할 수 있는 권한이 필요합니다. 다음 텍스트를 AWS KMS 키 정책에 추가합니다. 버킷 수준 암호화만 지원합니다.
{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:role/<compaction-role-name>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": "*" } -
(선택 사항) Lake Formation에 등록된 데이터 위치의 경우, 위치를 등록하는 데 사용되는 역할에는 Amazon S3 객체를 해독하고 암호화된 버킷에 객체를 쓰기 위한 새 데이터 키를 생성할 수 있는 권한이 필요합니다. 자세한 내용을 알아보려면 암호화된 Amazon S3 위치 등록을 참조하십시오.
-
(선택 사항) AWS KMS 키가 다른 AWS 계정에 저장되어 있는 경우 압축 역할에 다음 권한을 포함해야 합니다.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": ["arn:aws:kms:<REGION>:<KEY_OWNER_ACCOUNT_ID>:key/<KEY_ID>"] } ] } -
압축을 실행하는 데 사용하는 역할에는 해당 역할에 대한
iam:PassRole권한이 있어야 합니다.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": [ "arn:aws:iam::<account-id>:role/<compaction-role-name>" ] } ] } -
압축 프로세스를 실행하는 IAM 역할을 수임하도록 AWS Glue 서비스의 역할에 다음 신뢰 정책을 추가합니다.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
압축 활성화
AWS Glue 콘솔, Lake Formation 콘솔, AWS CLI 또는 AWS API를 사용하여 데이터 카탈로그의 Apache Iceberg 테이블을 압축할 수 있습니다. 새 테이블의 경우 Apache Iceberg를 테이블 형식으로 선택하고 테이블을 생성할 때 압축을 활성화할 수 있습니다. 압축 기능은 새 테이블에 대해 기본적으로 비활성화되어 있습니다.
압축을 활성화하면 테이블 최적화 탭에 다음과 같은 압축 세부 정보가 표시됩니다(약 15~20분 후).
-
시작 시각 - Lake Formation 내에서 압축 공정이 시작된 시각. 값은 UTC 시간으로 표시된 타임스탬프입니다.
-
종료 시각 - Lake Formation에서 컴팩션 공정이 종료된 시간입니다. 값은 UTC 시간으로 표시된 타임스탬프입니다.
-
상태 - 압축 실행의 상태입니다. 값은 성공 또는 실패입니다.
-
압축된 파일 - 압축된 총 파일 수입니다.
-
압축된 바이트 - 압축된 총 바이트 수입니다.
압축 비활성화
AWS Glue 콘솔 또는 AWS CLI를 사용하여 특정 Apache Iceberg 테이블에 대한 자동 압축을 비활성화할 수 있습니다.
압축 세부 정보 보기
AWS Glue 콘솔이나 AWS CLI 또는 AWS API 작업을 사용하여 Apache Iceberg의 압축 상태를 볼 수 있습니다.
Amazon CloudWatch 지표 보기
압축을 성공적으로 실행한 후 서비스는 압축 작업 성능에 대한 Amazon CloudWatch 지표를 생성합니다. CloudWatch콘솔로 이동하여 지표, 모든 지표를 선택할 수 있습니다. 특정 네임스페이스(예: AWS Glue), 테이블 이름 또는 데이터베이스 이름을 기준으로 지표를 필터링할 수 있습니다.
자세한 내용은 Amazon CloudWatch 사용 설명서의 사용 가능한 지표 보기를 참조하세요.
-
압축된 바이트 수
-
압축된 파일 수
-
작업에 할당된 DPU 수
-
작업 기간(시간)
옵티마이저 삭제
AWS CLI 또는 AWS API 작업을 사용하여 테이블의 옵티마이저 및 관련 메타데이터를 삭제할 수 있습니다.
다음 AWS CLI 명령을 실행하여 테이블의 압축 기록을 삭제합니다.
aws glue delete-table-optimizer \ --catalog-id123456789012\ --database-nameiceberg_db\ --table-nameiceberg_table\ --type compaction
DeleteTableOptimizer 작업을 사용하여 테이블의 옵티마이저를 삭제합니다.
고려 사항 및 제한
데이터 압축은 다음을 지원합니다.
데이터 유형: 부울, 정수, 롱, 플로트, 더블, 문자열, 십진수, 날짜, 시간, 타임스탬프, 문자열, UUID, 바이너리
압축: std, gzip, snappy, 비압축
-
암호화: 데이터 압축은 기본 Amazon S3 암호화(SSE-S3) 및 서버 측 KMS 암호화(SSE-KMS)만 지원합니다.
-
빈 팩 압축
스키마 진화
대상 파일 크기가 있는 테이블 (쓰기). target-file-size-bytes 128MB ~ 512MB의 포함 범위 내에 있는 빙산 구성의 속성)
리전
아시아 태평양(도쿄)
아시아 태평양(서울)
아시아 태평양(뭄바이)
유럽(아일랜드)
유럽(프랑크푸르트)
미국 동부(버지니아 북부)
미국 동부(오하이오)
미국 서부(캘리포니아 북부)
-
기본 데이터를 저장하는 Amazon S3 버킷이 다른 계정에 있는 경우 데이터 카탈로그가 있는 계정에서 압축을 실행할 수 있습니다. 이렇게 하려면 압축 역할에 Amazon S3 버킷에 대한 액세스 권한이 필요합니다.
데이터 압축은 현재 다음을 지원하지 않습니다.
데이터 유형: 고정
압축: brotli, lz4
파티션 사양이 바뀌는 동안 파일을 압축합니다.
일반 정렬 또는 z순서 정렬
파일 병합 또는 삭제: 압축 프로세스에서는 관련된 삭제 파일이 있는 데이터 파일을 건너뜁니다.
-
교차 계정 테이블에서의 압축: 교차 계정 테이블에서는 압축을 실행할 수 없습니다.
-
교차 리전 테이블에서의 압축: 교차 리전 테이블에서는 압축을 실행할 수 없습니다.
리소스 링크에서 압축 활성화
Amazon S3 버킷에 대한 VPC 엔드포인트
