DPU 용량 계획 모니터링
AWS Glue의 작업 측정치를 사용하여 AWS Glue 작업을 확장하는 데 사용할 수 있는 데이터 처리 단위(DPU) 수를 추정할 수 있습니다.
참고
이 페이지는 AWS Glue 버전 0.9 및 1.0에만 적용됩니다. 최신 버전의 AWS Glue에는 용량 계획 시 추가 고려 사항을 적용하는 비용 절감 기능이 포함되어 있습니다.
프로파일링된 코드
다음 스크립트는 428개의 gzip 압축된 JSON 파일을 포함하는 Amazon Simple Storage Service(Amazon S3) 파티션을 읽습니다. 이 스크립트는 필드 이름에 변경할 매핑을 적용하고 변환한 후 다시 Amazon S3에 Apache Parquet 포맷으로 씁니다. 기본값에 따라 10개 DPU를 프로비저닝하고 이 작업을 실행할 수 있습니다.
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [input_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [(map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet")
AWS Glue 콘솔에서 프로파일링된 지표 시각화
작업 실행 1: 이 작업 실행에서는 클러스터에서 부족 프로비저닝된 DPU가 있는지 알아보는 방법을 보여줍니다. AWS Glue의 작업 실행 기능은 능동적으로 실행 중인 총 실행기 수, 완료된 단계 수, 그리고 최대 필요 실행기 수를 표시합니다.
최대 필요 실행기 수는 총 실행 중인 작업 수와 보류 작업 수를 합한 다음 실행기당 작업 수로 나누어서 계산합니다. 이 결과는 현재 부하를 충족하는 데 필요한 총 실행기 수를 나타내는 측정치입니다.
이와는 대조적으로, 능동적으로 실행 중인 실행기 수는 활성 Apache Spark 작업을 실행 중인 실행기 수를 측정합니다. 작업이 진행됨에 따라 최대 필요 실행기가 변경될 수 있으며 일반적으로 보류 작업 대기열이 축소되면서 작업 완료에 가까워질수록 줄어듭니다.
다음 그래프의 가로 빨간색 선은 최대 할당 실행기 수를 표시하며, 이는 작업에 할당하는 DPU 수에 따라 달라집니다. 이 경우, 작업 실행에 대해 10개 DPU를 할당합니다. 하나의 DPU는 관리용으로 예약되어 있습니다. 9개 DPU가 각각 실행기 두 개를 실행하며 실행기 하나가 Spark 드라이버용으로 예약되어 있습니다. Spark 드라이버는 기본 애플리케이션에서 실행됩니다. 그러므로 최대 할당 실행기 수는 2*9 - 1 = 17개입니다.
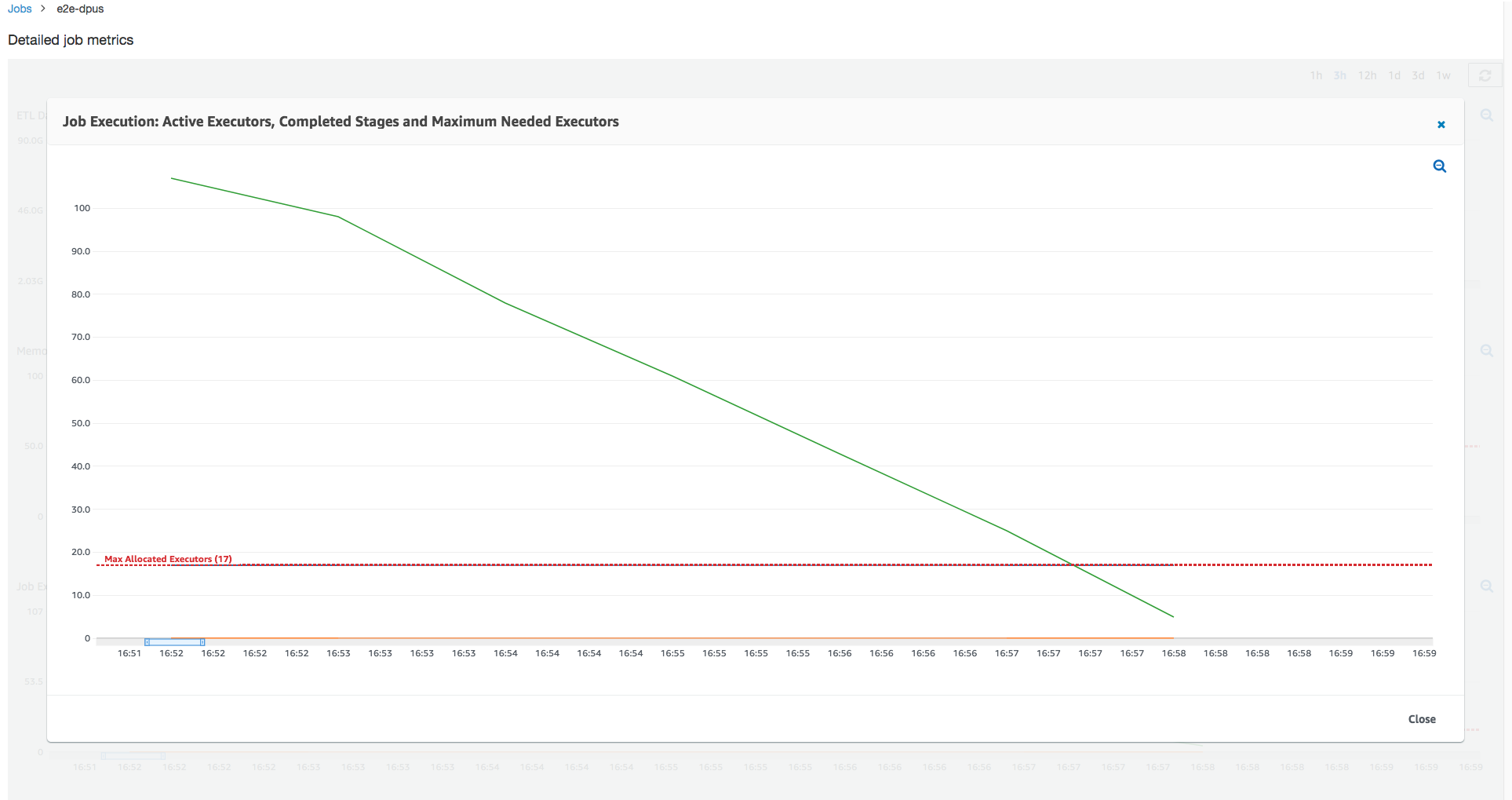
그래프가 표시될 때, 최대 필요 실행기 수는 작업 시작 시 107로 시작하지만, 활성 실행기 수는 17개로 유지됩니다. 이 개수는 DPU 수가 10개인 최대 할당 실행기 수와 동일합니다. 최대 필요 실행기 수와 최대 할당 실행기 수 간의 비율(Spark 드라이버에 대해 두 수치에 모두 1을 더함)은 부족 프로비저닝 계수를 제공합니다. 즉, 108/18 = 6x. 최대 병렬화로 실행하고 더 빨리 완료하도록 작업을 확장하기 위해 6(언더프로비저닝 비율)*9(현재 DPU 용량 - 1) + DPU 1개 = DPU 55개를 프로비저닝할 수 있습니다.
AWS Glue 콘솔은 자세한 작업 지표를 원래 할당된 최대 실행기 수를 나타내는 정적 행으로 표시합니다. 이 콘솔은 지표에 대한 작업 정의에서 할당된 최대 실행기를 계산합니다. 반면 자세한 작업 실행 지표의 경우 이 콘솔은 작업 실행 구성에서 할당된 최대 실행기, 특히 작업 실행에 대해 할당된 DPU를 계산합니다. 개별 작업 실행에 대한 지표를 보려면 작업 실행을 선택하고 View run metrics(실행 지표 보기)를 선택합니다.

읽고 쓴 Amazon S3 바이트를 살펴보면 작업이 Amazon S3에서 데이터를 스트리밍하고 병렬로 쓰는 데 6분을 모두 소비함을 알 수 있습니다. 할당된 DPU의 모든 코어가 Amazon S3에(서) 읽고 쓰고 있습니다. 최대 필요 실행기 수(107)는 입력 Amazon S3 경로의 파일 수(428)와도 일치합니다. 각 실행기는 Spark 작업 네 개를 시작하여 네 개 입력 파일(JSON gzip 압축됨)을 처리할 수 있습니다.
최적 DPU 용량 결정
이전 작업 실행 결과에 따라, 총 할당된 DPU 수를 55로 늘리고 작업이 어떻게 수행되는지 알아볼 수 있습니다. 작업이 이전 소요 시간의 절반에 해당하는 3분 이내에 완료됩니다. 단기 실행 작업이므로 이 경우에는 작업 확장이 선형적이지 않습니다. 장기 지속 작업이나 다량의 작업을 포함하는 작업(최대 필요 실행기 수가 많음)은 선형에 가까운 DPU 확장 성능 가속화가 도움이 됩니다.

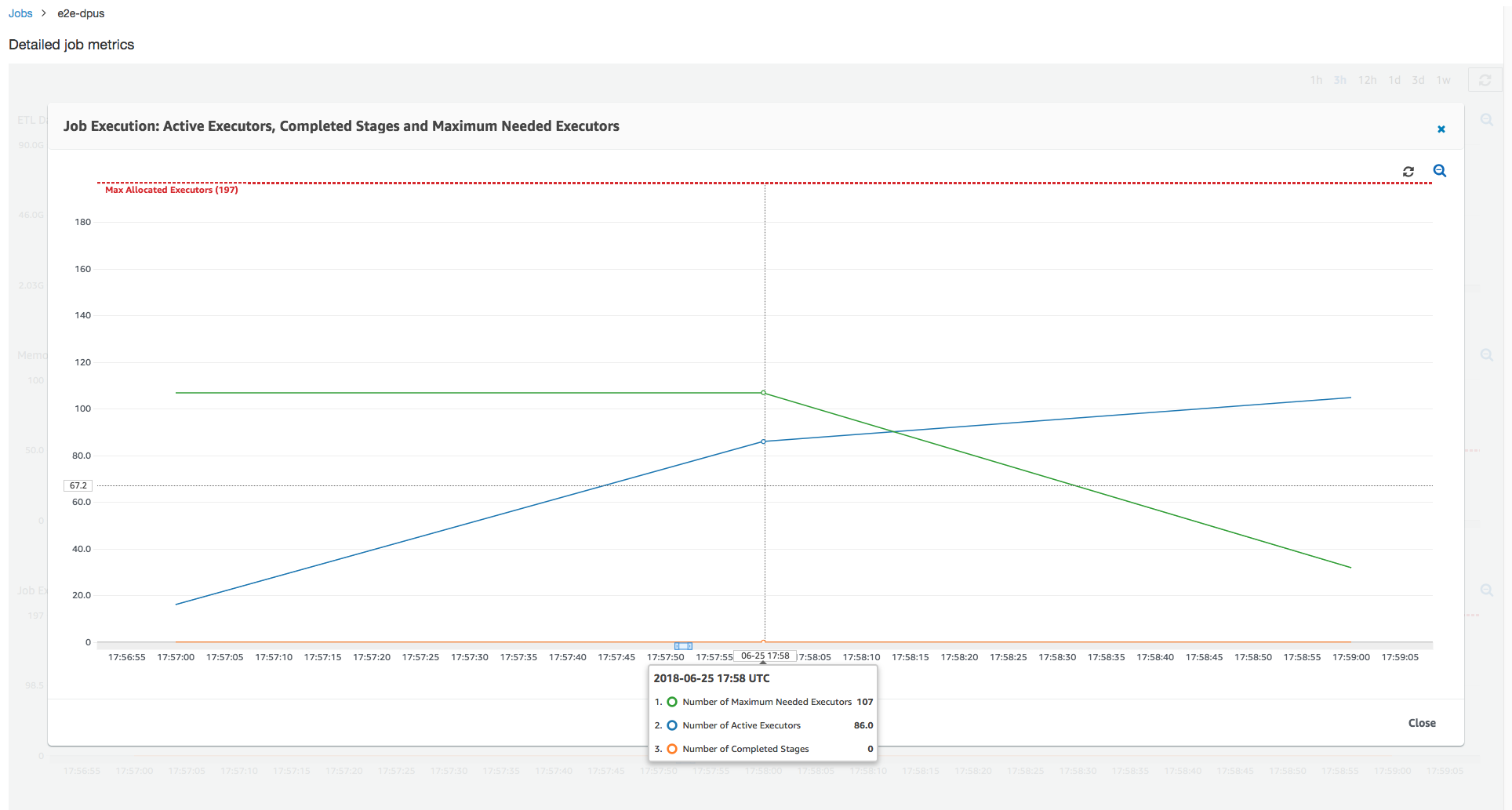
위 이미지에서 볼 수 있듯이 활성 실행기의 총 수는 할당된 최대값인 107개에 도달합니다. 마찬가지로, 최대 필요 실행기는 최대 할당 실행기 수보다 절대 높지 않습니다. 최대 필요 실행기 수는 능동적으로 실행 중인 작업 수와 보류 중인 작업 수에서 계산되므로 활성 실행기 수보다 작을 수도 있습니다. 이는 짧은 시간 동안 부분적으로 또는 전체적으로 유휴 상태이거나 아직 폐기되지 않은 실행기가 있을 수 있기 때문입니다.
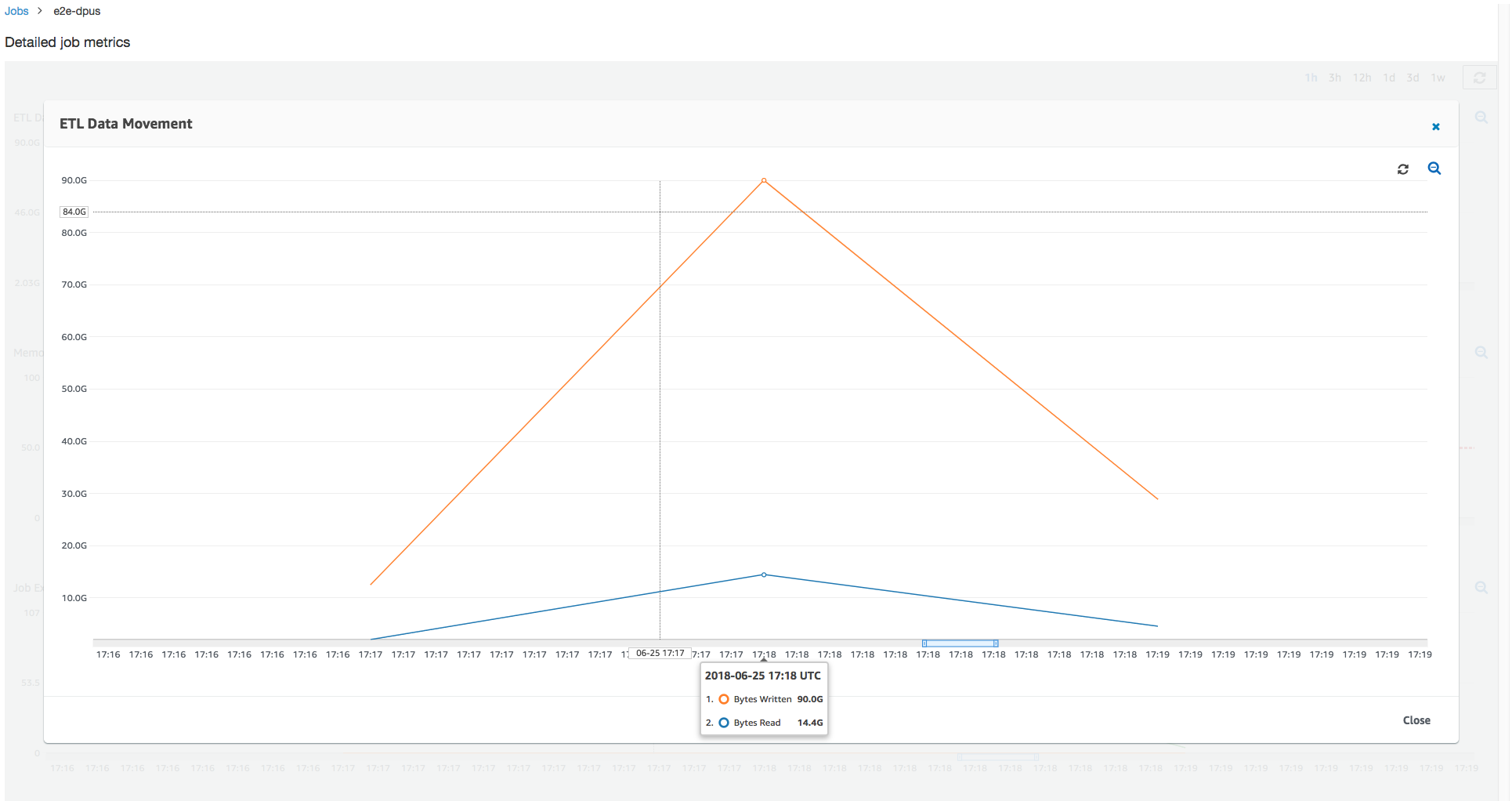
이 작업 실행은 6x 이상의 실행기를 사용하여 Amazon S3에서 데이터를 동시에 읽고 씁니다. 결과적으로 이 작업은 읽기 및 쓰기에 모두 더 많은 Amazon S3 대역폭을 사용하여 더 빨리 완료합니다.
과다 프로비저닝된 DPU 식별
다음에는, DPU가 100개(99 * 2 = 198개 실행기)인 작업을 확장하는 것이 성능을 향상하는 데 도움이 되는지 여부를 결정할 수 있습니다. 다음 그래프와 같이, 작업을 완료하는 데 여전히 3분이 걸립니다. 마찬가지로, 이 작업은 실행기를 107 개 이상(55개 DPU 구성)으로 확장하지 않으며, 남은 91개 실행기가 과다 프로비저닝되고 전혀 사용되지 않습니다. 이는 최대 필요 실행기 수에서 분명히 알 수 있듯이 DPU 수를 늘리는 것이 항상 성능을 향상시키지는 않을 수도 있음을 보여줍니다.
시간차 비교
다음 표에 나와 있는 세 가지 작업 실행은 10개 DPU, 55개 DPU 및 100개 DPU에 대한 작업 실행 시간을 요약한 것입니다. 첫 번째 작업 실행을 모니터링함으로써 설정한 추정치를 사용하여 작업 실행 시간을 개선할 DPU 용량을 찾아낼 수 있습니다.
| 작업 ID | DPU 수 | 실행 시간 |
|---|---|---|
| jr_c894524c8ef5048a4d9... | 10 | 6분 |
| jr_1a466cf2575e7ffe6856... | 55 | 3분 |
| jr_34fa1ed4c6aa9ff0a814... | 100 | 3분 |
