기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
여러 작업의 진행 상황 모니터링
여러 AWS Glue 작업을 함께 프로파일링하고 작업 간에 데이터 흐름을 모니터링할 수 있습니다. 이 모니터링은 일반적인 워크플로우 패턴으로, 개별 작업 진행 상황, 데이터 처리 백로그, 데이터 재처리 및 작업 북마크를 모니터링해야 합니다,
프로파일링된 코드
이 워크플로우에는 두 가지 작업, 즉 입력 작업과 출력 작업이 있습니다. 입력 작업은 정기 트리거를 사용하여 30분마다 실행하도록 예약되어 있습니다. 출력 작업은 입력 작업의 각각의 성공적인 실행 이후에 실행하도록 예약되어 있습니다. 이러한 예약된 작업은 작업 트리거를 사용하여 제어됩니다.

입력 작업: 이 작업은 Amazon Simple Storage Service(Amazon S3) 위치에서 데이터를 읽고 ApplyMapping을 사용하여 변환한 다음, 스테이징 Amazon S3 위치에 씁니다. 다음 코드는 입력 작업용으로 프로파일링된 코드입니다.
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": ["s3://input_path"], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": staging_path, "compression": "gzip"}, format = "json")
출력 작업: 이 작업은 Amazon S3의 스테이징 위치에서 입력 작업의 출력을 읽고. 다시 변환한 다음, 대상에 씁니다.
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "json")
AWS Glue 콘솔에서 프로파일링된 지표 시각화
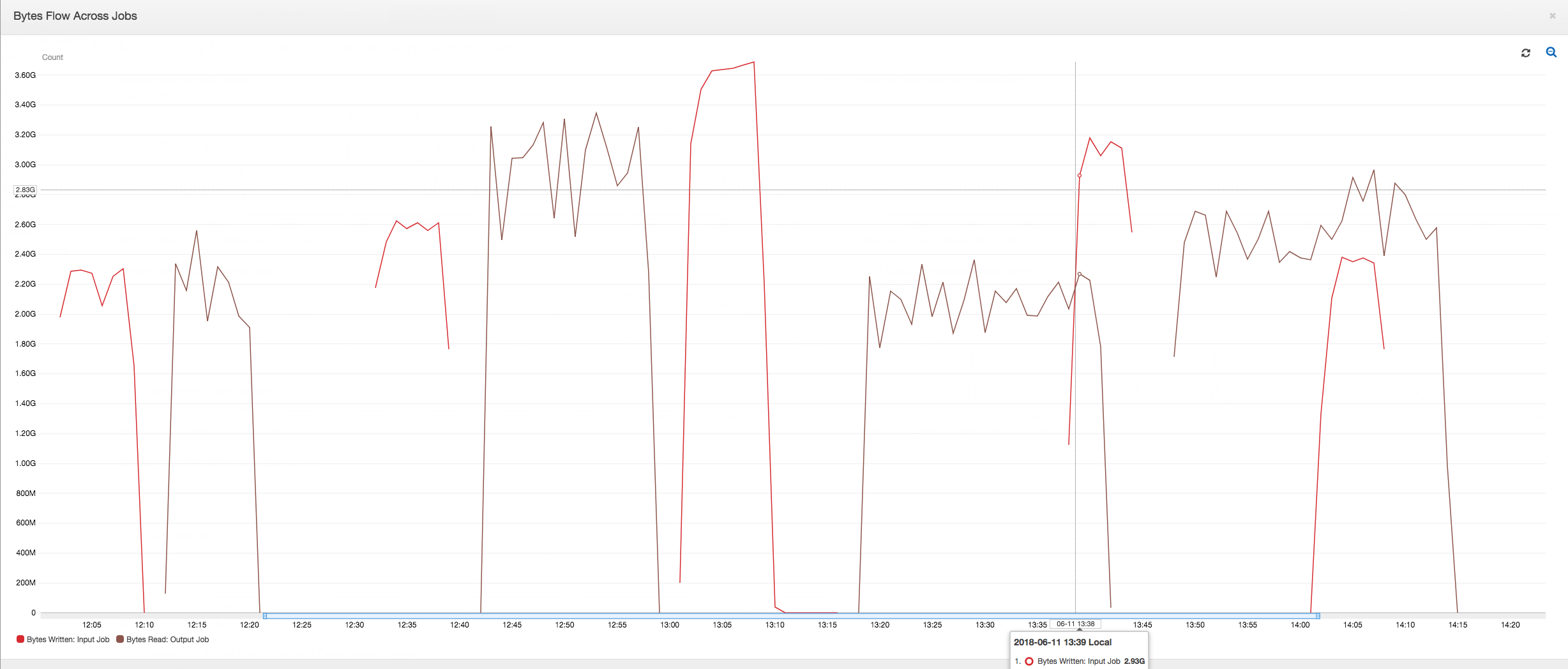
다음 대시보드는 출력 작업에 대한 동일한 타임라인에서 입력 작업의 Amazon S3 바이트 쓰기 지표를 Amazon S3 바이트 읽기 지표에 중첩합니다. 이 타임라인은 입력 작업과 출력 작업의 서로 다른 작업 실행을 보여줍니다. 입력 작업(빨간색으로 표시됨)이 30분마다 시작됩니다. 출력 작업(갈색으로 표시됨)은 입력 작업 완료 시 시작되며, 최대 동시성은 1입니다.
이 예에서는, 작업 북마크가 활성화되지 않습니다. 변환 컨텍스트를 사용하여 스크립트 코드에서 작업 북마크를 활성화하지 않습니다.
작업 기록: 입력 및 출력 작업은 오후 12:00부터 시작되는 기록 탭에서처럼 여러 번 실행되었습니다.
AWS Glue 콘솔의 입력 작업은 다음과 같습니다.

다음 이미지는 출력 작업을 보여줍니다.

첫 번째 작업 실행: 아래 읽고 쓴 데이터 바이트 그래프에서처럼, 12:00 ~ 12:30의 입력 및 출력 작업의 첫 번째 작업 실행은 거의 동일한 곡선하 면적을 보입니다. 이 면적은 입력 작업에서 쓴 Amazon S3 바이트와 출력 작업에서 읽은 Amazon S3 바이트를 나타냅니다. 또한 이 데이터는 작성된 Amazon S3 바이트의 비율(30분 동안의 합계 - 입력 작업의 경우 작업 트리거 빈도)로 확인됩니다. 오후 12:00에 시작된 입력 작업 비율의 데이터 지점도 1입니다.
다음 그래프는 모든 작업 실행에 대한 데이터 흐름 비율을 보여줍니다.
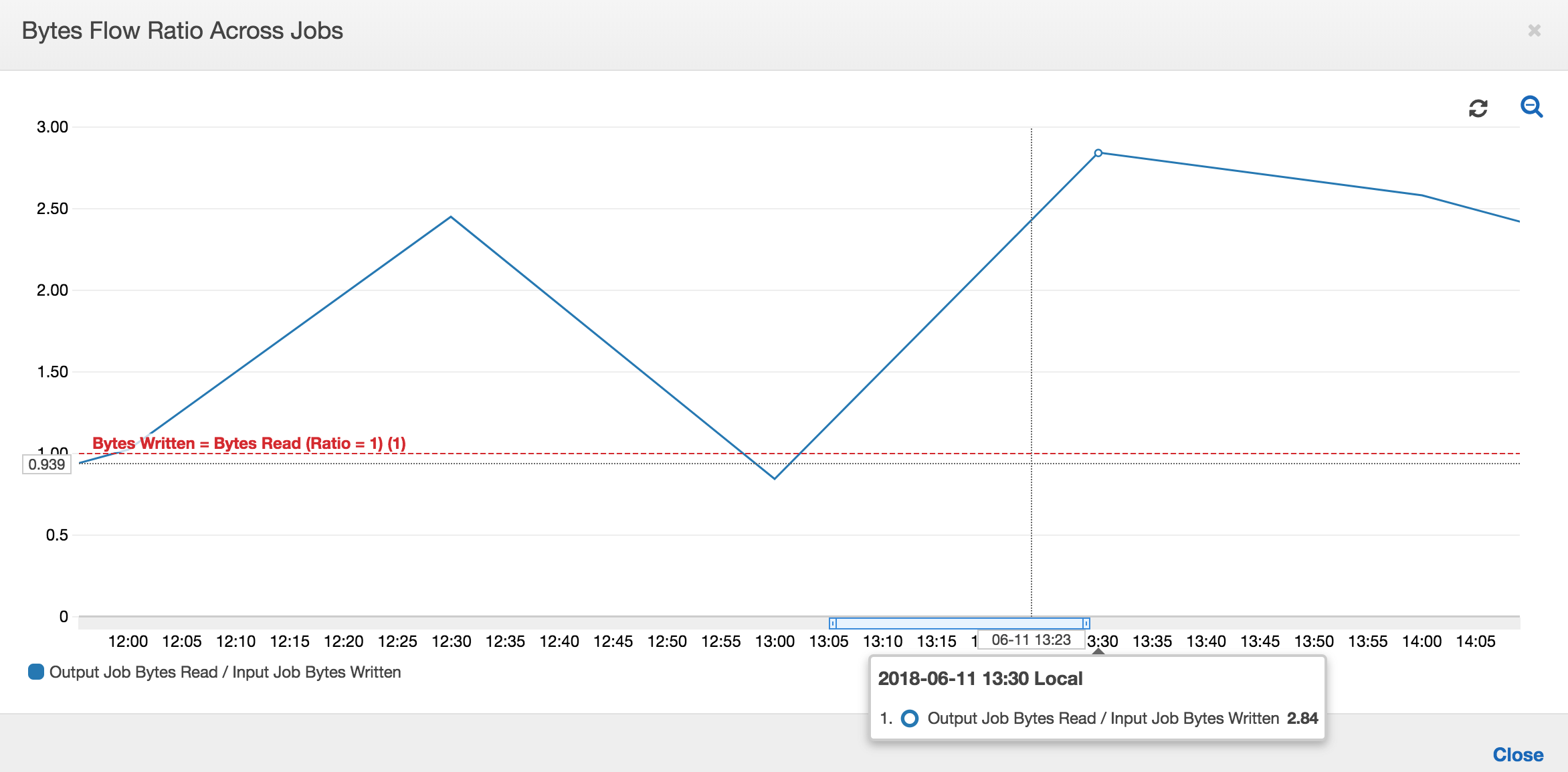
두 번째 작업 실행: 두 번째 작업 실행에서 입력 작업에서 쓴 바이트 수와 출력 작업에서 읽은 바이트 수 사이에는 명확한 차이가 있습니다. (출력 작업에 대한 두 작업 실행의 곡선하 면적을 비교하거나, 입력 작업과 출력 작업의 두 번째 실행 시 면적을 비교합니다.) 읽은 바이트 수와 쓴 바이트 수의 비율은 12:30 ~ 13:00의 두 번째 기간인 30분 동안 입력 작업에 의해 작성된 데이터의 약 2.5배를 출력 작업에서 읽었음을 보여줍니다. 이는 작업 북마크가 활성화되지 않았기 때문에 출력 작업이 입력 작업의 첫 번째 작업 실행에서 나오는 출력을 재처리하기 때문입니다. 비율이 1보다 크면 출력 작업에 의해 데이터의 추가 백로그가 처리되었음을 의미합니다.
세 번째 작업 실행: 입력 작업은 작성된 바이트 수 면에서 일관성이 거의 유지됩니다(빨간색 곡선하 면적 참조). 하지만, 입력 작업의 세 번째 작업 실행 시간이 예상보다 더 길어졌습니다(빨간색 곡선의 긴 후미부 참조). 결과적으로 출력 작업의 세 번째 작업 실행이 늦게 시작되었습니다. 세 번째 작업은 13:00 ~ 13:30의 나머지 30분 동안 스테이징 위치에 누적된 데이터 부분만 처리했습니다. 바이트 흐름의 비율은 입력 작업의 세 번째 작업 실행에 의해 작성된 데이터의 0.83만 처리되었음을 보여줍니다(13:00의 비율 참조).
입력 작업과 출력 작업의 중첩: 입력 작업의 네 번째 작업 실행이 출력 작업의 세 번째 작업 실행이 완료되기 전에 일정에 따라 13:30에 시작되었습니다. 두 작업 실행 사이에 약간의 중첩 부분이 있습니다. 하지만, 출력 작업의 세 번째 작업 실행은 약 13:17에 시작되었을 때 Amazon S3의 스테이징 위치에 나열되어 있는 파일만 캡처합니다. 캡처 데이터는 입력 작업의 첫 번째 작업 실행에서 얻은 모든 데이터 출력으로 구성됩니다. 13:30에서 실제 비율은 약 2.75입니다. 출력 작업의 세 번째 작업 실행에서는 13:30~14:00의 입력 작업 중 네 번째 작업 실행에서 작성된 데이터의 약 2.75x를 처리했습니다.
이러한 이미지에 표시된 바와 같이, 출력 작업은 입력 작업에 대한 모든 이전 작업 실행의 스테이징 위치부터 데이터를 처리하고 있습니다. 결과적으로, 출력 작업에 대한 네 번째 작업 실행이 가장 길며 입력 작업의 전체 다섯 번째 작업 실행과 겹칩니다.
파일 처리 수정
출력 작업에서 출력 작업의 이전 작업 실행에 의해 처리되지 않은 파일만 처리하도록 해야 합니다. 이렇게 하려면 다음과 같이 출력 작업에서 작업 북마크를 활성화하고 변환 컨텍스트를 설정합니다.
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json", transformation_ctx = "bookmark_ctx")
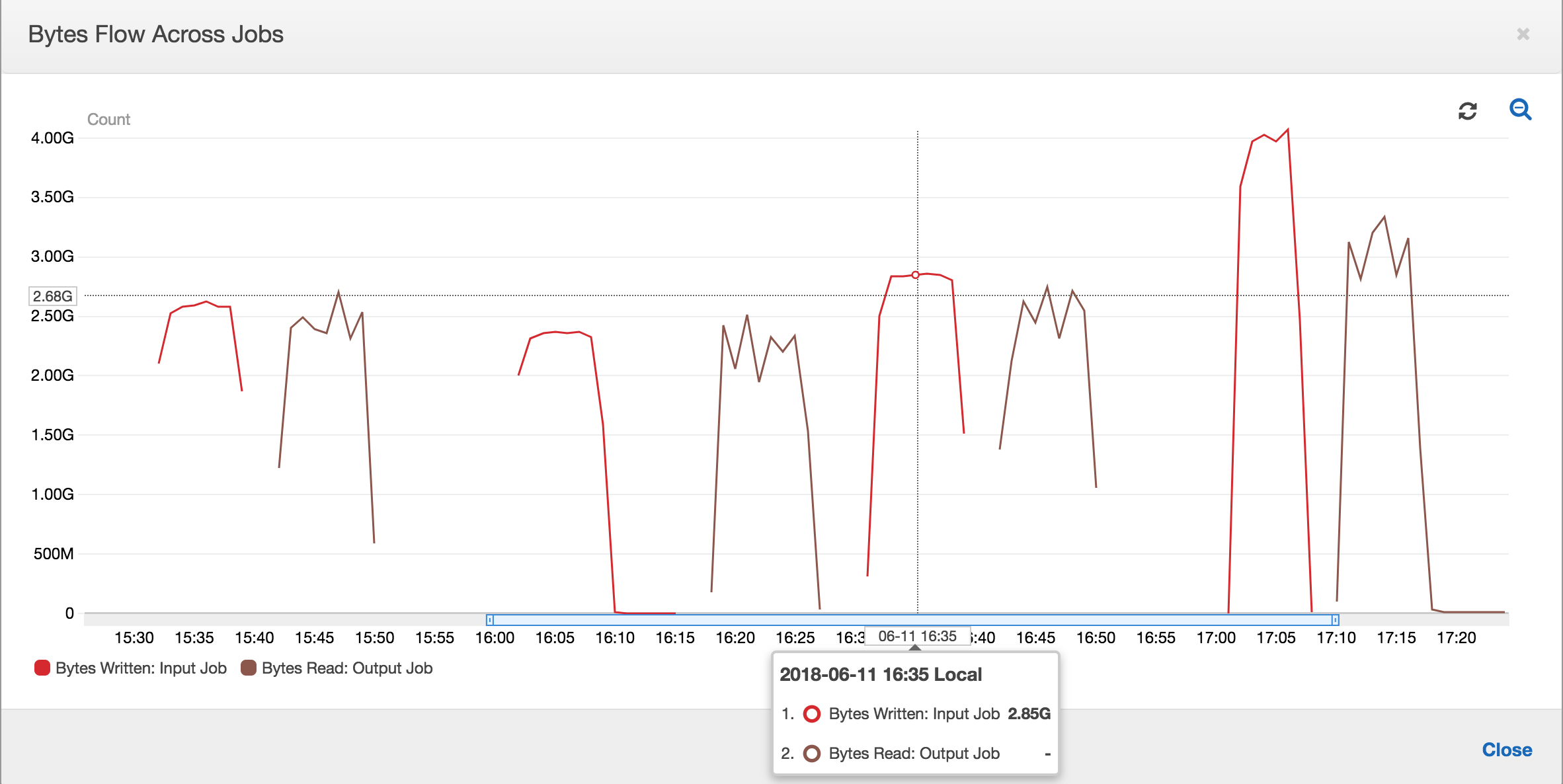
작업 북마크를 활성화한 상태에서는 출력 작업이 입력 작업에 대한 모든 이전 작업 실행의 스테이징 위치에 있는 데이터를 재처리하지 않습니다. 읽고 쓴 데이터를 보여주는 다음 이미지에서는 갈색 곡선하 면적이 상당히 일관되며 빨간 곡선과 비슷합니다.
추가 데이터 처리가 없으므로 바이트 흐름의 비율도 거의 1에 가깝게 유지됩니다.
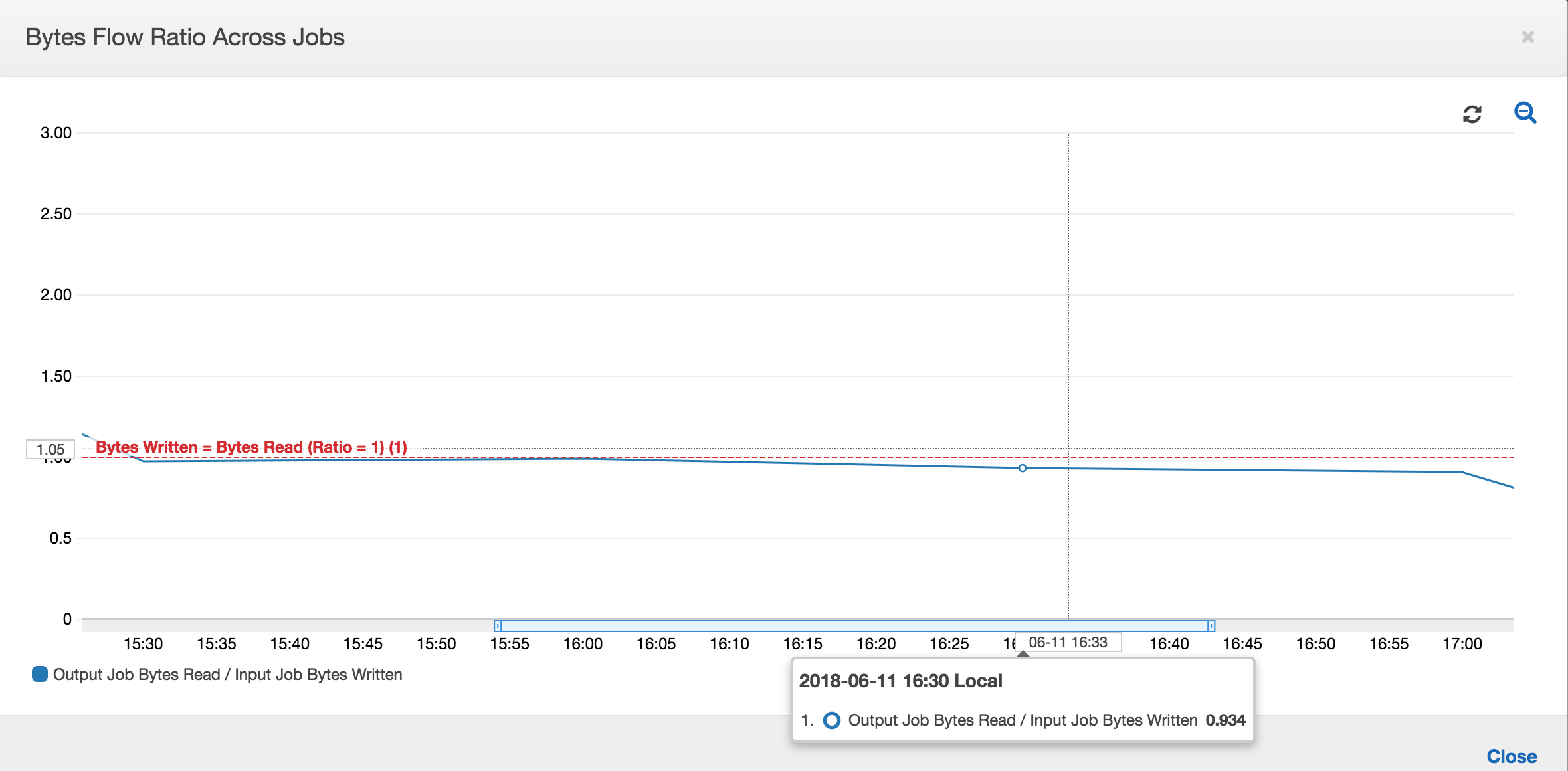
다음 입력 작업 실행이 시작되기 전에 출력 작업에 대한 작업 실행이 시작되고 스테이징 위치에 있는 파일을 캡처하여 더 많은 데이터를 스테이징 위치에 넣습니다. 이 작업이 계속되는 동안은 이전 입력 작업 실행에서 캡처한 파일만 처리되며 비율이 계속 1에 가깝게 유지됩니다.
입력 작업이 예상보다 길어지며, 그 결과로서 출력 작업이 두 입력 작업 실행의 스테이징 위치에 있는 파일을 캡처한다고 가정해 보겠습니다. 그러면 해당 출력 작업 실행에 대해 비율이 1보다 높습니다. 하지만, 출력 작업의 다음 작업 실행에서는 출력 작업의 이전 작업 실행에 의해 이미 처리된 파일이 하나도 처리되지 않습니다.
