OOM 예외 사항 및 작업 이상 현상 디버깅
AWS Glue에서 메모리 부족(OOM) 예외 사항 및 작업 이상 현상을 디버깅할 수 있습니다. 다음 단원에서는 Apache Spark 드라이버 또는 Spark 실행기의 메모리 부족 예외 사항을 디버깅하는 시나리오를 설명합니다.
드라이버 OOM 예외 사항 디버깅
이 시나리오에서는 Spark 작업이 Amazon Simple Storage Service(Amazon S3)에서 여러 작은 파일을 읽습니다. 파일을 Apache Parquet 포맷으로 변환한 다음 Amazon S3에 씁니다. Spark 드라이버에서 메모리 부족이 발생합니다. 입력 Amazon S3 데이터의 파일 수는 서로 다른 Amazon S3 파티션에 걸쳐 100만개가 넘습니다.
프로파일링된 코드는 다음과 같습니다.
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
AWS Glue 콘솔에서 프로파일링된 지표 시각화
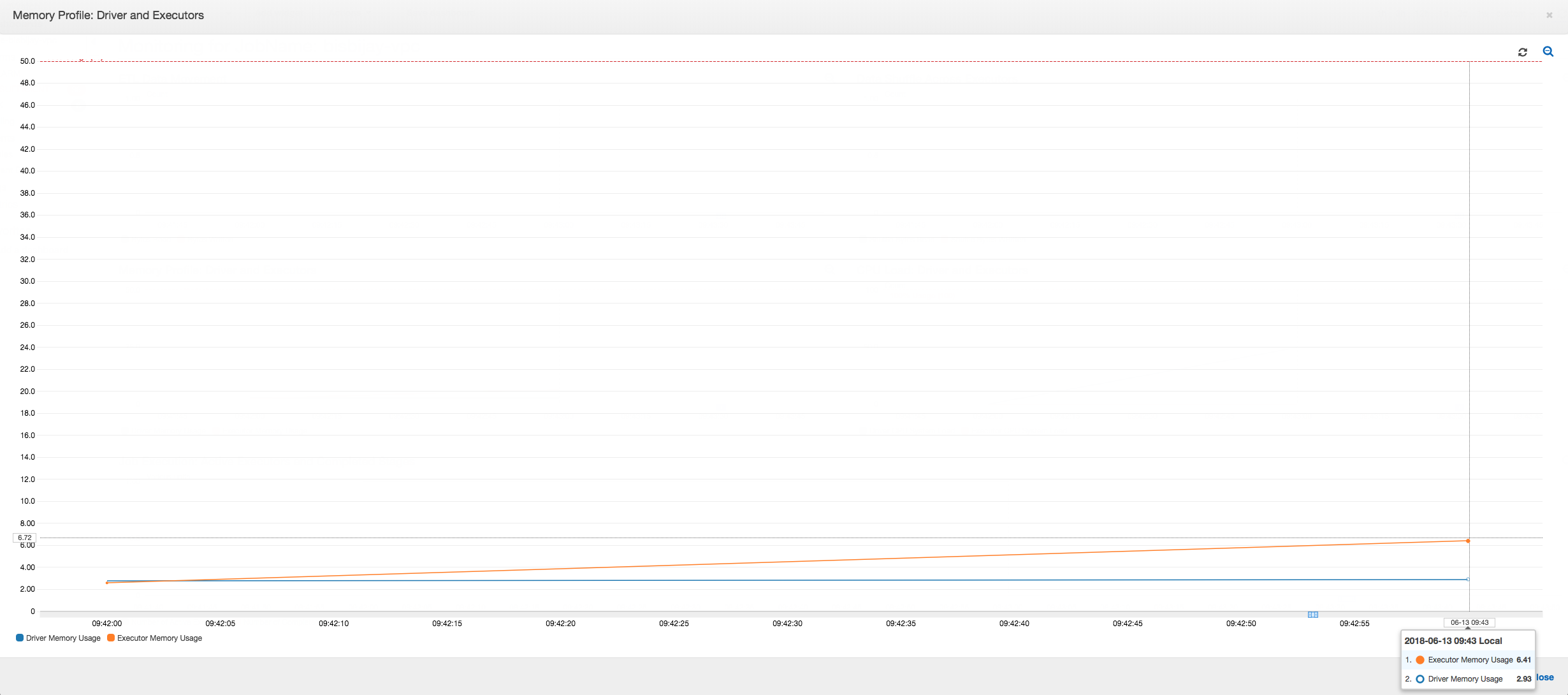
다음 그래프는 드라이버와 실행기에 대한 메모리 사용률(%)을 표시합니다. 이 사용률은 지난 1분 안에 보고된 값에 대한 평균으로 계산된 데이터 하나로 표시됩니다. 드라이버 메모리가 50% 사용률의 안전 임계값을 넘는 작업의 메모리 프로필을 볼 수 있습니다. 반면에, 모든 실행기의 평균 메모리 사용률은 여전히 4%보다 낮습니다. 이로써 이 Spark 작업에서 드라이버 실행에 이상이 있음을 명확히 알 수 있습니다.
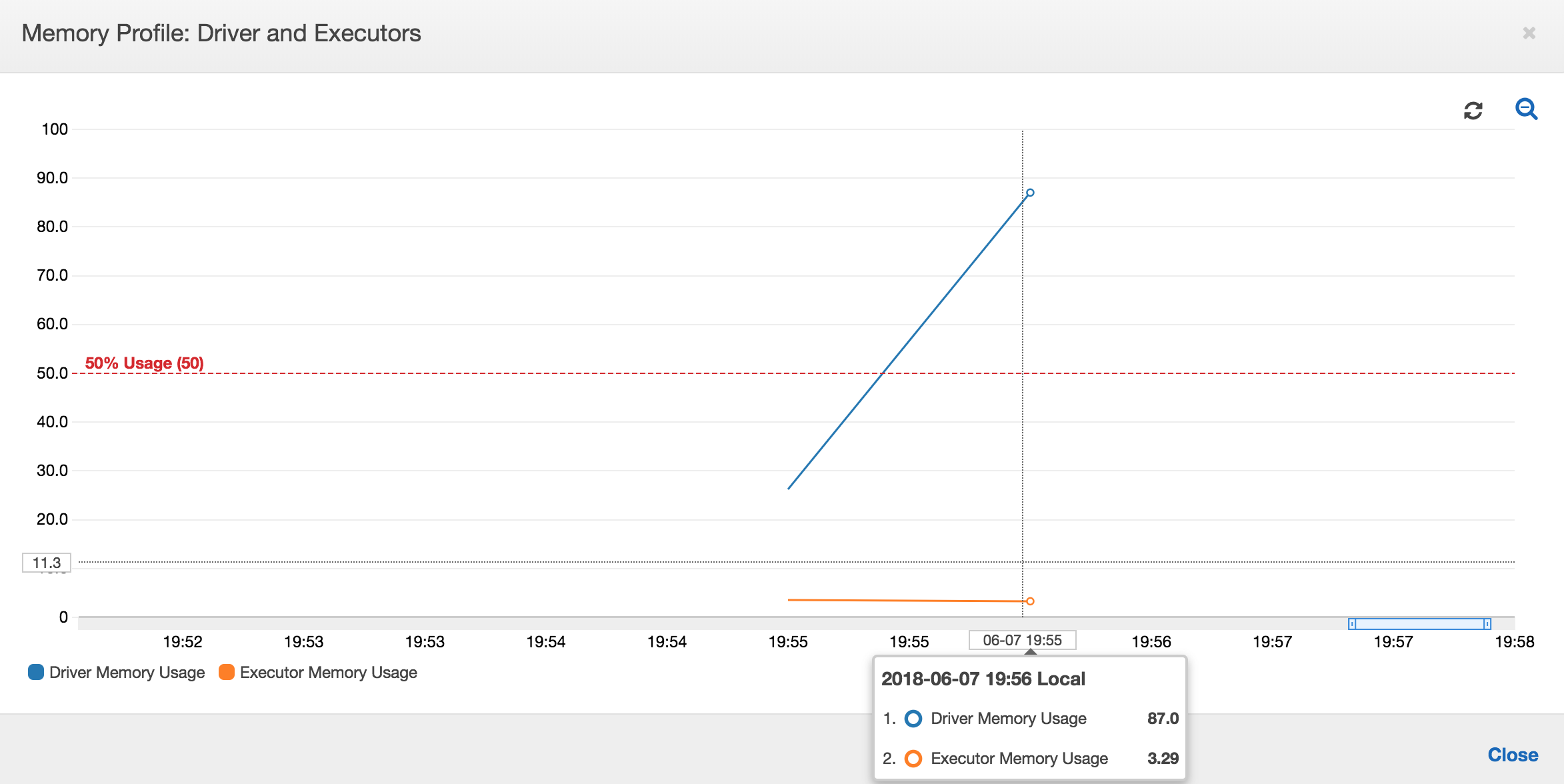
작업 실행이 곧 실패하고 AWS Glue 콘솔의 [기록(History)] 탭에 [종료 코드 1로 명령 실패(Command Failed with Exit Code 1)] 오류가 나타납니다. 이 오류 문자열은 시스템 전체 오류(이 경우 메모리 부족)로 인해 작업이 실패했음을 의미합니다.
콘솔의 [기록(History)] 탭에서 [오류 로그(Error logs)] 링크를 선택하여 CloudWatch Logs에서 드라이버 OOM에 대한 결과를 확인합니다. 작업의 오류 로그에서 "Error"를 검색하여 작업 실패의 원인이 된 OOM 예외 사항이 정말 발생했는지 확인합니다.
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
작업에 대해 기록 탭에서 로그를 선택합니다. 작업의 시작 부분에서 다음과 같은 CloudWatch Logs의 드라이버 실행 추적 정보를 찾아볼 수 있습니다. Spark 드라이버에서 모든 디렉터리의 모든 파일을 나열하려고 했으며, InMemoryFileIndex를 생성하고 파일마다 작업 하나를 실행합니다. 이로 인해 Spark 드라이버는 모든 작업을 추적하기 위해 메모리에서 매우 많은 상태를 유지해야 합니다. 따라서 메모리 내 인덱스에 대해 다량의 파일을 포함하는 전체 목록을 캐시하므로 드라이버 OOM이 발생하게 됩니다.
그룹화를 사용하여 여러 파일의 처리 수정
AWS Glue의 그룹화 기능을 사용하여 여러 파일의 처리를 수정할 수 있습니다. 그룹화는 동적 프레임을 사용할 때와 입력 데이터 세트에 파일 수가 많을 때(50,000개 초과) 자동으로 활성화됩니다. 그룹화를 통해 여러 파일을 그룹 하나로 합칠 수 있으므로 작업 하나로 단일 파일 대신에 전체 그룹을 처리할 수 있습니다. 결과적으로 Spark 드라이버는 메모리 안에 훨씬 더 적은 상태를 저장하여 몇 개 작업만 추적합니다. 데이터 세트에 대한 그룹화 수동 활성화에 대한 자세한 내용은 입력 파일을 더 큰 그룹에서 읽기 단원을 참조하십시오.
AWS Glue 작업의 메모리 프로파일을 확인하려면 그룹화가 활성화된 상태에서 다음과 같은 코드를 프로파일링합니다.
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
AWS Glue 작업 프로필에서 메모리 프로필 및 ETL 데이터 이동을 모니터링할 수 있습니다.
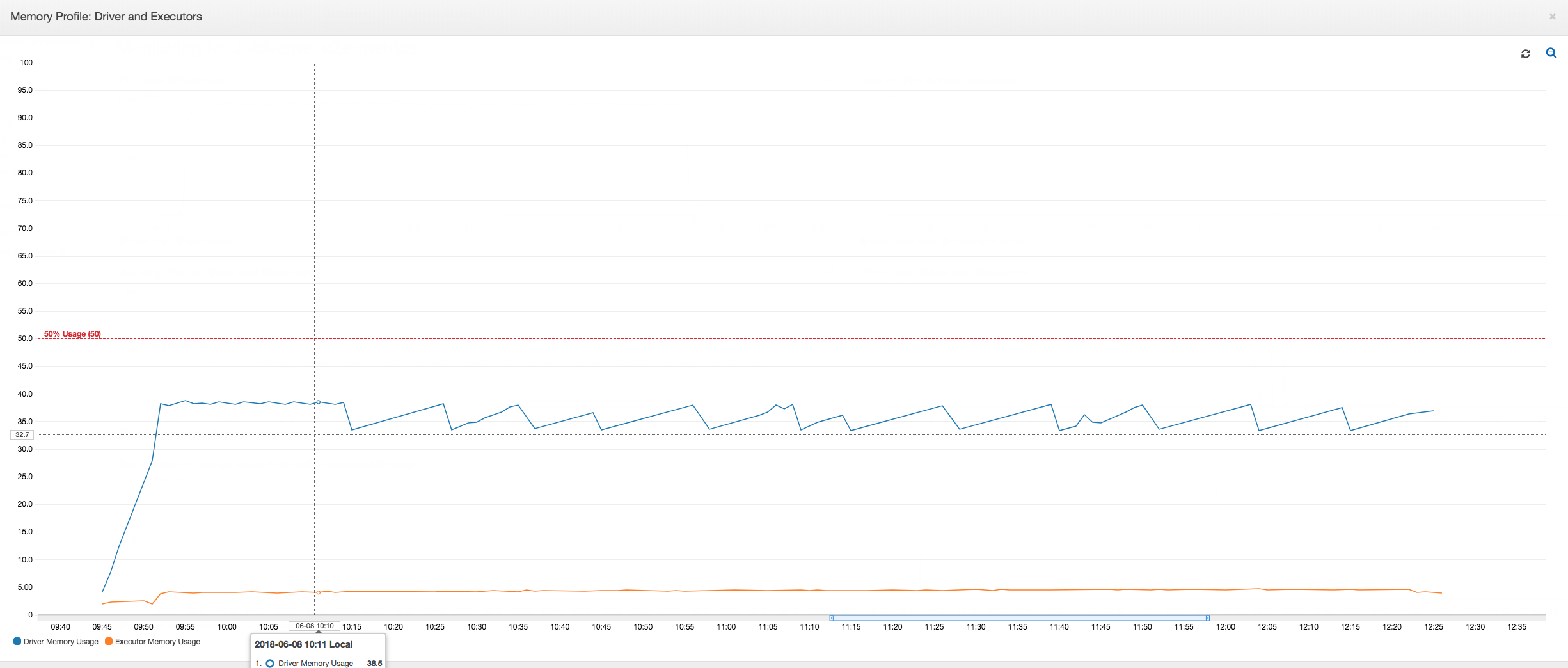
이 드라이버는 AWS Glue 작업의 전체 기간 동안 메모리 사용량의 50%인 임계값 미만으로 실행됩니다. 실행기가 Amazon S3에서 데이터를 스트리밍하고 처리한 후 Amazon S3에 씁니다. 결과적으로 모든 시점에서 5%보다 적은 양의 메모리가 사용됩니다.
아래 데이터 이동 프로파일은 작업이 진행됨에 따라 모든 실행기가 마지막 1분 동안 읽고 쓴 총 Amazon S3 바이트 수를 보여줍니다. 둘 다 모든 실행기에서 데이터가 스트리밍될 때 유사한 패턴을 따릅니다. 이 작업은 세 시간 내에 100만 개에 이르는 모든 파일에 대한 처리를 완료합니다.

실행기 OOM 예외 사항 디버깅
이 시나리오에서는 Apache Spark 실행기에서 발생할 수 있는 OOM 예외 사항을 디버깅하는 방법을 알아볼 수 있습니다. 다음 코드는 Spark MySQL 리더를 사용하여 약 3400만개 행으로 이루어진 대형 테이블을 Spark 데이터 프레임으로 읽어 들입니다. 그런 다음 Parquet 포맷으로 Amazon S3에 씁니다. 연결 속성을 제공하고 기본 Spark 구성을 사용하여 테이블을 읽을 수 있습니다.
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
AWS Glue 콘솔에서 프로파일링된 지표 시각화
메모리 사용량 그래프의 경사가 양수이고 50%를 넘는 경우 다음 지표를 내보내기 전에 작업이 실패하면 메모리 부족이 실패 원인이 될 수 있습니다. 다음 그래프는 1분 실행 기간 내에 모든 실행기의 평균 메모리 사용률이 50%를 급격하게 초과함을 보여줍니다. 이 사용률은 최대 92%에 도달하며 해당 실행기를 실행 중인 컨테이너가 Apache Hadoop YARN에 의해 중지됩니다.

다음 그래프에서처럼, 작업이 실패할 때까지 항상 단일 실행기가 실행 중입니다. 이는 새 실행기가 시작되어 중지된 실행기를 대체하기 때문입니다. JDBC 데이터 원본 읽기는 기본적으로 병렬화되지 않습니다. 그 이유는 한 열에서 테이블을 분할하고 여러 연결을 열어야 하기 때문입니다. 따라서 실행기 하나만 전체 테이블에서 순차적으로 읽혀집니다.
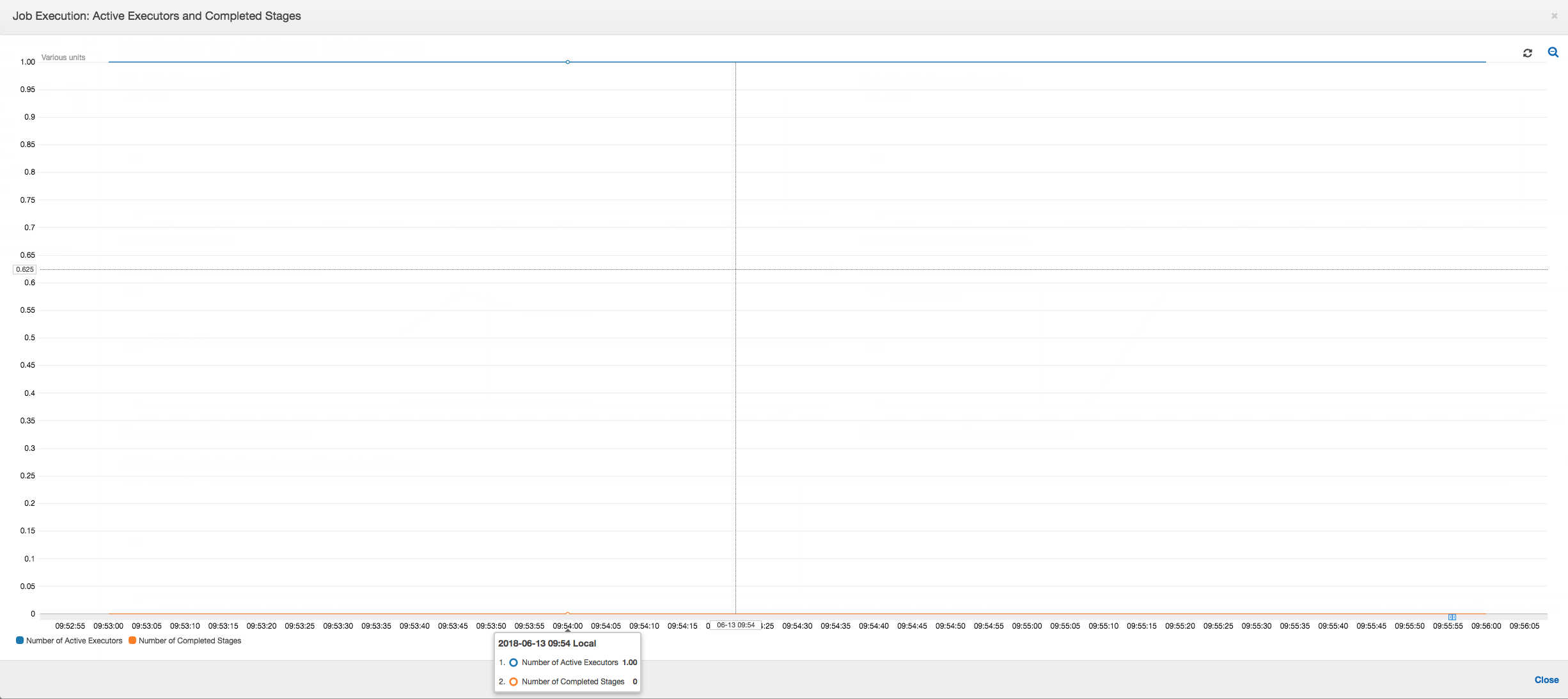
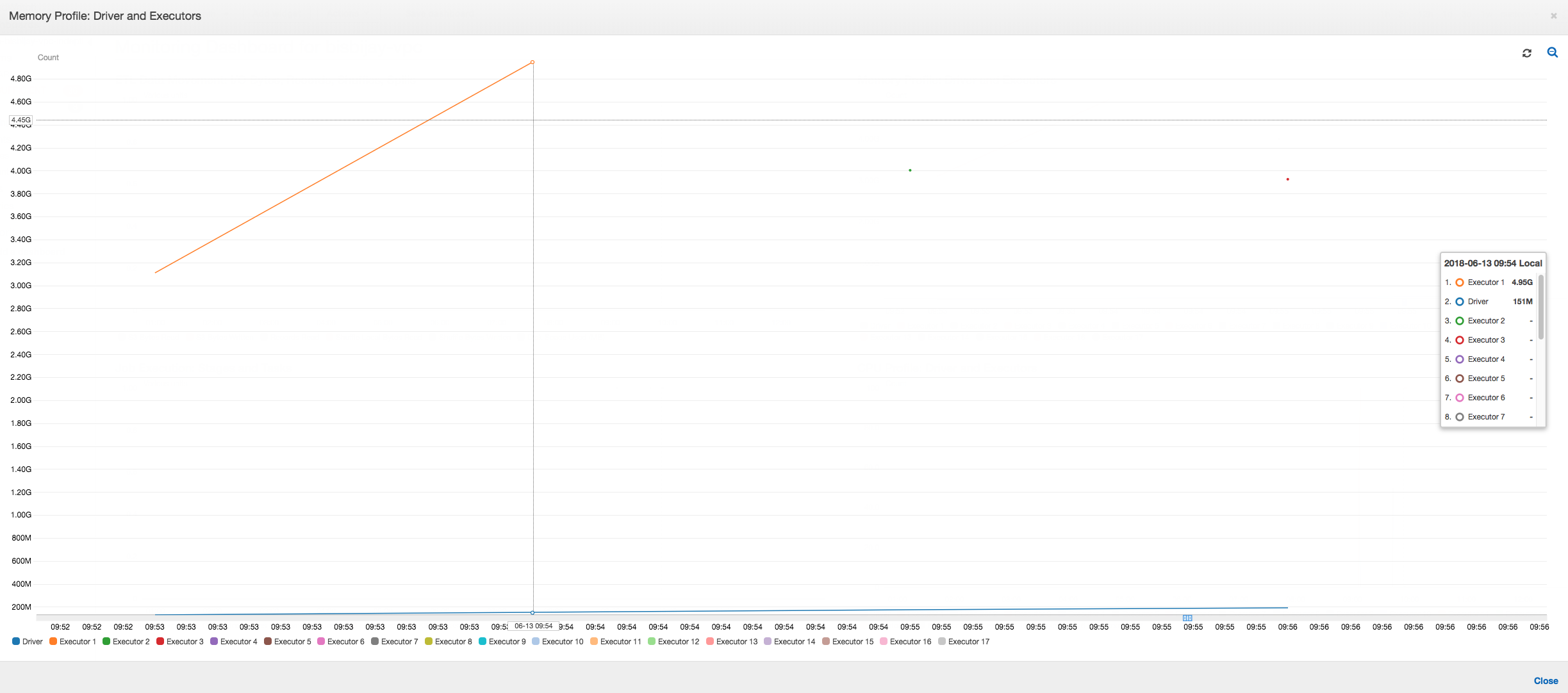
다음 그래프에서처럼, Spark는 작업 실패 전에 새 작업 시작을 4회 시도합니다. 세 개 실행기의 메모리 프로필을 볼 수 있습니다. 각 실행기가 모든 메모리를 신속히 소비합니다. 네 번째 실행기에서 메모리 부족이 발생하여 작업이 실패합니다. 따라서 이 작업의 측정치가 즉시 보고되지 않습니다.
다음 이미지와 같이, OOM 예외로 인해 작업이 실패했던 AWS Glue 콘솔에서 오류 문자열을 확인할 수 있습니다.

작업 출력 로그: 실행기 OOM 예외 사항의 결과를 추가로 확인하려면 CloudWatch Logs를 살펴봅니다. Error를 검색하면 지표 대시보드처럼 거의 동일한 기간 내에 네 개 실행기가 중지됨을 확인할 수 있습니다. 이들 실행기는 메모리 제한을 초과할 때 YARN에 의해 모두 종료됩니다.
실행기 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
실행기 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
실행기 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
실행기 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
AWS Glue 동적 프레임을 사용하여 가져오기 크기 설정 수정
Spark JDBC 가져오기 크기에 대한 기본 구성이 0이므로 JDBC 테이블을 읽는 동안 실행기에서 메모리 부족이 발생했습니다. 이는 Spark가 한 번에 한 개씩 행을 스트리밍하더라도 Spark 실행기의 JDBC 드라이버가 데이터베이스의 3400만개 행을 함께 가져와서 캐시하려고 함을 의미합니다. Spark에서 가져오기 크기 파라미터를 0 이외의 기본값으로 설정하여 이 시나리오를 방지할 수 있습니다.
또한 AWS Glue 동적 프레임을 대신 사용하여 이 문제를 해결할 수도 있습니다. 기본적으로 동적 프레임에서는 가져오기 크기로 1,000개 행이 사용되는데, 일반적으로 충분한 값입니다. 결과적으로 실행기에 사용되는 메모리의 양이 총 메모리의 7%를 초과하지 않습니다. AWS Glue 작업은 단일 실행기만으로 2분 안에 완료됩니다. AWS Glue 동적 프레임을 사용하는 것이 권장되는 접근 방식이지만, Apache Spark fetchsize 속성을 사용하여 가져오기 크기를 설정할 수도 있습니다. Spark SQL, DataFrames 및 데이터 세트 가이드
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
정상 프로파일링된 측정치: 실행기 메모리(AWS Glue 동적 프레임 사용)가 다음 이미지와 같이 안전 임곗값을 절대로 초과하지 않습니다. 데이터베이스에서 행을 읽고 어느 시점에든 JDBC 드라이버에 1,000개 행만 캐시합니다. 메모리 부족 예외는 발생하지 않습니다.