까다로운 단계와 스트래글러 작업 디버깅
AWS Glue 작업 프로파일링을 사용하여 추출, 변환 및 로드(ETL) 작업에서 까다로운 단계와 스트래글러 작업을 식별할 수 있습니다. 스트래글러 작업은 AWS Glue 작업의 단계에서 나머지 작업보다 더 오래 걸립니다. 따라서 해당 단계를 완료하는 데 더 오래 걸리므로 작업의 총 실행 시간도 지연됩니다.
작은 입력 파일을 큰 출력 파일로 병합
스트래글러 작업은 여러 작업들 간에 작업량이 균일하지 않게 배포되거나, 데이터 스큐로 인해 한 작업에서 더 많은 데이터를 처리하는 경우에 발생할 수 있습니다.
다음 코드(Apache Spark의 일반 패턴)를 프로파일링하여 다량의 작은 파일을 큰 출력 파일로 병합할 수 있습니다. 예를 들면, 입력 데이터 세트는 JSON Gzip 압축 파일 32GB입니다. 출력 데이터 세트는 거의 190GB에 이르는 압축되지 않은 JSON 파일입니다.
프로파일링된 코드는 다음과 같습니다.
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
AWS Glue 콘솔에서 프로파일링된 지표 시각화
작업을 프로파일링하여 네 가지 지표 세트를 살펴볼 수 있습니다.
-
ETL 데이터 이동
-
실행기 간의 데이터 셔플
-
작업 실행
-
메모리 프로필
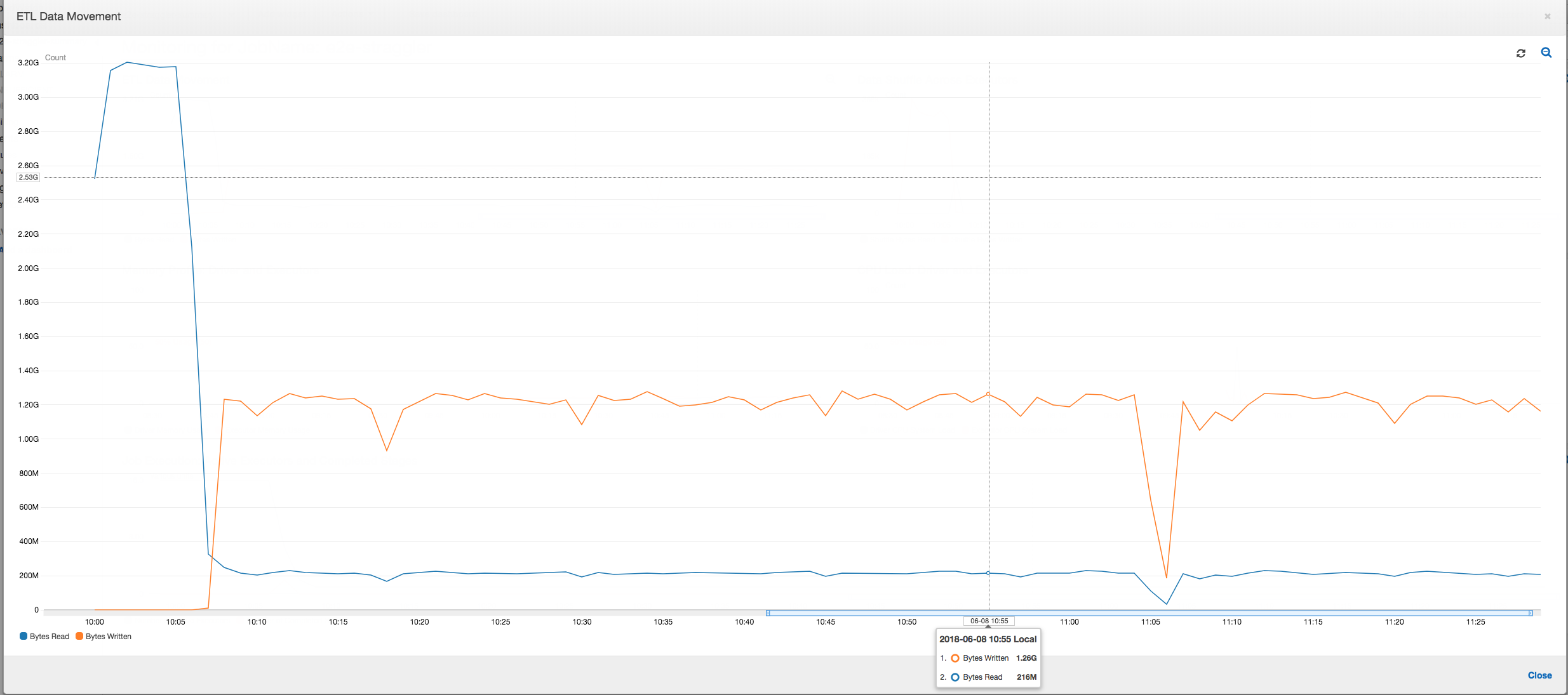
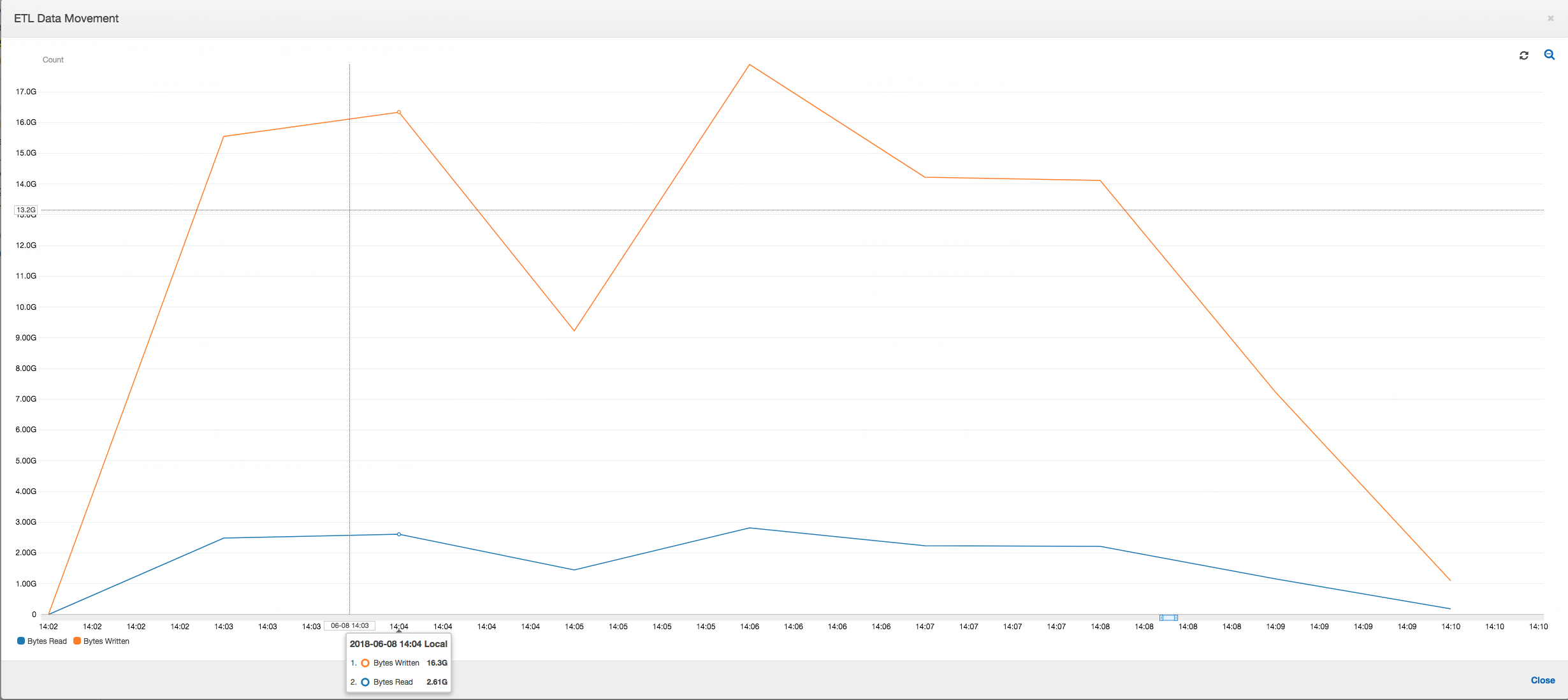
ETL 데이터 이동: ETL 데이터 이동 프로필에서는 처음 6분 안에 완료되는 첫 번째 단계에서 모든 실행기가 바이트를 매우 빠르게 읽습니다. 하지만 총 작업 실행 시간은 거의 1시간으로, 이 시간 중 대부분을 데이터 쓰기가 차지합니다.
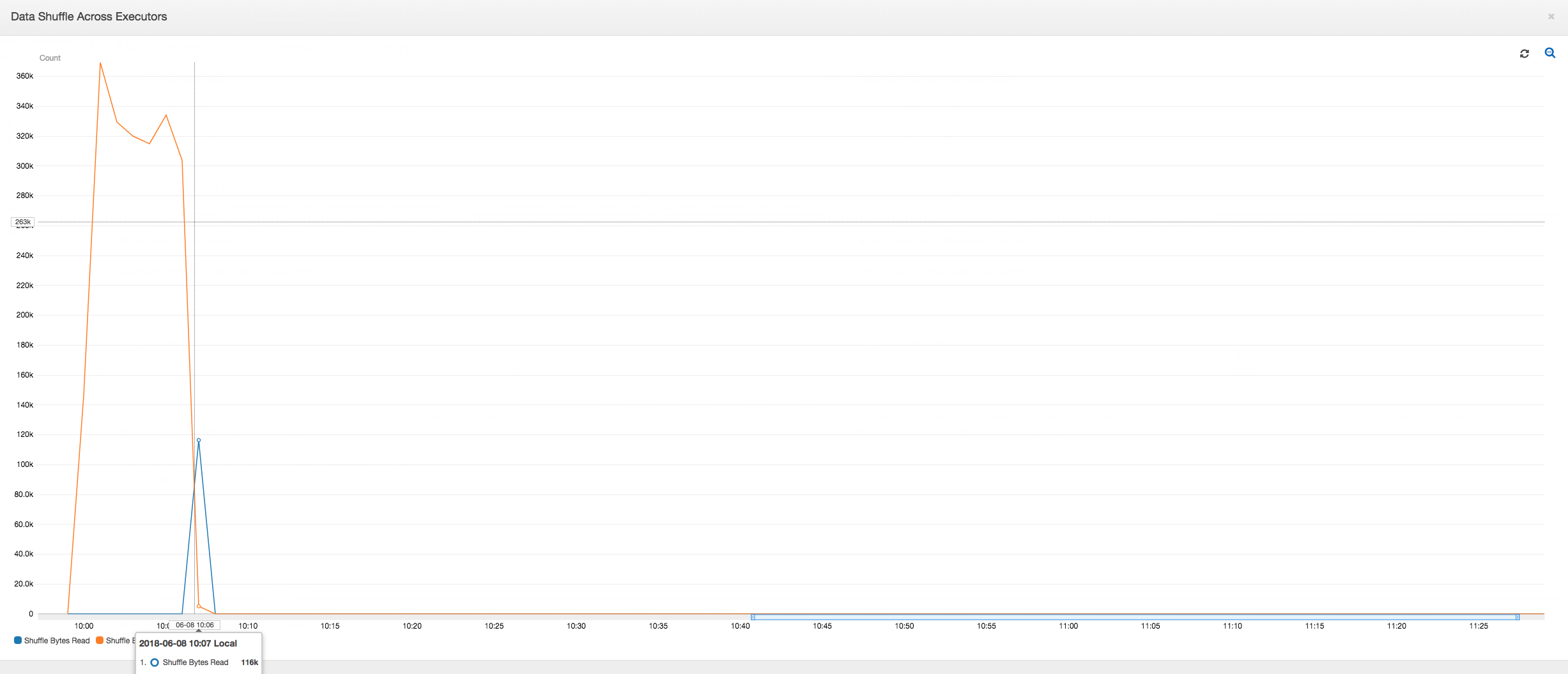
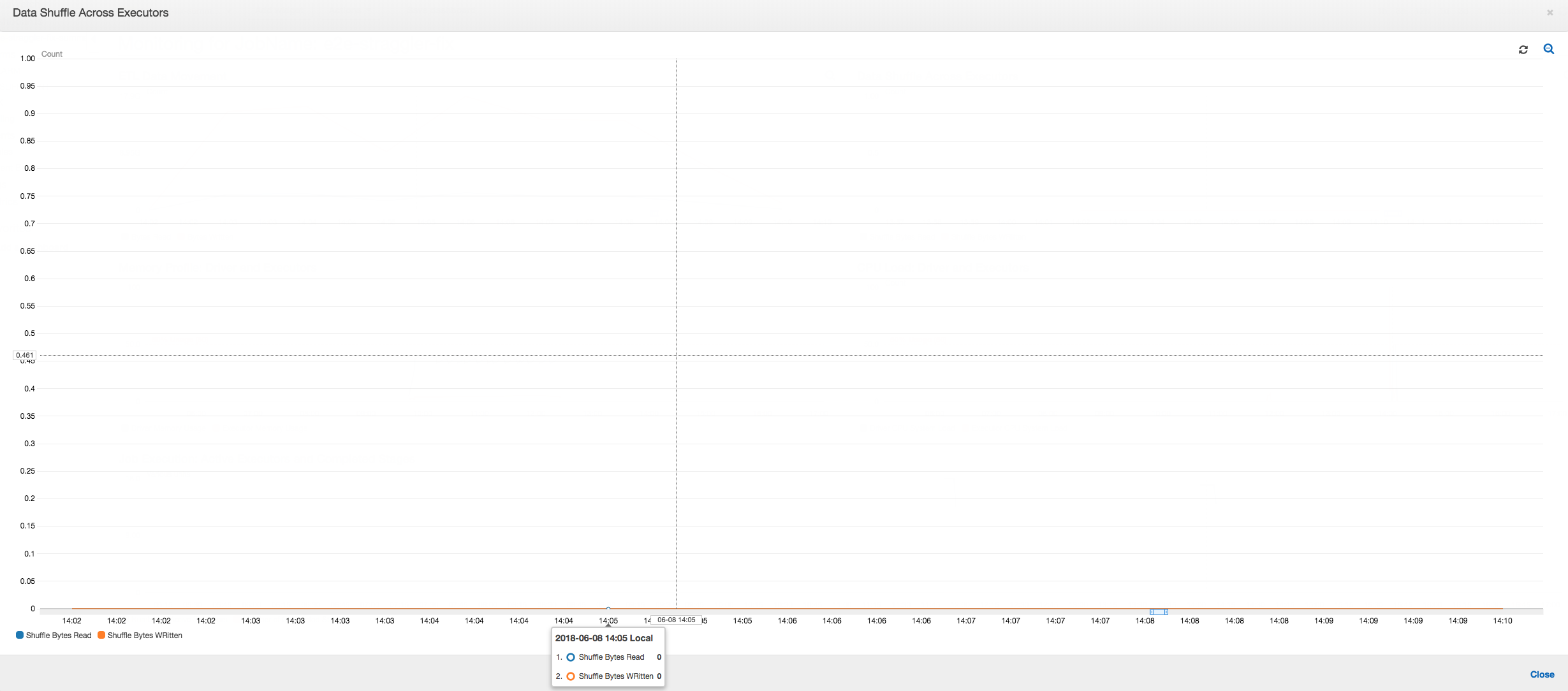
실행기 간 데이터 셔플: 셔플링 중에 읽고 쓴 바이트 수도 [작업 실행(Job Execution)] 및 [데이터 셔플(Data Shuffle)] 지표에서 알 수 있듯이 2단계가 끝나기 전 스파이크를 나타냅니다. 모든 실행기의 데이터 셔플 후에는 실행기 번호 3에서만 읽기 및 쓰기가 진행됩니다.
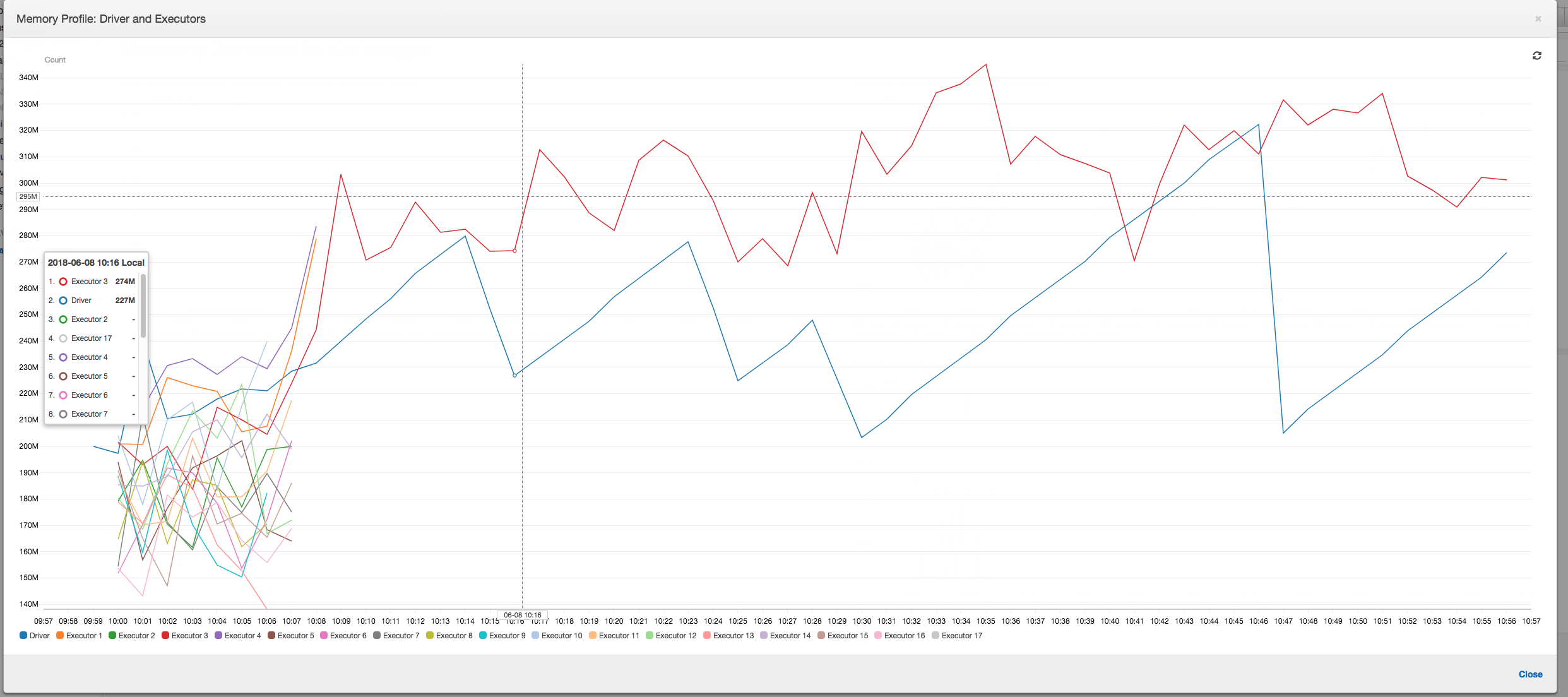
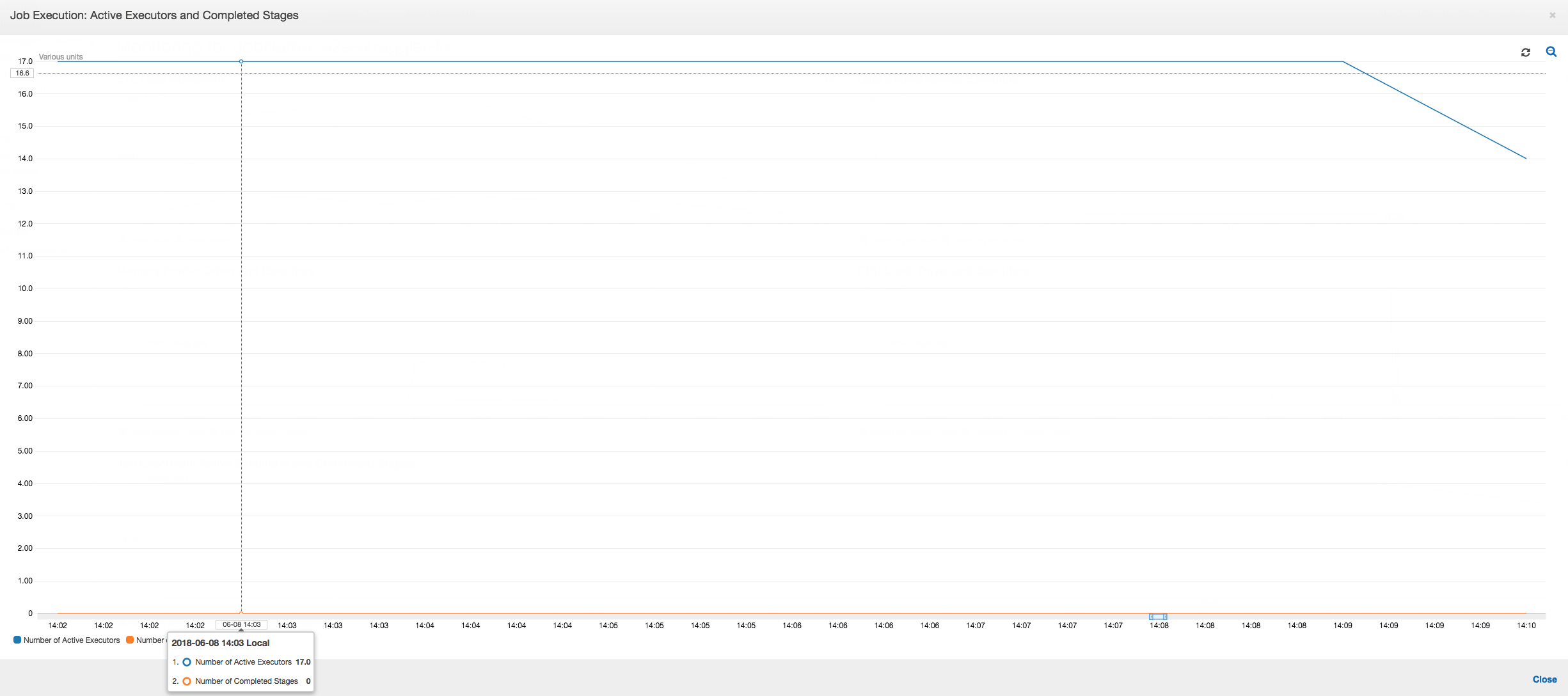
작업 실행: 아래 그래프와 같이, 다른 모든 실행기는 유휴 상태이며 최종적으로 10:09에 중지됩니다. 이 시점에는 총 실행기 수가 1로 감소됩니다. 이는 실행기 번호 3이 실행 시간이 가장 오래 걸리고 작업 실행 시간의 대부분을 차지하는 스트래글러 작업으로 이루어짐을 보여줍니다.

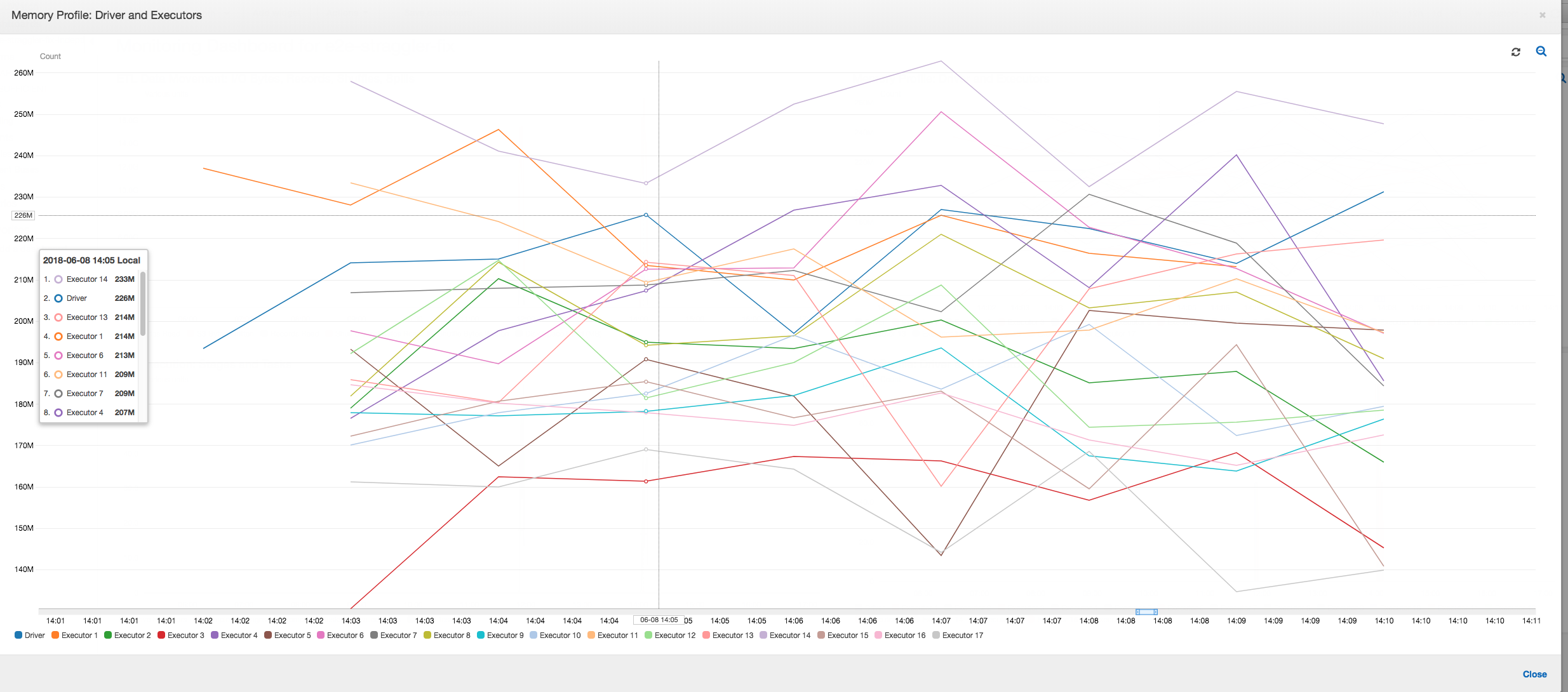
메모리 프로필: 처음 두 단계 이후에는 실행기 번호 3에서 메모리를 적극적으로 소비하며 데이터를 처리합니다. 나머지 실행기는 단순 유휴 상태이거나 처음 두 단계가 완료되고 나서 잠시 후에 중지되었습니다.
그룹화를 사용하여 스트래글링 실행기 수정
AWS Glue의 그룹화 기능을 사용하면 실행기가 뒤처지는 것을 방지할 수 있습니다. 그룹화를 사용하면 데이터를 모든 실행기에 균일하게 분포하고 클러스터의 모든 사용 가능한 실행기를 사용하여 파일을 더 큰 파일로 병합할 수 있습니다. 자세한 내용은 입력 파일을 더 큰 그룹에서 읽기 단원을 참조하십시오.
AWS Glue 작업의 ETL 데이터 이동을 확인하려면 그룹화가 활성화된 상태에서 다음과 같은 코드를 프로파일링합니다.
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
ETL 데이터 이동: 이제 작업 실행 시간 전체에 걸쳐 데이터 쓰기와 데이터 읽기를 병렬로 스트리밍합니다. 따라서 작업이 8분(이전보다 훨씬 빠름) 내에 완료됩니다.
실행기 간의 데이터 셔플: 입력 파일이 그룹화 기능을 사용하여 읽는 동안 병합되므로 데이터를 읽은 후에 비용이 많이 들던 데이터 셔플이 발생하지 않습니다.
작업 실행: 작업 실행 측정치는 데이터 실행 및 처리 중인 총 활성 실행기 수가 상당히 일관되게 유지됨을 보여줍니다. 작업에 단일 스트래글러가 없습니다. 모든 실행기가 활성 상태이며 작업이 완료될 때까지 활성 상태로 유지됩니다. 실행기 간에 중간 데이터 셔플이 없으므로 작업에 단일 단계만 존재합니다.
메모리 프로파일: 이 지표는 모든 실행기의 활성 메모리 소비를 표시하여 모든 실행기에서 활동이 존재함을 재확인합니다. 데이터가 동시에 스트리밍되고 작성되므로, 모든 실행기의 총 메모리 공간이 모든 실행기의 안전 임계값보다 훨씬 낮고 거의 균일합니다.