Apache Spark 웹 UI를 사용하여 작업 모니터링
Apache Spark 웹 UI를 사용하여 AWS Glue 작업 시스템에서 실행 중인 AWS Glue ETL 작업과 AWS Glue 개발 엔드포인트에서 실행 중인 Spark 애플리케이션을 모니터링하고 디버그할 수 있습니다. Spark UI를 사용하면 각 작업에 대해 다음을 확인할 수 있습니다.
-
각 Spark 단계의 이벤트 타임라인
-
작업의 방향성 비순환 그래프(DAG)
-
SparkSQL 쿼리에 대한 물리적, 논리적 계획
-
각 작업에 대한 기본 Spark 환경 변수
Spark 웹 UI 사용에 대한 자세한 내용은 Spark 설명서의 웹 UI
AWS Glue 콘솔에서 Spark UI를 확인할 수 있습니다. 이 기능은 AWS Glue 작업이 AWS Glue 3.0 이상 버전에서 실행되고 새로운 작업의 기본값인 레거시 형식이 아닌 표준 형식으로 생성된 로그가 있는 경우 사용할 수 있습니다. 로그 파일이 0.5GB를 초과하는 경우 AWS Glue 4.0 이상 버전에서 작업 실행에 대한 로그 롤링 지원을 활성화하여 로그 아카이브, 분석 및 문제 해결을 간소화할 수 있습니다.
AWS Glue 콘솔 또는 AWS Command Line Interface(AWS CLI)를 사용하여 Spark UI를 활성화할 수 있습니다. Spark UI를 사용하면 AWS Glue 개발 엔드포인트의 AWS Glue ETL 작업과 Spark 애플리케이션은 Amazon Simple Storage Service(Amazon S3)에서 지정한 위치에 Spark 이벤트 로그를 백업할 수 있습니다. 작업이 작동 중일 때와 완료된 후 모두 실시간으로 Amazon S3에서 Spark UI를 통해 백업된 이벤트 로그를 사용할 수 있습니다. 로그가 Amazon S3에 남아 있는 동안 AWS Glue 콘솔의 Spark UI에서 해당 로그를 볼 수 있습니다.
권한
AWS Glue 콘솔에서 Spark UI를 사용하려면 UseGlueStudio를 사용하거나 모든 개별 서비스 API를 추가할 수 있습니다. Spark UI를 완전히 사용하려면 모든 API가 필요하지만, 사용자는 세분화된 액세스를 위해 IAM 권한에 해당 서비스 API를 추가하여 SparkUI 기능에 액세스할 수 있습니다.
RequestLogParsing은 로그 구문 분석을 수행하므로 가장 중요합니다. 나머지 API는 각각의 구문 분석된 데이터를 읽는 데 사용됩니다. 예를 들어 GetStages는 Spark 작업의 모든 단계에 대한 데이터에 액세스할 수 있습니다.
UseGlueStudio에 매핑된 Spark UI 서비스 API 목록은 아래 샘플 정책에 나와 있습니다. 아래 정책은 Spark UI 기능만 사용할 수 있는 액세스 권한을 제공합니다. Amazon S3 및 IAM과 같은 권한을 더 추가하려면 AWS Glue Studio에 대한 사용자 지정 IAM 정책 만들기를 참조하세요.
UseGlueStudio에 매핑된 Spark UI 서비스 API 목록은 아래 샘플 정책에 나와 있습니다. Spark UI 서비스 API를 사용할 때는 다음 네임스페이스를 사용하세요. glue:<ServiceAPI>
제한 사항
-
AWS Glue 콘솔의 Spark UI는 레거시 로그 형식이므로 2023년 11월 20일 이전에 발생한 작업 실행에는 사용할 수 없습니다.
-
AWS Glue 콘솔의 Spark UI는 스트리밍 작업에서 기본적으로 생성되는 로그와 같이 AWS Glue 4.0에 대한 로그 롤링을 지원합니다. 생성된 모든 롤링된 로그 이벤트 파일의 최대 합계는 2GB입니다. 롤링된 로그를 지원하지 않는 AWS Glue 작업의 경우 SparkUI에 대해 지원되는 최대 로그 이벤트 파일 크기는 0.5GB입니다.
-
VPC에서만 액세스할 수 있는 Amazon S3 버킷에 저장된 Spark 이벤트 로그에 대해서는 서버리스 Spark UI를 사용할 수 없습니다.
예: Apache Spark 웹 UI
이 예제에서는 Spark UI를 사용하여 작업 성과를 이해하는 방법을 보여줍니다. 스크린샷은 자체 관리형 Spark 기록 서버에서 제공하는 Spark 웹 UI를 보여줍니다. AWS Glue 콘솔의 Spark UI에서도 비슷한 화면을 볼 수 있습니다. Spark 웹 UI 사용에 대한 자세한 내용은 Spark 설명서의 웹 UI
다음은 Spark 애플리케이션에서 두 데이터 소스의 데이터를 읽고 조인 변환을 수행하여 Parquet 형식으로 Amazon S3에 쓰는 예제입니다.
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import count, when, expr, col, sum, isnull from pyspark.sql.functions import countDistinct from awsglue.dynamicframe import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME']) df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json") df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json") df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter') df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/") job.commit()
다음 DAG 시각화는 이 Spark 작업의 여러 단계를 보여줍니다.
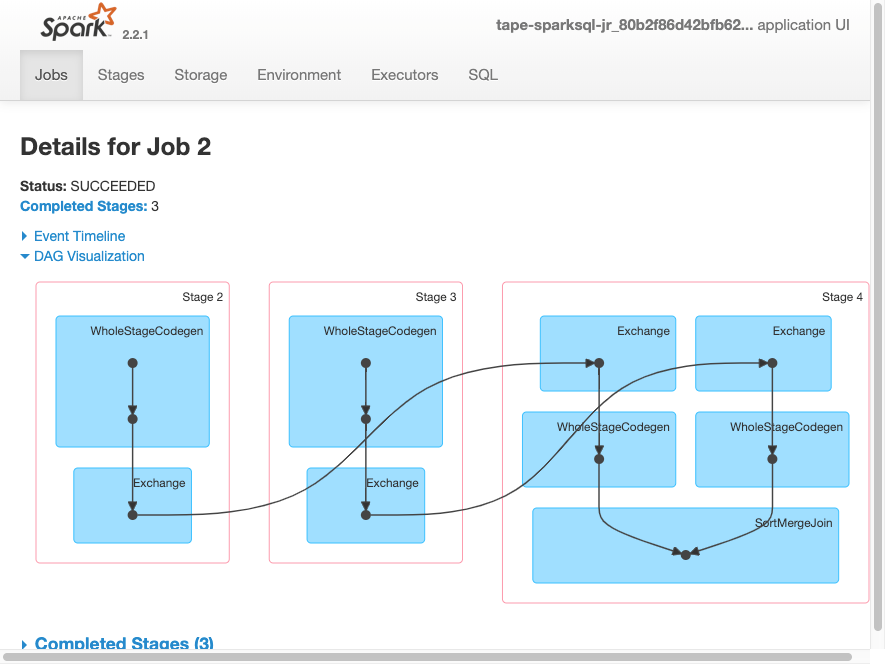
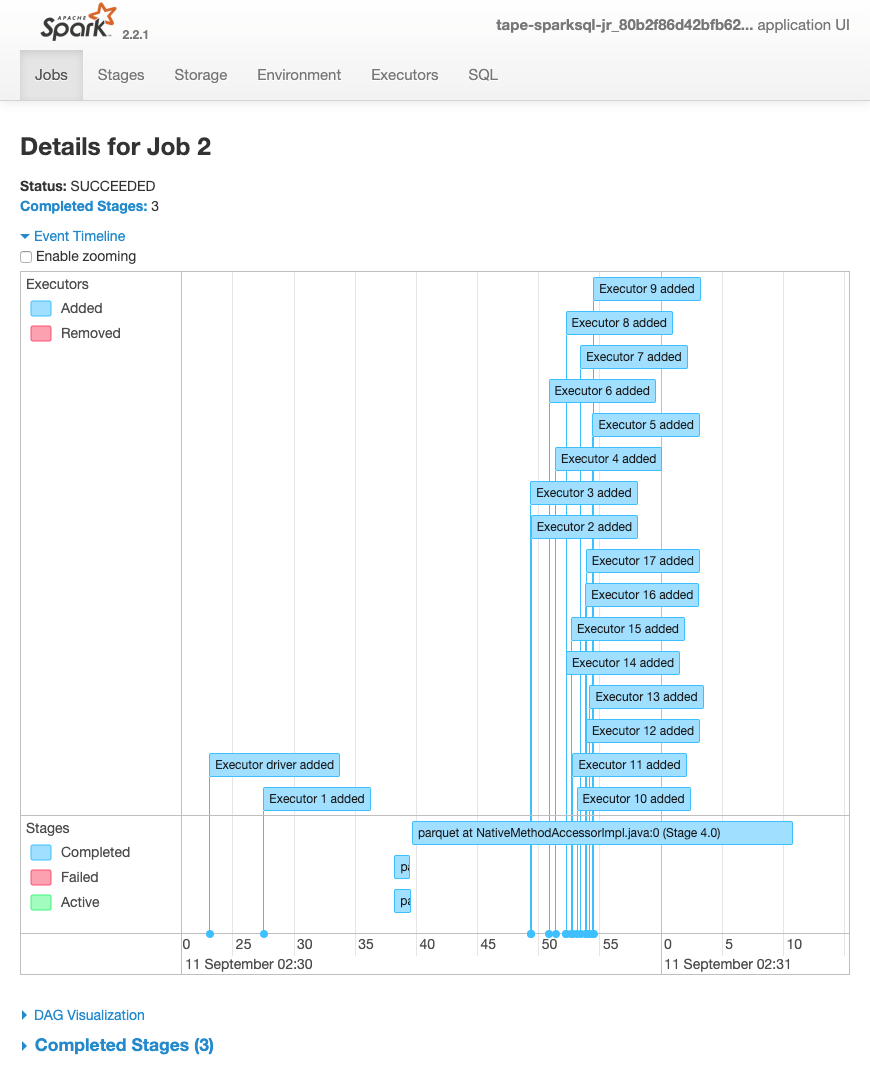
작업에 대한 다음 이벤트 타임라인은 다양한 Spark 실행기의 시작, 실행 및 종료를 보여줍니다.
다음 화면은 SparkSQL 쿼리 계획의 세부 정보를 보여줍니다.
-
구문 분석된 논리적 계획
-
분석된 논리적 계획
-
최적화된 논리적 계획
-
실행할 물리적 계획

