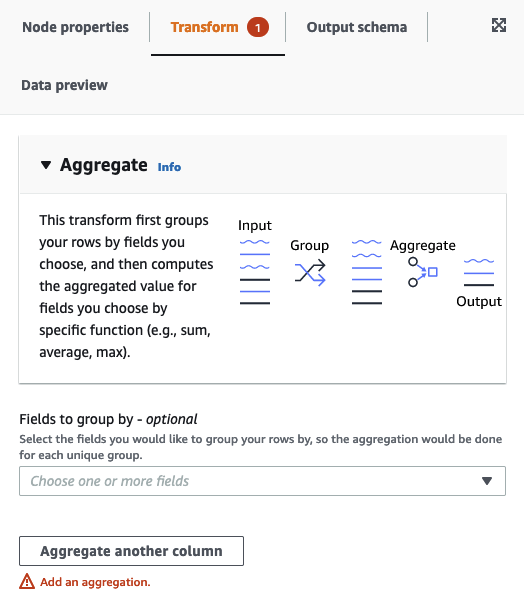
집계를 사용하여 선택한 필드에서 요약 계산 수행
집계(Aggregate) 변환을 사용하려면
-
작업 다이어그램에 집계(Aggregate) 노드를 추가합니다.
-
노드 속성(Node properties) 탭에서 드롭다운 필드를 선택하여 그룹화할 필드를 선택합니다(선택 사항). 한 번에 둘 이상의 필드를 선택하거나 검색 창에 입력하여 필드 이름을 검색할 수 있습니다.
필드를 선택하면 이름과 데이터 유형이 표시됩니다. 필드를 제거하려면 필드에서 'X'를 선택합니다.
-
다른 열 집계(Aggregate another column)를 선택합니다. 하나 이상의 필드를 선택해야 합니다.
-
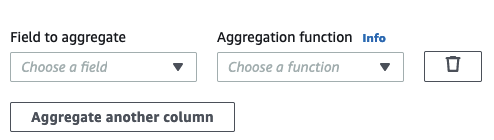
집계할 필드(Field to aggregate) 드롭다운에서 필드를 선택합니다.
-
선택한 필드에 적용할 집계 함수를 선택합니다.
-
avg - 평균을 계산합니다.
-
countDistinct - Null이 아닌 고유 값 수를 계산합니다.
-
count - Null이 아닌 값 수를 계산합니다.
-
first - 'group by' 기준을 충족하는 첫 번째 값을 반환합니다.
-
last - 'group by' 기준을 충족하는 마지막 값을 반환합니다.
-
kurtosis - 빈도 분포 곡선의 정점 첨도를 계산합니다.
-
max - 'group by' 기준을 충족하는 최대값을 반환합니다.
-
min - 'group by' 기준을 충족하는 최소값을 반환합니다.
-
skewness - 정규 분포의 확률 분포 비대칭 측정값입니다.
-
stddev_pop - 모집단 표준 편차를 계산하고 모집단 분산의 제곱근을 반환합니다.
-
sum - 그룹에 있는 모든 값의 합계입니다.
-
sumDistinct - 그룹에 있는 고유 값의 합계입니다.
-
var_samp - 그룹의 표본 분산입니다(Null 무시).
-
var_pop - 그룹의 모집단 분산입니다(Null 무시).
-
